Large Language Models are vast neural networks trained on billions of text token. They can work with natural language in a never-before-seen way, reflecting a context to give precise answers.
Large Language Models are vast neural networks trained on billions of text token. They can work with natural language in a never-before-seen way, reflecting a context to give precise answers.
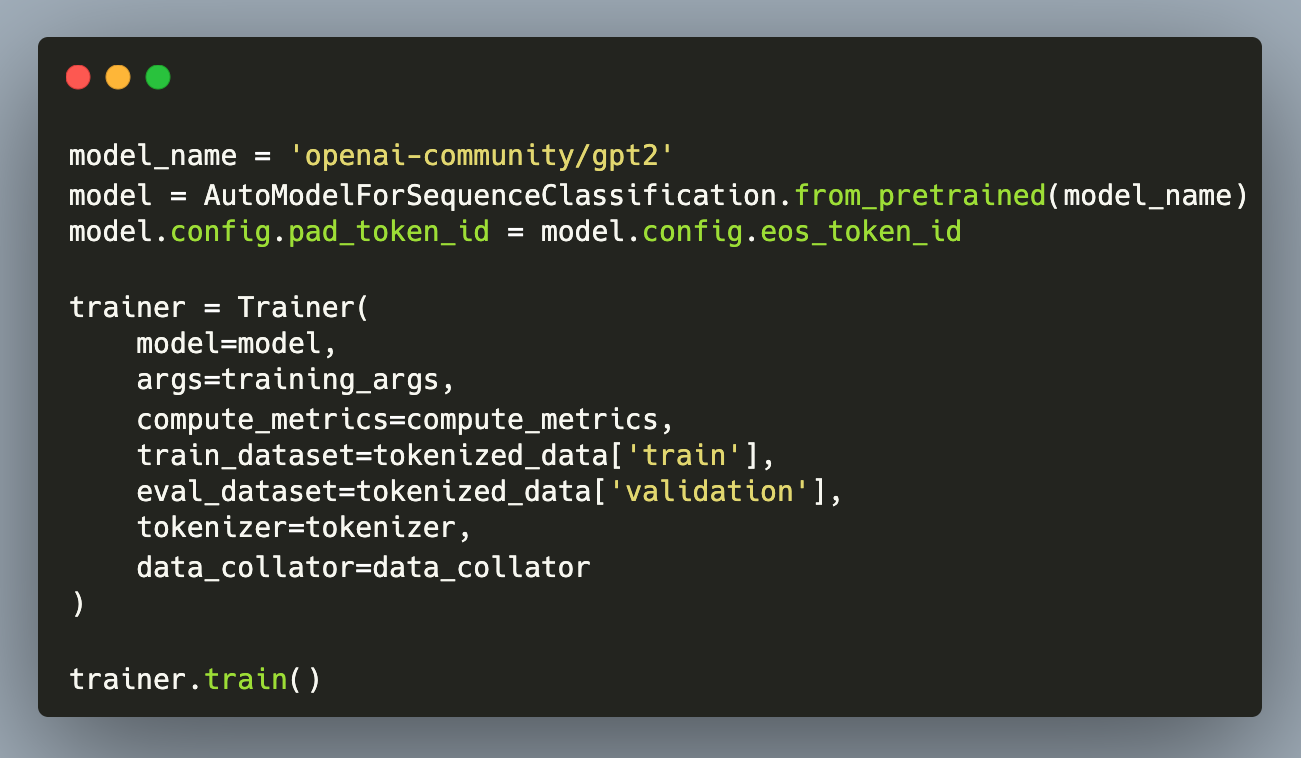
Large Language Models have fascinating abilities to understand and output natural language texts. From knowledge databases to assistants and live chatbots, many applications can be build with an LLM as a component. The capability of an LLM to follow instructions is essential for these use cases. While closed-source LLMs handle instructions very good, pretrained open-source model may not have the skill to follow instructions rigorously. To alleviate this, instruction fine-tuning can be utilized.
