Spacy is a powerful NLP library in which many NLP tasks like tokenization, stemming, part-of-speech tagging and named entity resolution are provided out-of-the box with pretrained models. All of these tasks are wrapped by a pipeline object, and internal abstraction of different functions that are applied step by step on a given text. This pipeline can be both customized and extended with self-written functions.
In this article, you will learn how to add text classification to a Spacy pipeline. Given training data with documents and labels, an additional classification task can learn to predict labels for other documents. You will see how to structure the training data, how to extend the default pipeline with a classification step, and how to add your own implementation of this classification.
The technical context of this article is Python v3.11 and spacy v3.7.2. All examples should work with newer library versions too.
Customizing Spacy Pipeline Example
Note: All of the following explanations and code snippets are the combination of three sources: The official Rasa API documentation, a blog article about Text Classification with Spacy 3.0, and a blog article about Building Production-Grade Spacy Text Classification.
Adding a text classification task boils down to these steps:
- Prepare the training data
- Convert the training data to a Spacy DocBin Object
- Create a default text categorization configuration
- Train the model
- Use the model
The following sections detail these steps.
Step 1: Prepare the training data
The training data needs to be raw text and their single- or multilabel categories. Let’s make this practical by using the Reuters News dataset included with the NLTK library.
Following snippet shows how to load the dataset, then print a text and its category.
from nltk.corpus import reuters
print(len(reuters.fileids()))
# 10788
print(reuters.raw(reuters.fileids()[42]))
# JAPAN GIVEN LITTLE HOPE OF AVOIDING U.S. SANCTIONS
# A top U.S. Official said Japan has little
# chance of persuading the U.S. to drop threatened trade
# sanctions, despite the efforts of a Japanese team that left for
# Washington today.
print(reuters.categories(reuters.fileids()[42]))
# ['trade']
This dataset has a total of 90 categories. Furthermore, some articles have multiple labels.
print(len(reuters.categories()))
# 90
print(reuters.categories())
# ['acq', 'alum', 'barley', 'bop', 'carcass', 'castor-oil', 'cocoa', 'coconut', 'coconut-oil', 'coffee', 'copper', 'copra-cake', 'corn', 'cotton', 'cotton-oil', 'cpi', 'cpu', 'crude', 'dfl', 'dlr', 'dmk', 'earn', 'fuel', 'gas', 'gnp', 'gold', 'grain', 'groundnut', 'groundnut-oil', 'heat', 'hog', 'housing', 'income', 'instal-debt', 'interest', 'ipi', 'iron-steel', 'jet', 'jobs', 'l-cattle', 'lead', 'lei', 'lin-oil', 'livestock', 'lumber', 'meal-feed', 'money-fx', 'money-supply', 'naphtha', 'nat-gas', 'nickel', 'nkr', 'nzdlr', 'oat', 'oilseed', 'orange', 'palladium', 'palm-oil', 'palmkernel', 'pet-chem', 'platinum', 'potato', 'propane', 'rand', 'rape-oil', 'rapeseed', 'reserves', 'retail', 'rice', 'rubber', 'rye', 'ship', 'silver', 'sorghum', 'soy-meal', 'soy-oil', 'soybean', 'strategic-metal', 'sugar', 'sun-meal', 'sun-oil', 'sunseed', 'tea', 'tin', 'trade', 'veg-oil', 'wheat', 'wpi', 'yen', 'zinc']
Step 2: Convert the training data to a Spacy DocBin Object
Spacy requires its input datasets to be preprocess Doc objects with an additional cats attribute. The categories should be a dict object in which the keys are the categories, and the values reflect if this category applies to the article. which is an integer value.
