The creation of Large Language Models (LLMs) began in 2018. Three factors emerged and were combined in LLMs: powerful computer and graphics processing units, huge amounts of structured and unstructured data that could be processed fast, and first-grade open-source project for the creation and training of neural networks.
Large Language Models (LLMs) are a ubiquities technology enabling humans to use their natural language for interacting with a computer in a broad range of tasks. LLMs can answer questions about history and real-world events, they can create step-by-step tasks plans, solve mathematical questions, and can reflect on any input text to create summaries or identify text characteristics. Using most recent LLMs like GPT4 is a fascinating and surprising event.
The Raspberry Pico Badger is a consumer product by the Raspberry Pi company Pimoroni. Advertised as a portable badge with a 2.9 inch e-ink display and a Pico W, it’s a portable, programmable, network connected microcomputer.
The Raspberry Pico Badger is a consumer product by the Raspberry Pi company Pimorino. Advertised as a portable badge with a 2.9 inch e-ink display and a Pico W, its a portable, programmable microcomputer. This article investigates this unique product from its hardware side as well as the software, apptly named Badger OS.
The ESP32 Camera is an ESP32 board nano board with a fixed component, its name giving camera. It has a very compact form factor, and although some pins are directly used for the camera, you still get 10 GPIO pins for connectivity to other sensors.
The Arduino Nano BLE 33 Sense Microcontroller is an Arduino-compatible board with a fleet of onboard sensors, including sound, light, temperature, and a microphone. It can be programmed with Arduino C and MicroPython to read and write data. This article introduces this unique board, details how to use the digital and analog pins and which functions the board supports.
The Tinker Board is a Single Board Computer from Asus. Its form factor, number of GPIO Pins, and general hardware capabilities resemble those of the Raspberry Pi. An important difference is the ARM Mali T764 GPU that contains Tensor Units tailored towards running Machine Learning applications.
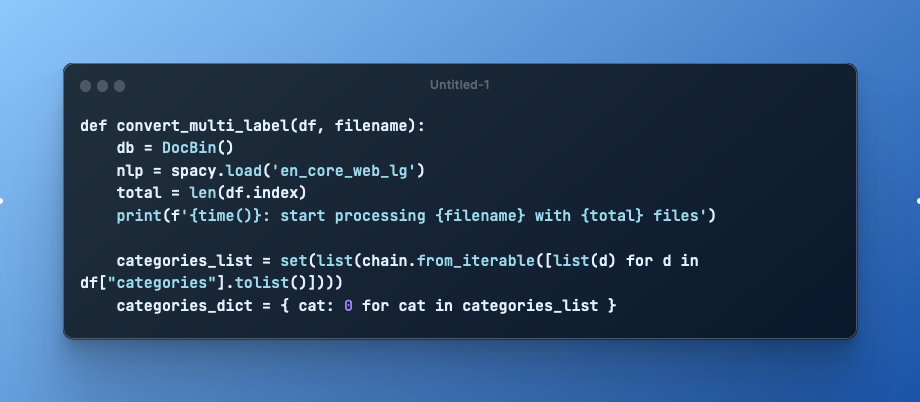
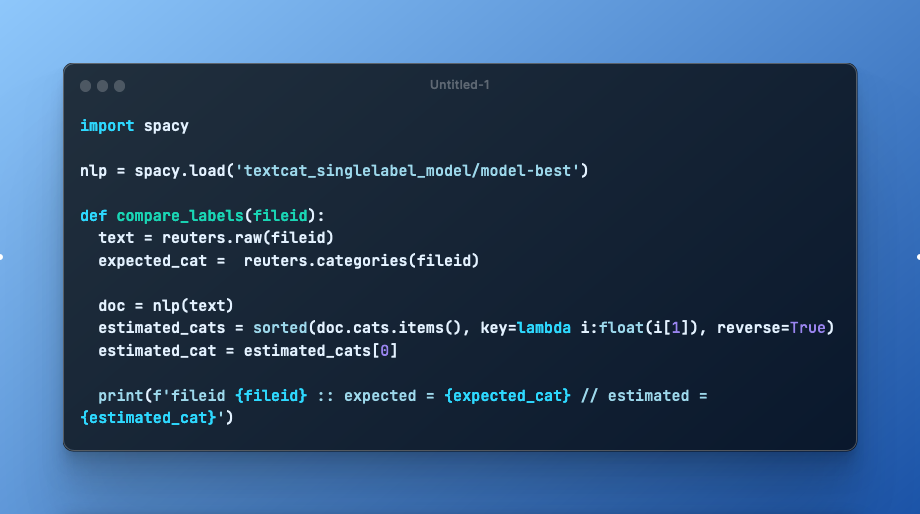
Spacy is a powerful NLP library that performs many NLP tasks in its default configuration, including tokenization, stemming and part-of-speech tagging. These steps can be extended with a text classification task as well, in which training data in the form of preprocessed text and expected categories as dictionary objects are provided. Both multi-label and single-label classification is supported.
Spacy is a powerful NLP library in which many NLP tasks like tokenization, stemming, part-of-speech tagging and named entity resolution are provided out-of-the box with pretrained models. All of these tasks are wrapped by a pipeline object, and internal abstraction of different functions that are applied step by step on a given text. This pipeline can be both customized and extended with self-written functions.
Wikipedia is a rich source of information and knowledge. Conveniently structured into articles with categories and links to other articles, it also forms a network of related documents. My NLP project downloads, processes, and applies machine learning algorithms on Wikipedia articles.