Agent frameworks powered by LLMs promise to catapult autonomous task solving to unprecedented levels. Instead of rigid programming, LLMs reflect tasks, utilize tools, and check each other’s outputs to solve tasks creatively.
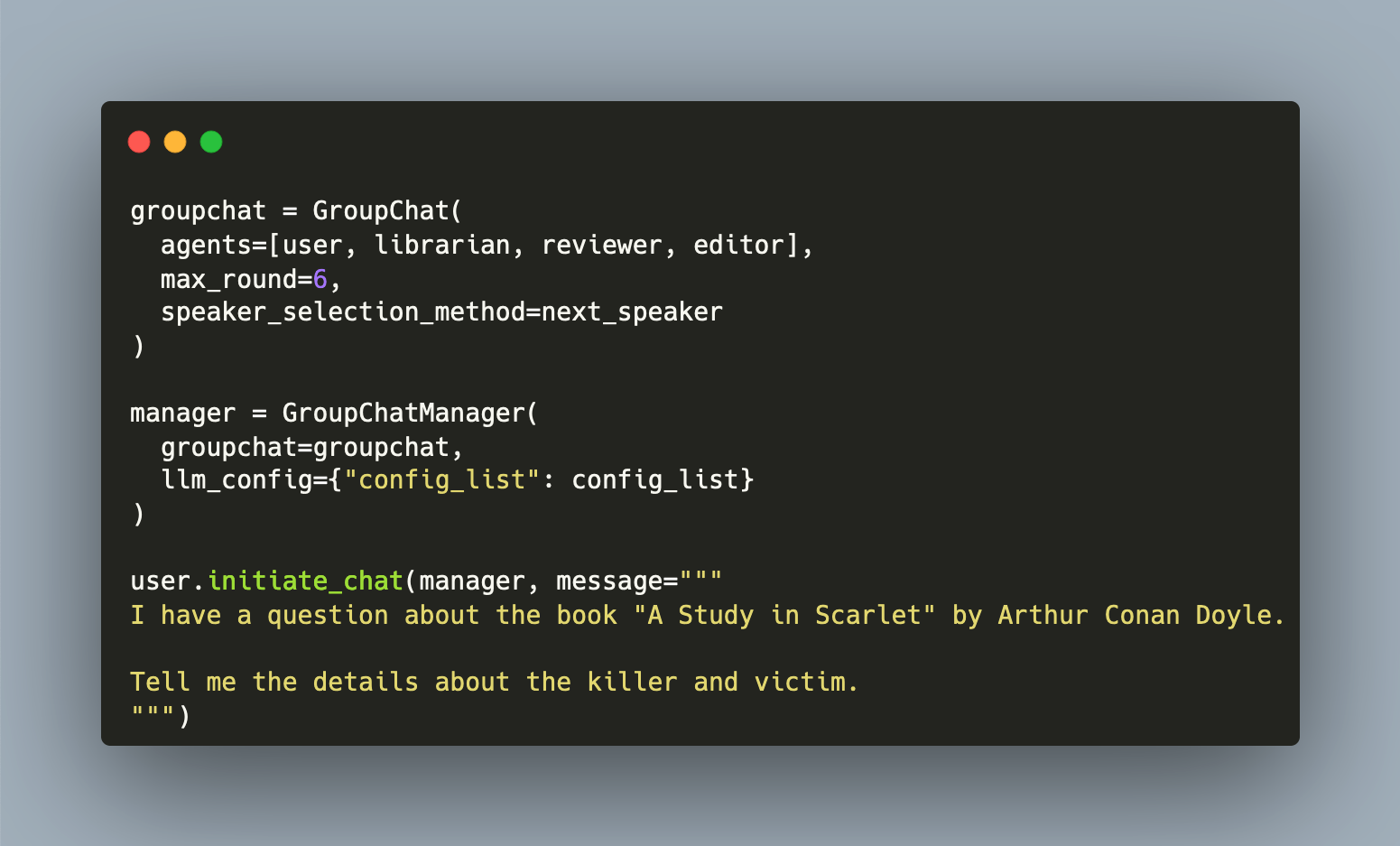
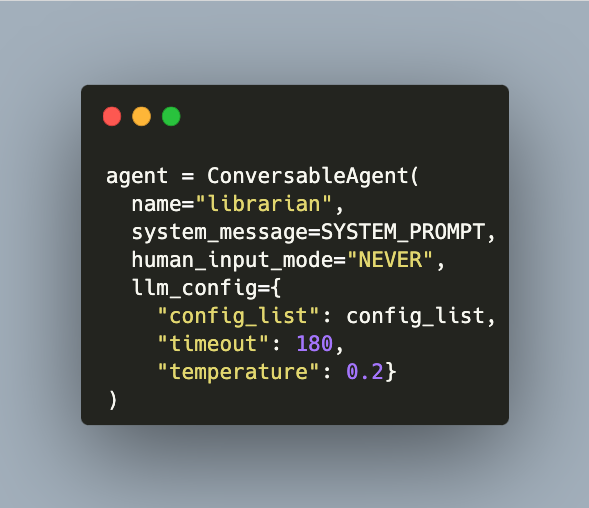
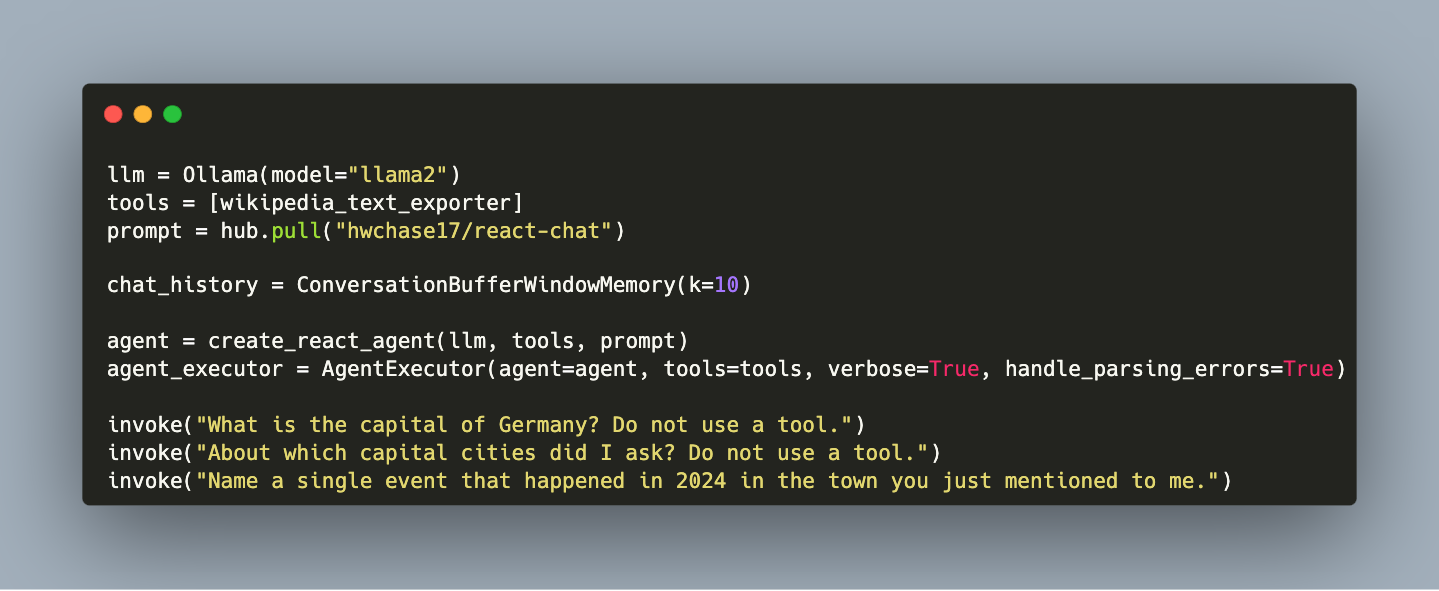
An agent is a Large Language Models customized with a system prompt so that it behaves in a specific way. The prompt typically details task types, expected task solution behavior, and constraints. Typically, an agent is invoked by a human user, and every interaction needs to be moderated. But what happens if an agent LLM interacts with other agents? And how does an agent behave when he has access to additional tools, e.g. to read additional data sources or to execute program code?