Here is an example of how to convert the first article of the Reuters news dataset:
nlp = spacy.load('en_core_web_lg')
fileid = reuters.fileids()[42]
cat_dict = {cat: 0 for cat in reuters.categories()}
doc1 = nlp.make_doc(reuters.raw(fileid))
for cat in reuters.categories(fileid):
cat_dict[cat] = 1
doc1.cats = cat_dict
print(doc1.cats)
# {'acq': 0, 'alum': 0, 'barley': 0, 'bop': 0, ..., 'trade': 1, ...}
In addition, the data need to be converted to the Spacy custom data object DocBin. Anticipating that the data needs to be split into training and testing, the following methods creates a multilabel classification in which doc objects process the raw text of each article, and contain dict object of all applicable categories.
def convert_multi_label(dataset, filename):
db = DocBin()
nlp = spacy.load('en_core_web_lg')
total = len(dataset)
print(f'{time()}: start processing {filename} with {total} files')
for index, fileid in enumerate(dataset):
print(f'Processing {index+1}/{total}')
cat_dict = {cat: 0 for cat in reuters.categories()}
for cat in reuters.categories(fileid):
cat_dict[cat] = 1
doc = nlp(get_text(fileid))
doc.cats = cat_dict
db.add(doc)
print(f'{time()}: finish processing {filename}')
db.to_disk(filename)
#convert(training, 'reuters_training.spacy')
convert_multi_label(training, 'reuters_training_multi_label.spacy')
# 1688400699.331844: start processing reuters_training_single_label.spacy with 7769 files
# Processing 1/7769
# Processing 2/7769
# ...
A preview of the binary file:

Step 3: Create a default text categorization configuration
Spacy provides a handy command-line interface to create default configuration files for several purposes. Starting with spacy init config, additional pipeline steps can be added. For classification, the two possible values are textcat for single label, and textcat_multilabel for multi label classification. Furthermore, by including the option --optimize accuracy, the training process will use word vectors from a pretrained model to represent the text.
These considerations result in the following command:
> python -m spacy init config --pipeline textcat_multilabel --optimize accuracy spacy_categorization_pipeline.cfg
2023-07-02 13:26:37.103543: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
ℹ Generated config template specific for your use case
- Language: en
- Pipeline: textcat
- Optimize for: efficiency
- Hardware: CPU
- Transformer: None
✔ Auto-filled config with all values
✔ Saved config
spacy_categorization_pipeline.cfg
You can now add your data and train your pipeline:
python -m spacy train spacy_categorization_pipeline.cfg --paths.train ./train.spacy --paths.dev ./dev.spacy
Let’s take a look at some part of this file:
[paths]
train = null
dev = null
vectors = "en_core_web_lg"
init_tok2vec = null
#...
[nlp]
lang = "en"
pipeline = ["tok2vec","textcat_multilabel"]
batch_size = 1000
disabled = []
before_creation = null
after_creation = null
after_pipeline_creation = null
tokenizer = {"@tokenizers":"spacy.Tokenizer.v1"}
[components]
[components.textcat_multilabel]
factory = "textcat_multilabel"
scorer = {"@scorers":"spacy.textcat_multilabel_scorer.v2"}
threshold = 0.5
[components.textcat_multilabel.model]
@architectures = "spacy.TextCatEnsemble.v2"
nO = null
[components.textcat_multilabel.model.tok2vec]
@architectures = "spacy.Tok2VecListener.v1"
width = ${components.tok2vec.model.encode.width}
upstream = "*"
[components.tok2vec]
factory = "tok2vec"
[components.tok2vec.model]
@architectures = "spacy.Tok2Vec.v2"
#...
[training]
dev_corpus = "corpora.dev"
train_corpus = "corpora.train"
seed = ${system.seed}
gpu_allocator = ${system.gpu_allocator}
dropout = 0.1
accumulate_gradient = 1
patience = 1600
max_epochs = 0
max_steps = 20000
eval_frequency = 200
frozen_components = []
annotating_components = []
before_to_disk = null
before_update = null
#...