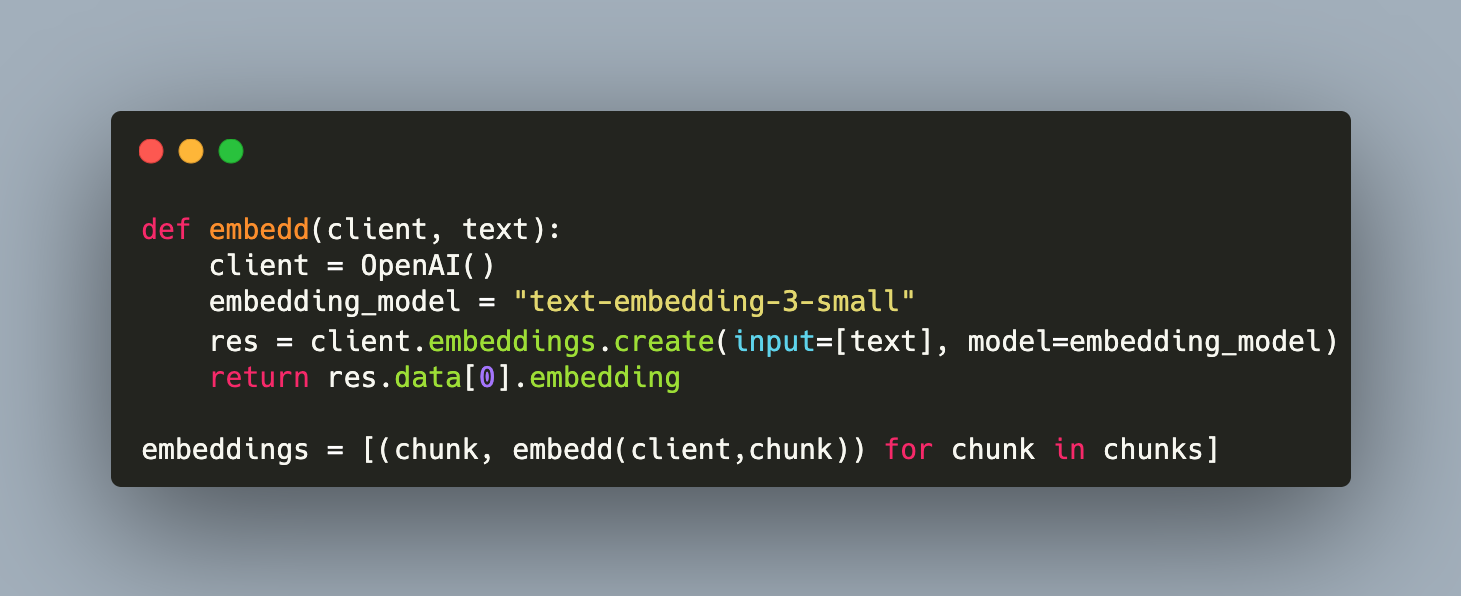
Starting in 2023, Large Language Models evolved to form or be a component of information retrieval systems. In such a system, domain knowledge is encoded in a special format. Then, given a user query, the most relevant chunks from the knowledge base are determined and an answer is formulated. In LLMs, the knowledge base is all learned training material. However, given the learned vector representations of words, other content can be embedded in the same vector space. And in this vector space, similarity search between user queries and stored knowledge can be made to identify the context from which an LLM answers. This is a LLM retrieval system in a nutshell.
Large Language Models are a fascinating technology that becomes embedded into several applications and products. In my blog series about LLMs, I stated the goal to design a closed-book question answering systems with LLMs as the core or sole components. Following my overview to [question answer system architecture](https://admantium.com/blog/llm13_question_answer_system_architectures/), this is the second article, and its focus is to add question-answering skills to a Gen1 LLM.
Large Language Models are a fascinating technology capable of many classic and advanced NLP tasks, from text-classification and sentiment analysis to reading comprehension and logical interference. During their evolution, starting with Gen1 in 2018 with model like GPT and Bert, to Gen4 2024 models like GPT-4 and LLAmA2, they have gained significant skills and capabilities.