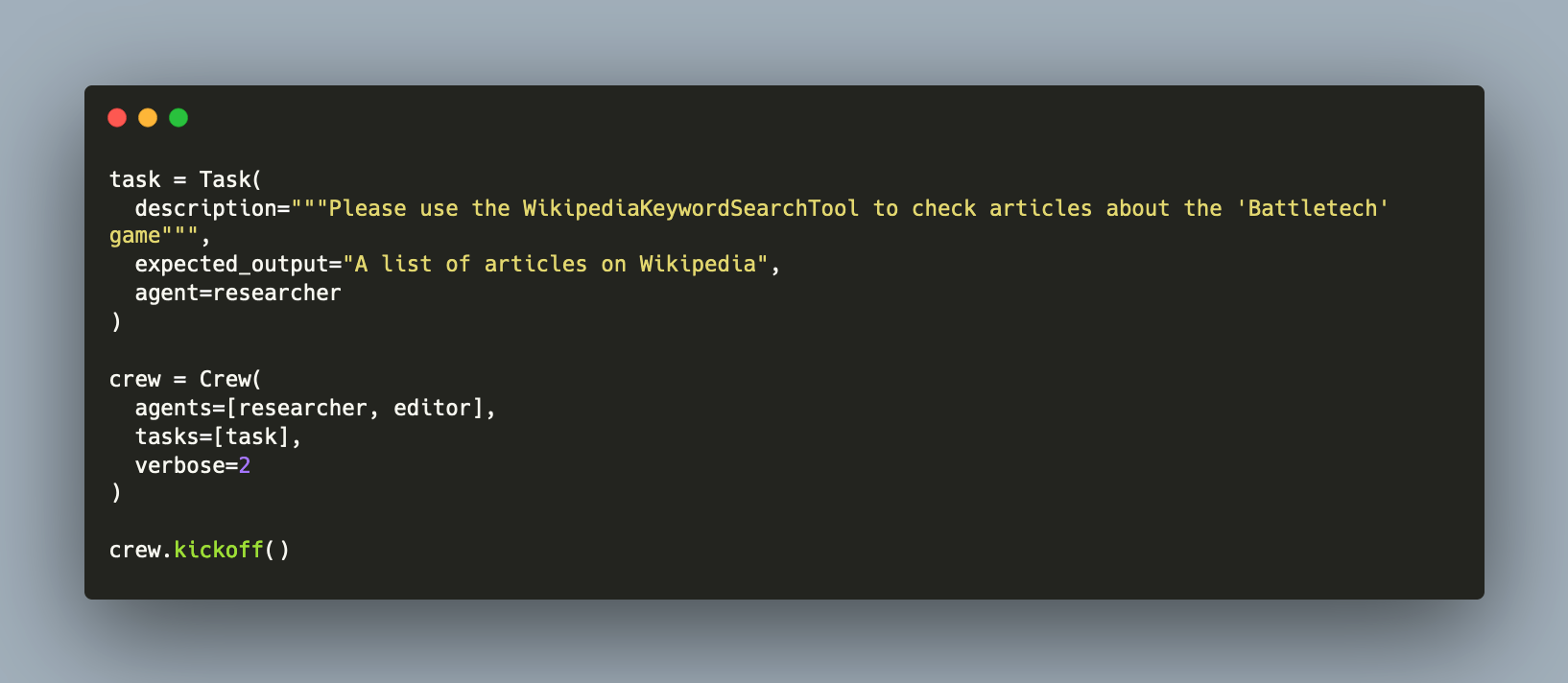
Large Language Models used as agents promise automatic task solution and to promote LLM usage to the next level. Effectively, an agent is created with a specific and refined prompt, detailing task types, expected task solution behavior, constraints, and even linguistic tone. Tools are the necessary ingredients to make the agent effective for its tasks. But what are these tools? And how can they be added to an agent?
In my ongoing quest to design a question-answer system, agents are the final available design. An LLM agent is an instance of an LLM with a specifically crafted prompt so that it incorporates a defined behavior and mode of talking. A further enhancement are tools, essentially functions that provide access to additional source of information’s or enable the application and execution of programming code.