[training.logger]
@loggers = "spacy.ConsoleLogger.v1"
progress_bar = false
[training.optimizer]
@optimizers = "Adam.v1"
beta1 = 0.9
beta2 = 0.999
L2_is_weight_decay = true
L2 = 0.01
grad_clip = 1.0
use_averages = false
eps = 0.00000001
learn_rate = 0.001
This configuration exposes all training-relevant parameters, starting from input files containing the training and test data, the used corpora, logging and batch separation of data, and the training algorithms with its optimizer and learning rate. A detailed discussion of all options is out of scope for this article - for now, all the defaults stay as they are.
Step 4: Train the model
First of all, the data needs to be split into a training and test dataset. Conveniently, the Reuters articles are pre-split already. Following snippet divides the data and shows an example article and its category from the training data.
training = [doc for doc in reuters.fileids() if doc.find('training') == 0]
testing = [doc for doc in reuters.fileids() if doc.find('test') == 0]
print(len(training))
# 7769
print(len(testing))
# 3019
The training process is again started via the command line. It needs to be passed the name of the configuration file, the training and testing dataset filenames, and an output directory. Here is an example:
run python -m spacy train spacy_multi_label_categorization_pipeline.cfg \
--paths.train reuters_training_multi_label.spacy \
--paths.dev reuters_testing_multi_label.spacy \
--output textcat_multilabel_model
The output log shows the progress …
=========================== Initializing pipeline ===========================
[2023-07-03 18:24:10,639] [INFO] Set up nlp object from config
[2023-07-03 18:24:10,656] [INFO] Pipeline: ['tok2vec', 'textcat_multilabel']
[2023-07-03 18:24:10,660] [INFO] Created vocabulary
[2023-07-03 18:24:12,365] [INFO] Added vectors: en_core_web_lg
[2023-07-03 18:24:12,365] [INFO] Finished initializing nlp object
[2023-07-03 18:24:31,806] [INFO] Initialized pipeline components: ['tok2vec', 'textcat_multilabel']
✔ Initialized pipeline
============================= Training pipeline =============================
ℹ Pipeline: ['tok2vec', 'textcat_multilabel']
ℹ Initial learn rate: 0.001
# ...
✔ Saved pipeline to output directory
textcat_multilabel_model/model-last
… and a table that shows the training process and several metrics.
E # LOSS TOK2VEC LOSS TEXTC... CATS_SCORE SCORE
--- ------ ------------ ------------- ---------- ------
0 0 2.51 0.39 48.98 0.49
0 200 24.56 5.04 39.44 0.39
0 400 0.00 2.86 39.94 0.40
0 600 0.01 3.87 40.27 0.40
0 800 1.02 3.39 46.44 0.46
0 1000 0.00 3.60 46.68 0.47
0 1200 0.00 3.69 45.55 0.46
0 1400 0.00 3.79 45.18 0.45
0 1600 0.00 3.80 45.04 0.45
This table contains the following info:
E: Number of epochs the training runs#: The number of training stepsLOSS TOK2VEC: The loose function for vectorizing the input dataLOSS TEXTCATandSCORE: The loss function for the categorization, and its normalized value.
Step 5: Use the model
During the training process, created models are stored inside the given folder name. Spacy keeps both a latest and the best model, which is the model with the highest F1 score. To use these models, you directly load them with Spacy, then process any text and derive the calculated categories.
Here is an example for the same article as used above:
import spacy
nlp = spacy.load('textcat_multilabel_model/model-best')
fileid = reuters.fileids()[1024]
text = reuters.raw(fileid)
doc = nlp(text)
print(doc.cats)
# {'acq': 0.9506559371948242, 'alum': 0.3440687954425812, 'barley': 0.044086653739213943, #...
The doc.cats attribute is a Dictionary object that contains key-value mappings of probabilities, where the most probable category is the estimated label.