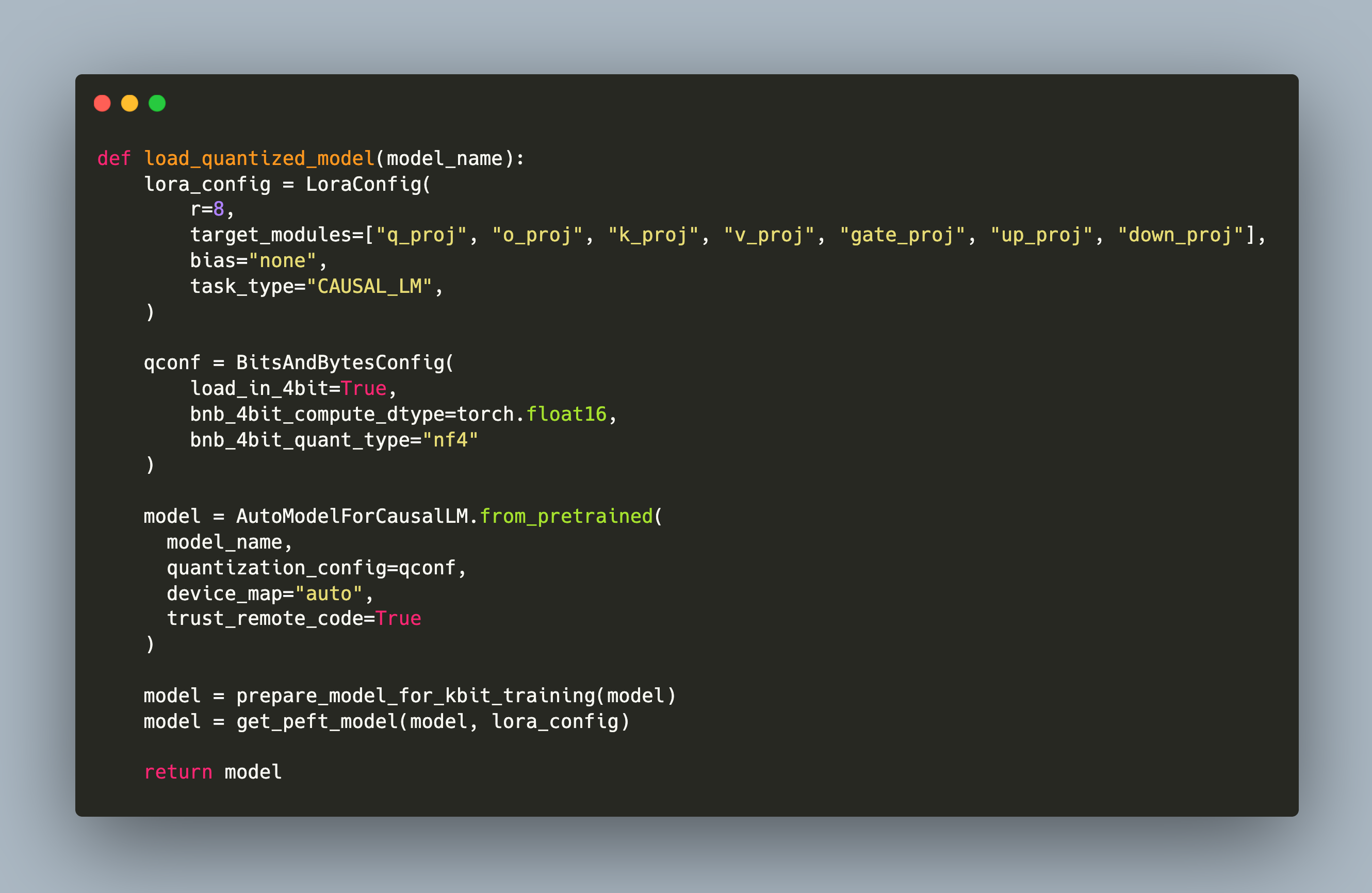
LLMs are ubiquitous tools used for the processing and producing of natural language texts. Since its inception in 2018, several generations of LLMs continuously pushed the frontier of LLM capabilities. Today’s LLMs such as LLaMA 2 and GPT-4 are universally applicable to all classical NLP tasks, but this is not the case for the early models of 2018. These gen1 LLMs are around 150M parameters strong. They are typically trained in the Toronto Book Corpus and Wikipedia Text, with the goal to optimize the prediction of a word given its context of previous and following word. While the model architectures differ, e.g. number of attention heads and hidden dimensions, the resulting models need to be finetuned for any downstream NLP task.