The [LangChain](https://python.langchain.com) library spearheaded agent development with LLMs. When running an LLM in a continuous loop, and providing the capability to browse external data stores and a chat history, context-aware agents can be created. These agents repeatedly questioning their output until a solution to a given task is found. This opened the door for creative applications, like automatically accessing web pages for making reservations or ordering products and services, and iteratively fact-checking information.
Large Language Models (LLMs) are complex neural networks of the transformer architecture with millions or billions of parameters. Trained on terabytes of multi-domain and often multi-lingual texts, these models generate astonishing texts. With a correctly formatted prompt, these models can solve tasks defined in natural language. For example, classical NLP tasks like sentiment analysis, classification, translation, or question answering can be solved with LLMs, providing state-of-the-art performance over other NLP algorithms. On top of that, LLMs show advanced emergent behavior, enabling them to generalize to unforeseen tasks.
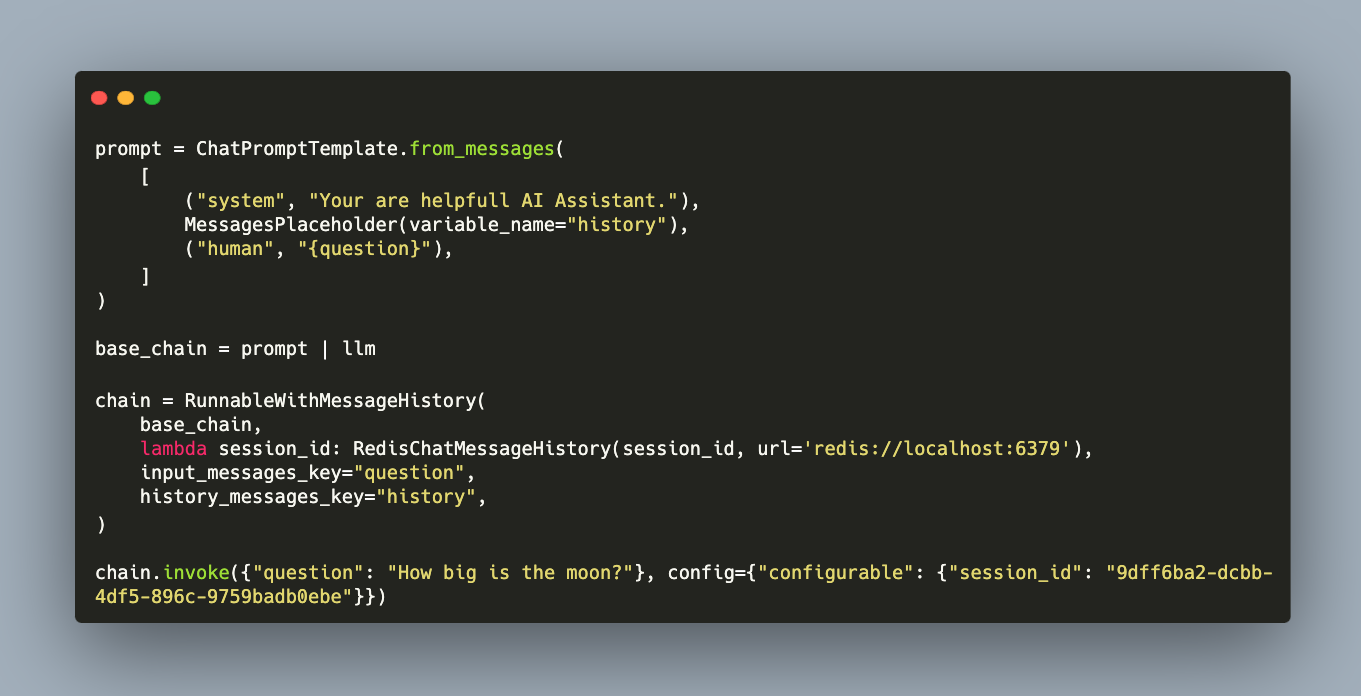
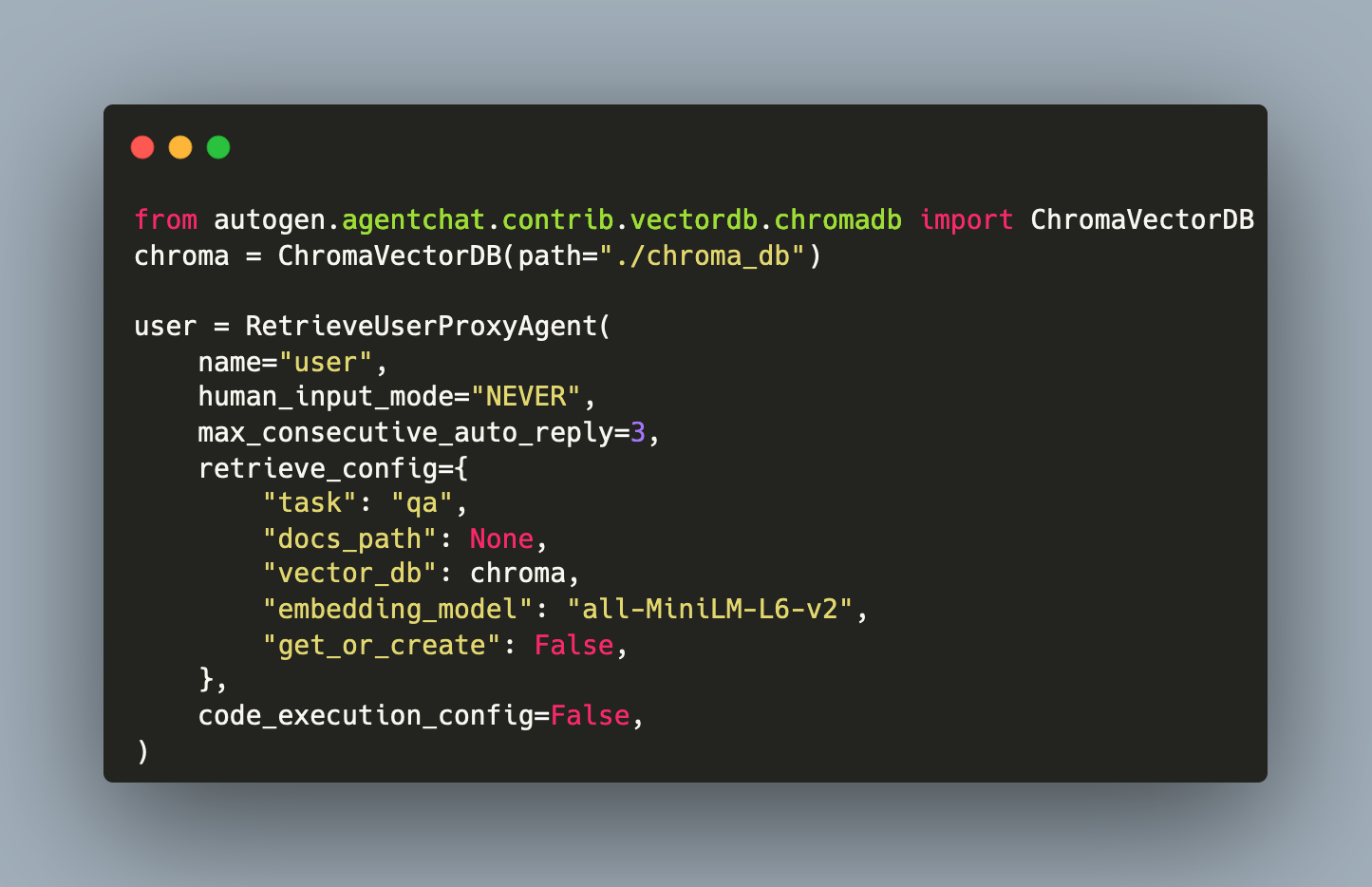
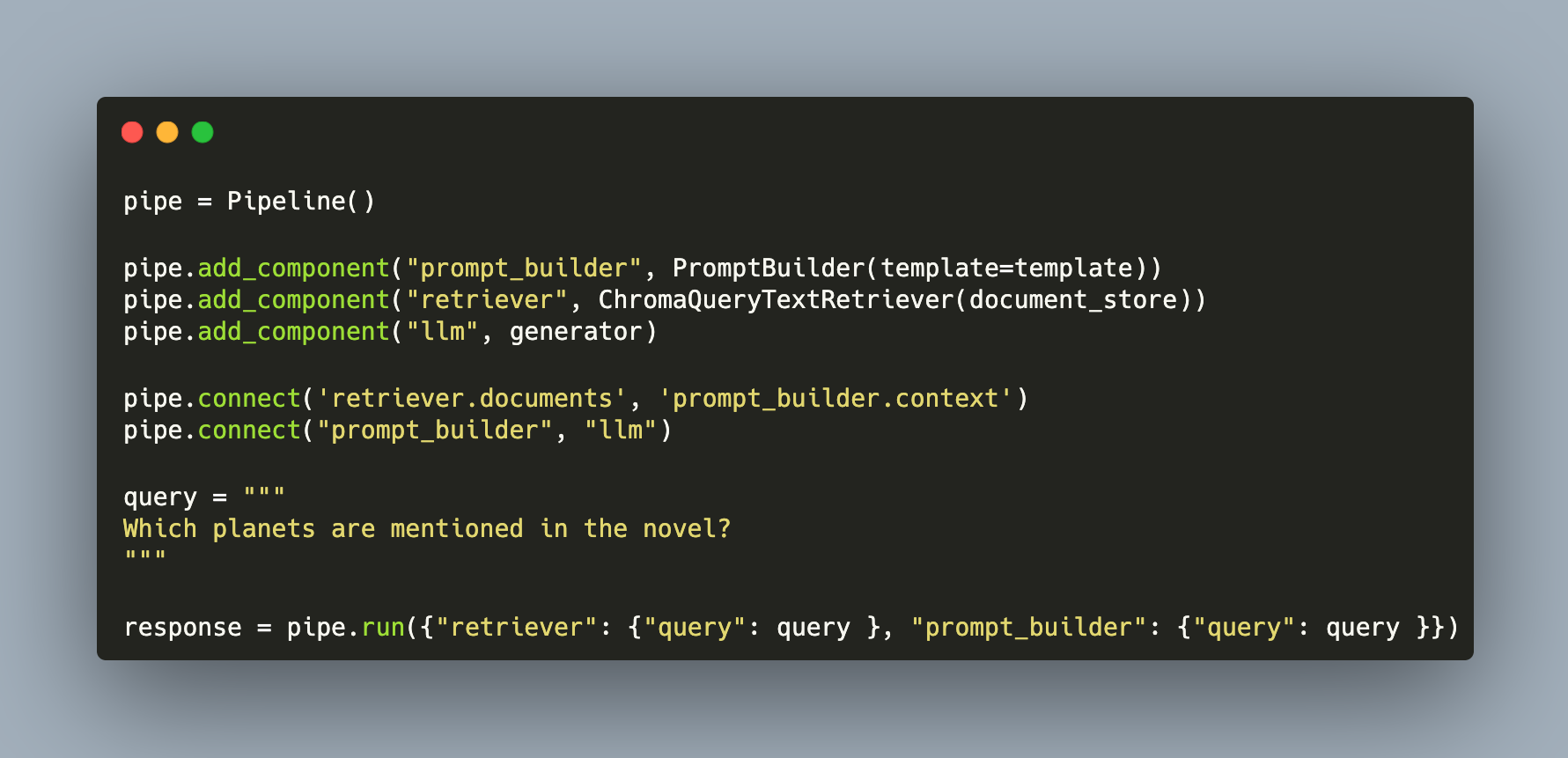
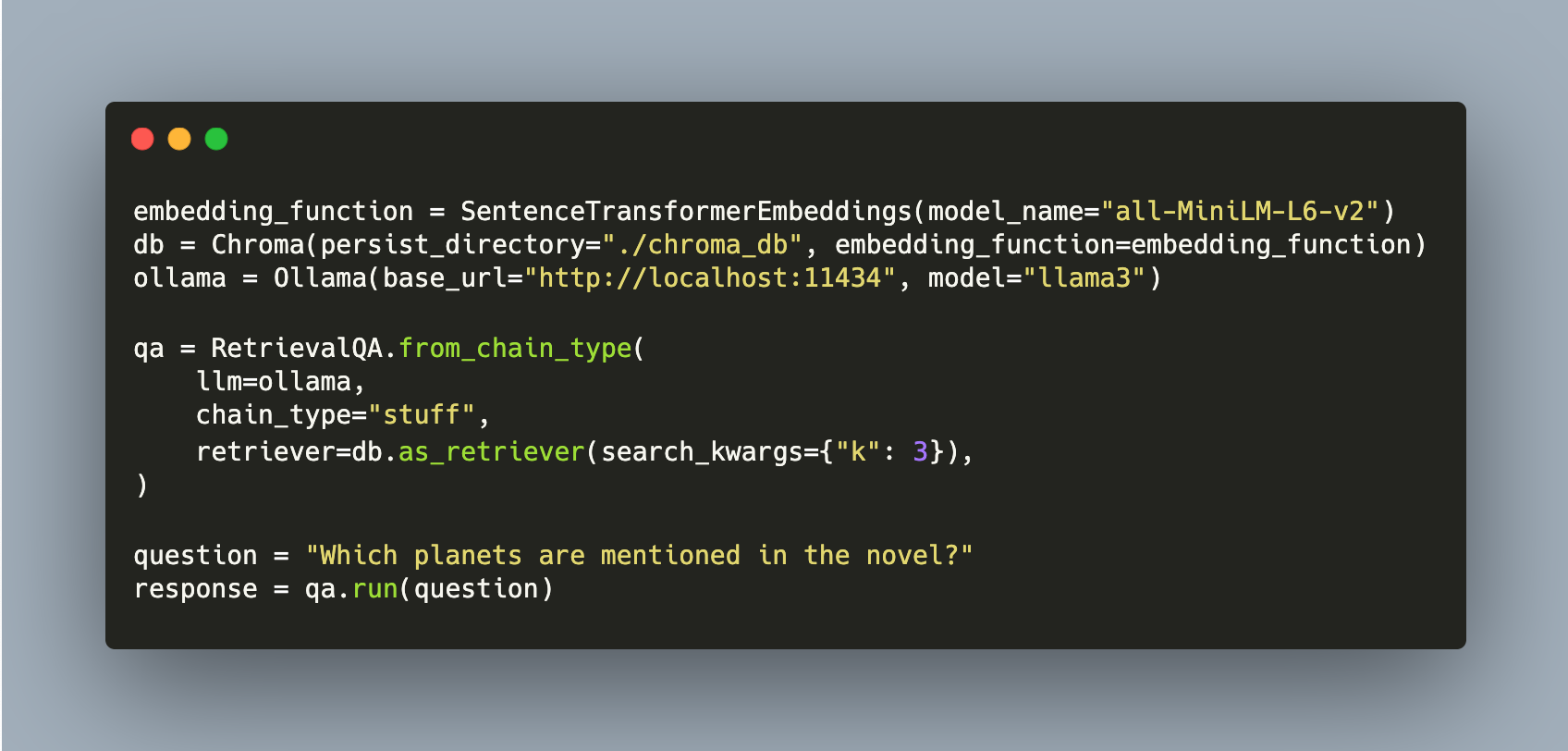
With an Retrieval Augmented Generation (RAG) framework, documents relevant for a given user query can be extracted from a database and used to enrich prompts for an LLM. This enables LLM invocation with both up-to-date and private data, greatly improving answer quality.
Large Language Models need accurate and up-to-date information when generating text for specific domains or with content from private data sources. For this challenge, Retrieval Augmented Generation pipelines are an effective solution. With this, relevant content from a vector database is identified and added to the LLM prompt, providing the necessary context for an ongoing chat.
Large Language Models have one crucial limitation: They can only generate text determined by the training material that they consumed. To produce accurate and correct facts, and to access recent or additional information, a Retrieval Augmented Generation (RAG) framework is added to the LLM invocation. The basic idea is to fetch relevant content from a (vector)database, optionally transpose or summarize the findings, and the to insert this into the prompt for the LLM. With this, a specific context for the LLM language generation is provided.
Large Language Models are vast neural networks trained on billions of text token. They can work with natural language in a never-before-seen way, reflecting a context to give precise answers.