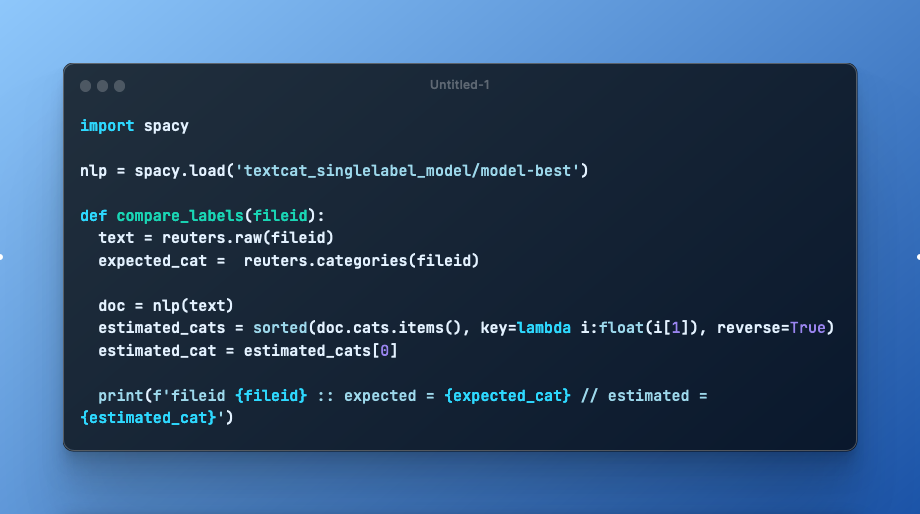
Let’s compare the expected and estimated tags for some articles using the single label model:
import spacy
nlp = spacy.load('textcat_singlelabel_model/model-best')
def compare_labels(fileid):
text = reuters.raw(fileid)
expected_cat = reuters.categories(fileid)
doc = nlp(text)
estimated_cats = sorted(doc.cats.items(), key=lambda i:float(i[1]), reverse=True)
estimated_cat = estimated_cats[0]
print(f'fileid {fileid} :: expected = {expected_cat} // estimated = {estimated_cat}')
compare_labels(training[1024])
# fileid training/1158 :: expected = ['ipi'] // estimated = ('cpi', 0.39067542552948)
compare_labels(training[2678])
# fileid training/2080 :: expected = ['acq'] // estimated = ('acq', 0.9778384566307068)
compare_labels(testing[1024])
# fileid test/16630 :: expected = ['orange'] // estimated = ('orange', 0.40097832679748535)
compare_labels(testing[2678])
# fileid test/20972 :: expected = ['earn'] // estimated = ('earn', 0.9994577765464783)
As you see, in three cases, the estimated category matches.
Compare Multi-Label and Single-Label Categorization Training
To give you an impression about the training process, let’s compare the multi-label and single-label categorization process.
Multilabel Categorization
The baseline multi-label categorization for the complete training set of 7769 entries requires about 30 minutes.
Here is the log output:
=========================== Initializing pipeline ===========================
[2023-07-03 18:24:10,639] [INFO] Set up nlp object from config
[2023-07-03 18:24:10,656] [INFO] Pipeline: ['tok2vec', 'textcat_multilabel']
[2023-07-03 18:24:10,660] [INFO] Created vocabulary
[2023-07-03 18:24:12,365] [INFO] Added vectors: en_core_web_lg
[2023-07-03 18:24:12,365] [INFO] Finished initializing nlp object
[2023-07-03 18:24:31,806] [INFO] Initialized pipeline components: ['tok2vec', 'textcat_multilabel']
✔ Initialized pipeline
============================= Training pipeline =============================
ℹ Pipeline: ['tok2vec', 'textcat_multilabel']
ℹ Initial learn rate: 0.001
E # LOSS TOK2VEC LOSS TEXTC... CATS_SCORE SCORE
--- ------ ------------ ------------- ---------- ------
0 0 2.51 0.39 48.98 0.49
0 200 24.56 5.04 39.44 0.39
0 400 0.00 2.86 39.94 0.40
0 600 0.01 3.87 40.27 0.40
0 800 1.02 3.39 46.44 0.46
0 1000 0.00 3.60 46.68 0.47
0 1200 0.00 3.69 45.55 0.46
0 1400 0.00 3.79 45.18 0.45
0 1600 0.00 3.80 45.04 0.45
✔ Saved pipeline to output directory
textcat_multilabel_model/model-last
Single-Label Categorization
The baseline single label categorization for the complete training set of 7769 entries requires more than 3h30m. Both the training steps themselves are slower, and the training continues for several epochs because the F1 score increases very slowly.