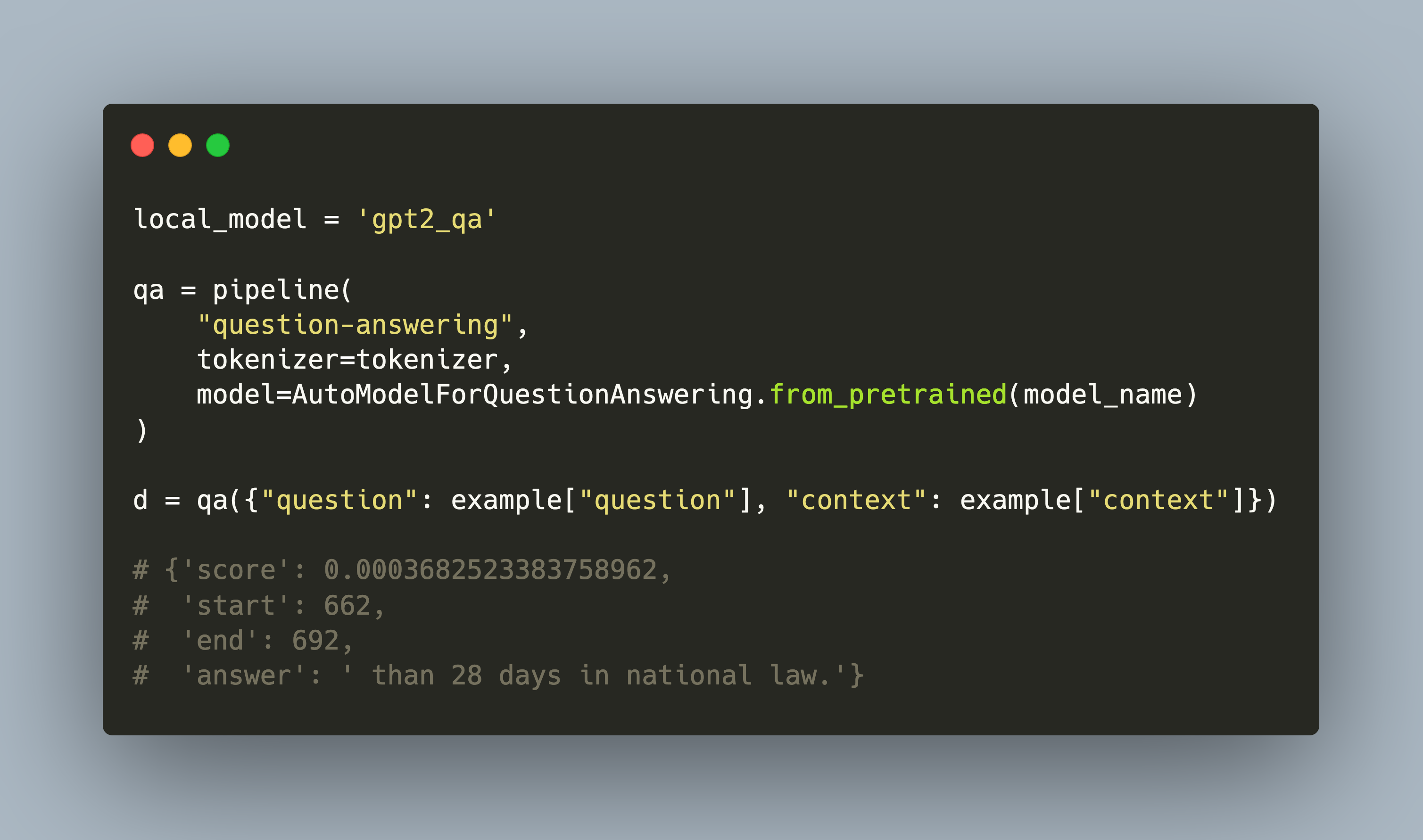
Not long ago, question answering systems were built as complex information storage and retrieval systems. The first component processes text sources, extracts their verbatim meaning as well as specific information. Then another component extracts knowledge from these sources and represents the facts in a database or a graph datastructure. And finally, the retriever parses a user query, determines relevant parts of the processed text and its knowledge databases, and then composes a natural language answer.
For a very long time, I have been reading several articles, some papers, and lots of blog post about artificial intelligence and machine learning. The recent advances in neural networks were especially fascinating, such as the GPT3.5 model which produces human-level like texts. In order to understand the state of the art in natural language processing using neural networks, I want to design a question-answer system that parses, understands, and answers a question about a specific topic, for example the content of a book. With this far-reaching goal in mind, I started this blog series to cover all relevant knowledge and engineering areas: machine learning, natural language processing, expert systems, and neuronal networks.