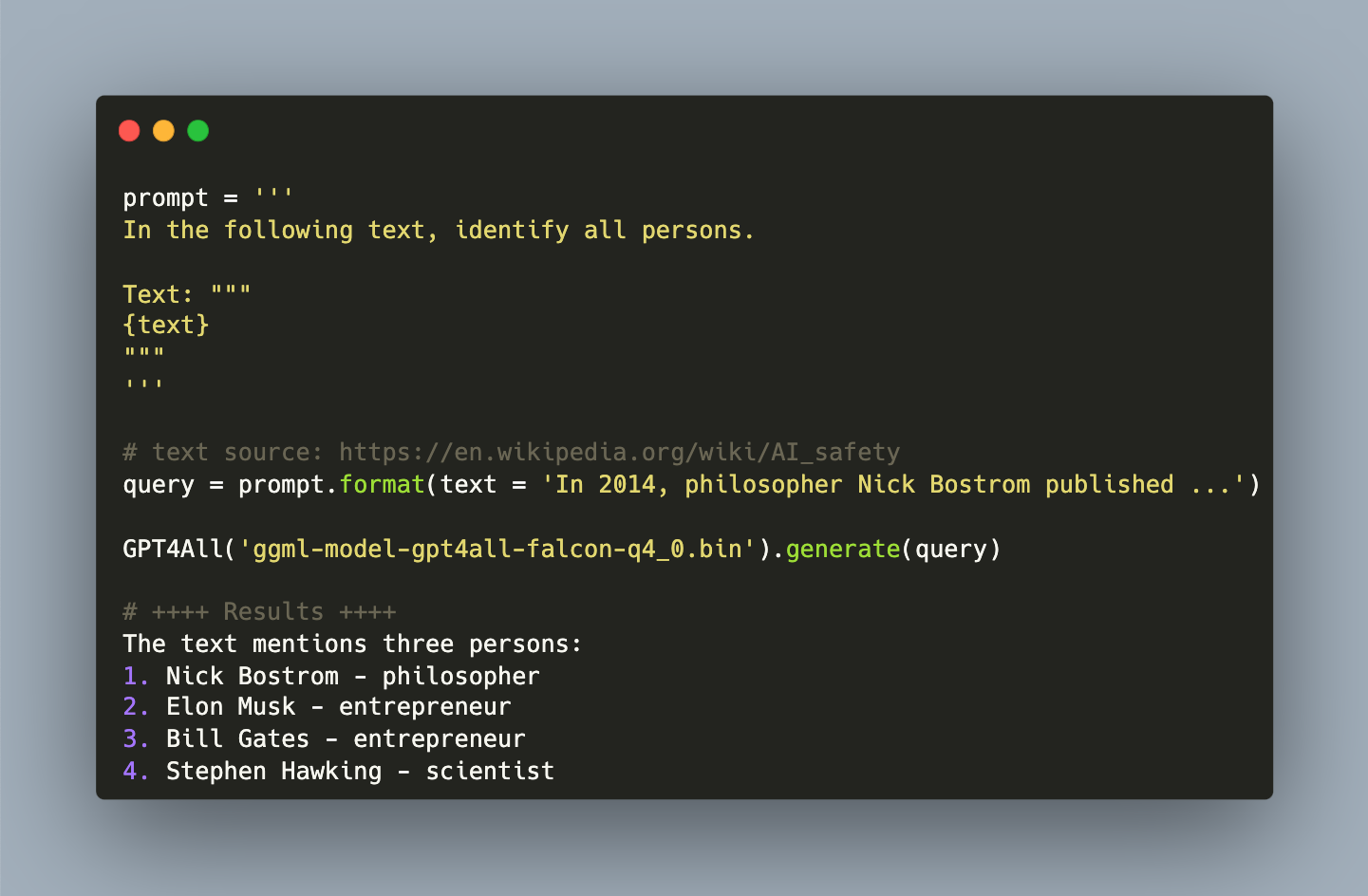
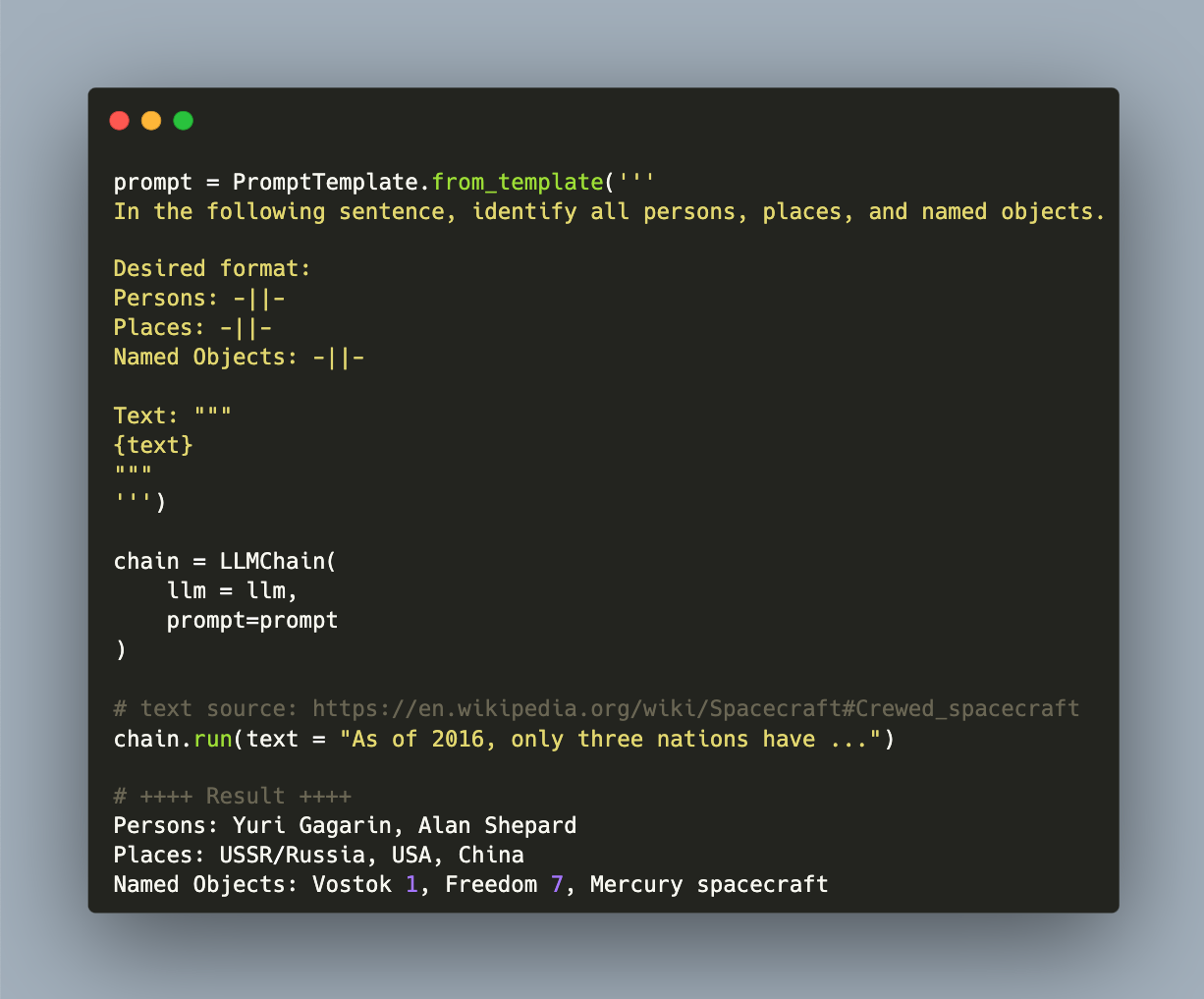
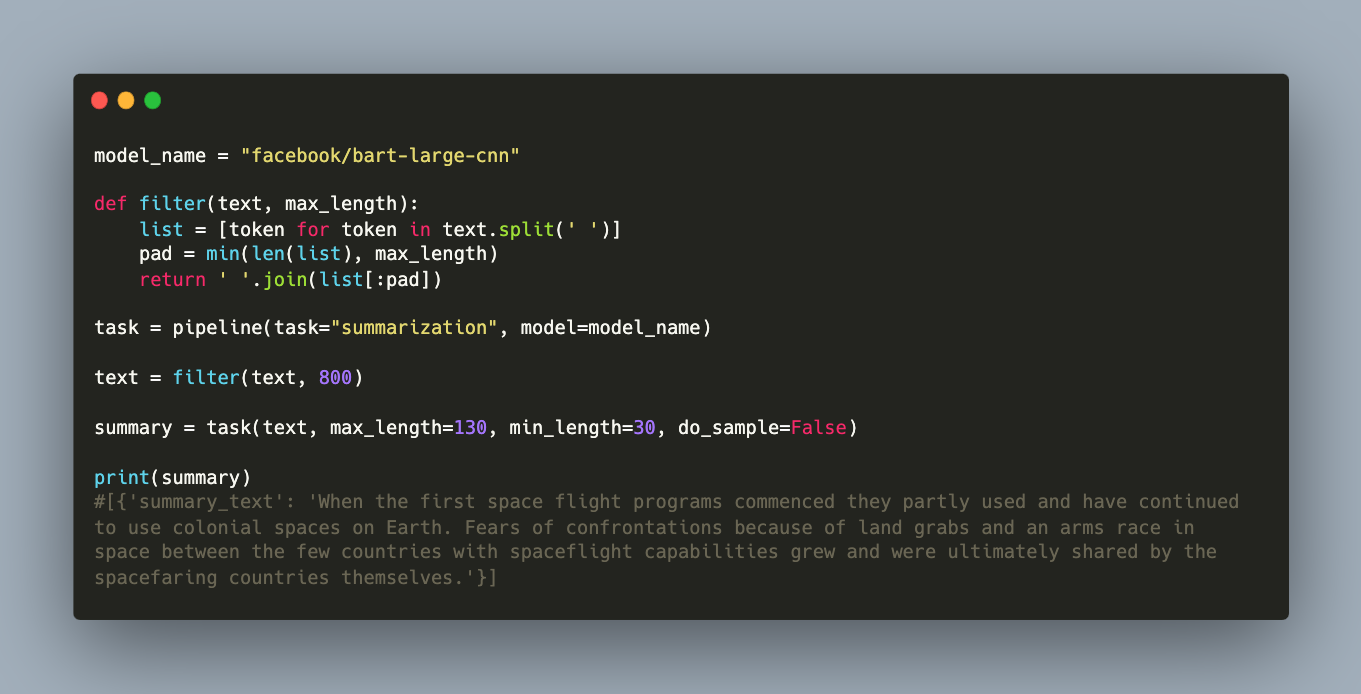
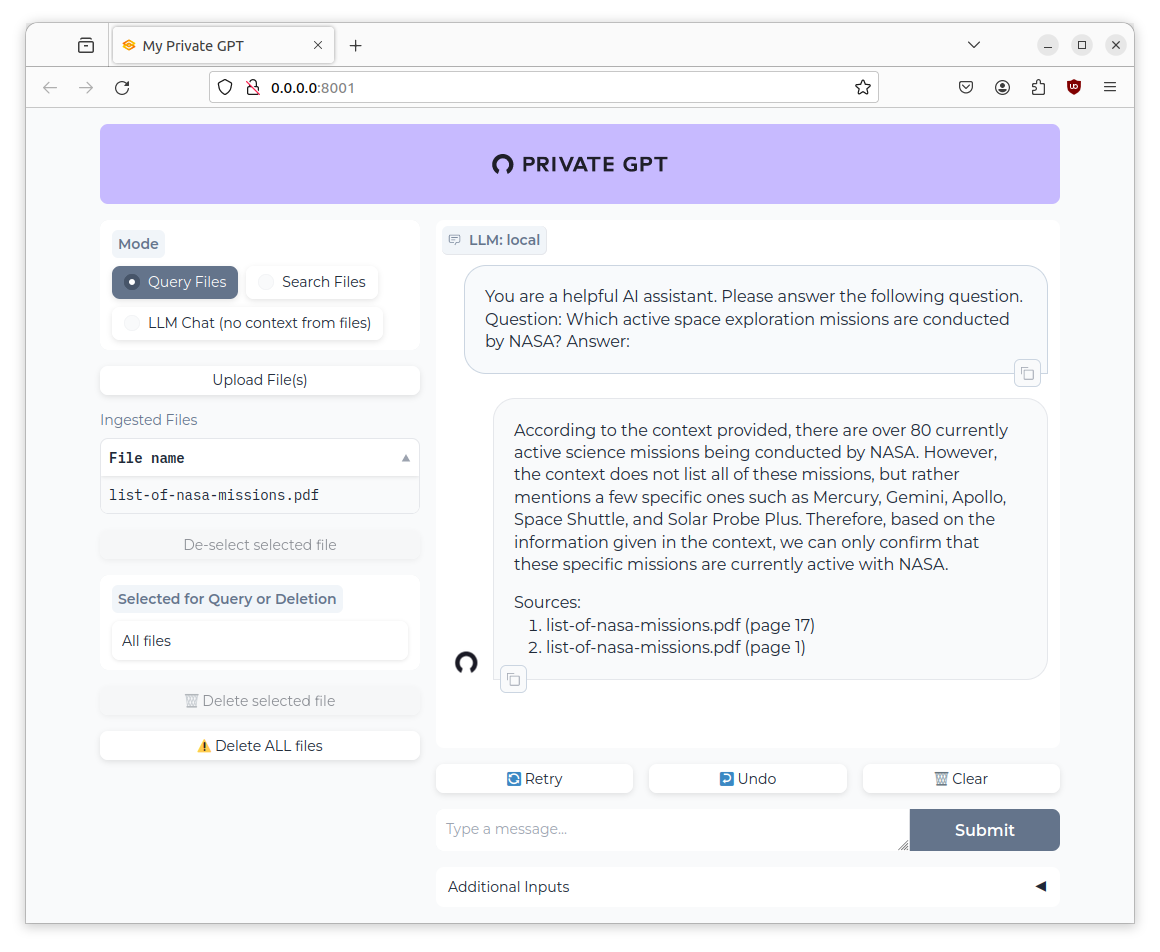
With the advent of ChatGPT and a free to use chat client available on their website, OpenAI pushed the frontier of easy-to-use personal assistants. Running a powerful LLM that supports knowledge worker tasks like text summarization, text generation, natural languages queries about any domain, or even the capability to produce source code, are astonishing and helpful. However, these assistants require paid accounts and can only be used through vendor specific clients or APIs.
Large Language Models (LLMs) are neural networks trained on terabytes of input data that exhibit several emergent behaviors with which advanced semantic NLP tasks like translation, question answering, and text generation evolve from the model itself without any further finetuning. This remarkable feature has given them the name Foundation Models, language models capable to push the frontier of NLP to almost human-level language competence.