To use single category labels, we first need to change the method that provides the training and testing data. From all categories associated with an article, only the first will be used:
def convert_single_label(dataset, filename):
db = DocBin()
# ...
for index, fileid in enumerate(dataset):
cat_dict = {cat: 0 for cat in reuters.categories()}
cat_dict[reuters.categories(fileid).pop()] = 1
# ...
For the training run, a special single label configuration file is used.
python -m spacy train spacy_single_label_categorization_pipeline.cfg \
--paths.train reuters_training_single_label.spacy \
--paths.dev reuters_testing_single_label.spacy \
--output textcat_singlelabel_model
Here are the results of the training:
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
✔ Created output directory: textcat_singlelabel_model
ℹ Saving to output directory: textcat_singlelabel_model
ℹ Using CPU
=========================== Initializing pipeline ===========================
[2023-07-04 16:38:34,515] [INFO] Set up nlp object from config
[2023-07-04 16:38:34,529] [INFO] Pipeline: ['tok2vec', 'textcat']
[2023-07-04 16:38:34,532] [INFO] Created vocabulary
[2023-07-04 16:38:37,277] [INFO] Added vectors: en_core_web_lg
[2023-07-04 16:38:37,278] [INFO] Finished initializing nlp object
[2023-07-04 16:39:02,505] [INFO] Initialized pipeline components: ['tok2vec', 'textcat']
✔ Initialized pipeline
============================= Training pipeline =============================
ℹ Pipeline: ['tok2vec', 'textcat']
ℹ Initial learn rate: 0.001
E # LOSS TOK2VEC LOSS TEXTCAT CATS_SCORE SCORE
--- ------ ------------ ------------ ---------- ------
0 0 0.00 0.01 0.09 0.00
0 200 31.16 2.00 1.29 0.01
0 400 34.35 1.92 1.51 0.02
0 600 41.41 1.76 2.27 0.02
0 800 56.29 1.76 2.12 0.02
0 1000 124.84 1.73 2.07 0.02
0 1200 45.42 1.75 2.42 0.02
0 1400 58.10 1.51 3.93 0.04
0 1600 90.27 1.51 2.10 0.02
0 1800 93.87 1.57 3.22 0.03
0 2000 172.70 1.48 3.64 0.04
0 2200 215.72 1.42 4.30 0.04
0 2400 177.34 1.30 4.72 0.05
0 2600 866.50 1.22 5.47 0.05
0 2800 1877.17 1.16 5.09 0.05
0 3000 4186.50 1.02 6.94 0.07
1 3200 4118.06 1.05 5.33 0.05
1 3400 6050.67 0.96 8.27 0.08
1 3600 7368.26 0.82 6.07 0.06
1 3800 9302.68 1.03 8.25 0.08
1 4000 12089.54 0.98 7.82 0.08
1 4200 10829.92 0.99 6.49 0.06
1 4400 10462.12 0.91 7.15 0.07
2 4600 13104.09 0.96 9.11 0.09
2 4800 14439.08 0.87 10.31 0.10
2 5000 12240.43 0.86 9.27 0.09
Although training takes much longer, the estimated categories match the expected categories better.
Conclusion
This article showed how to add a text classification task to a Spacy project. With a default model, Spacy performs several basic and advanced NLP tasks like tokenization, lemmatization, part-of-speech tagging and named entity resolution. To add text classification, these steps are required: a) prepare the training data, b) transform the training data to the DocBin format such that pre-processed Doc objects with a dictionary attribute cats are provided c) generate and customize a Spacy training configuration, d) train a model using cli commands. Thereby, especially the training configuration is customizable to a high degree, exposing details such as the learning rate and the loss function. When training is finished, the resulting model can be loaded via Spacy, and all parsed documents will now have an estimated category.