Natural Language Processing with Large Language Modesl is the current state of the art. Investigating how classical NLP tasks became to be solved by LLMs can be observed with using the HuggingFace [transformers](https://huggingface.co/docs/transformers/index) library.
Large Language Models are a ubiquitous technology that revolutionizes the way we work with computers. LLMs in the size of around 7B provide good capabilities and include up-to-date knowledge. With a combination of a specialized data format and quantization, these models can be executed on modes consumer hardware with a six-core CPU and 16GB RAM.
The Cambrian explosion of Large Language Models (LLMs) happens right now. Ever increasing astonishing models are published and used for text generation tasks ranging from question-answering to fact checking and knowledge interference. Model with sizes ranging from 100 million to 7 billion and more are available with open source licenses. Using these models started from proprietary APIs and evolved to binaries that run on your computer. But which tools exactly can you use? What features do they have? And which models do they support?
In essence, Large Language Models are neural networks with a transformer architecture. The evolution of LLMs is a history of scaling: input data sources and tokenization, training methods and pipeline, model architecture and number of parameters, and hardware required for training and interference with large language models. For all of these concerns, dedicated libraries emerged that provide the necessary support for this continued evolution.
Large Language Models are sophisticated neural networks that produce texts. By creating one word at a time, given a context of other word, these models produce texts that rival humans. The creation of LLMs began back in 2018 and continues up to this data with ever more complex model architectures, consumed amount of texts, and parametric complexity.
Large Language Models are sophisticated neural networks that produce texts. Since their inception in 2018, they evolved dramatically and deliver texts that can rival humans. To better understand this evolution, this blog series investigates models to uncover how they advance. Specifically, insights from published papers about each model are explained, and conclusions from benchmark comparisons are drawn.
Large Language Models are sophisticated neural networks that produce texts. By creating one word at a time, given a context of other words, these models produce texts that can rival a humans output. The creation of LLMs began back in 2018 when the transformer neural network architecture was discovered. Since then, ever more complex transformer models in terms of parameter amount, and continues up to this data with ever more complex model architectures, consumed amount of texts, and parametric complexity.
The creation of Large Language Models (LLMs) began in 2018. Three factors emerged and were combined in LLMs: powerful computer and graphics processing units, huge amounts of structured and unstructured data that could be processed fast, and first-grade open-source project for the creation and training of neural networks.