Spacy is a powerful NLP library that performs many NLP tasks in its default configuration, including tokenization, stemming and part-of-speech tagging. These steps can be extended with a text classification task as well, in which training data in the form of preprocessed text and expected categories as dictionary objects are provided. Both multi-label and single-label classification is supported.
This article shows how to apply text classification on Wikipedia articles using Spacy. You will learn how to process Wikipedia articles, extract their categories, and transform them into Spacy-compatible format. Furthermore, you will see hot to create a classification task configuration file, customize it, and perform the training with Spacy CLI commands.
The technical context of this article is Python v3.11 and spacy v3.7.2. All examples should work with newer library versions too.
Context
This article is part of a blog series about NLP with Python. My previous article provided the core implementation of a WikipediaReader object that crawls and downloads articles. With this, a corpus of several hundred or thousand documents can be created, which is then abstracted by a WikipediaCorpus object for coarse corpus statistics data as well as access to individual articles. For all articles, their title, raw text, tokenized text, and vector representation are created and stored in a Pandas data frame object. This object is then consumed for successive clustering or classification tasks.
Prerequisite: Extract Wikipedia Article Categories
The first step is to provide the necessary data. Continuing with the program and features provided in my earlier articles, a Pandas DataFrame object is created that contains in each row the article name, its extracted category, and the raw text.
And here starts the first extension: Proper category names. On a closer look, categories extracted with the help of the Python library wikipedia-api contains both the intended, lexical categories as shown on an articles footer, as well as internal “tags” that specify if an article needs to be reviewed or otherwise modified.
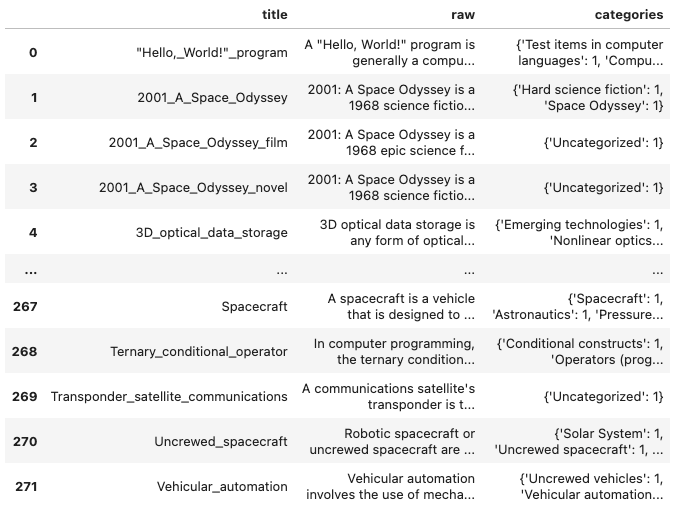
To illustrate this point, consider the categories of the article about Vehicular automation. At the bottom of the article page, you see two categories: Uncrewed vehicles and Vehicular automation. However, when using the library, a total of 13 categories are returned. See the following code snippet.
import wikipediaapi as wiki_api
wiki = wiki_api.Wikipedia(
language = 'en',
extract_format=wiki_api.ExtractFormat.WIKI)
p = wiki.page('Vehicular_automation')
print(len(p.categories))
#13
print([name.replace('Category:', '') for name in p.categories.keys()])
#['All articles containing potentially dated statements', 'All articles with unsourced statements', 'Articles containing potentially dated statements from December 2021', 'Articles using small message boxes', 'Articles with short description', 'Articles with unsourced statements from June 2021', 'CS1 Japanese-language sources (ja)', 'Incomplete lists from April 2023', 'Incomplete lists from June 2021', 'Short description is different from Wikidata', 'Uncrewed vehicles', 'Use dmy dates from April 2023', 'Vehicular automation']
Initially, I tried to filter the categories in such a way that they do not start with Articles using or All articles with, but I always found new and unexpected categories. Therefore, the categories need to be extracted from the articles content. Unfortunately, for both export formats, ExtractFormat.WIKI and ExtractFormat.HTML, the categories are not included.
Therefore, a new function is required. Consider the following target HTML structure:
<div id="catlinks" class="catlinks" data-mw="interface">
<div id="mw-normal-catlinks" class="mw-normal-catlinks"><a href="/wiki/Help:Category"
title="Help:Category">Categories</a>: <ul>
<li><a href="/wiki/Category:Uncrewed_vehicles" title="Category:Uncrewed vehicles">Uncrewed vehicles</a></li>
<li><a href="/wiki/Category:Vehicular_automation" title="Category:Vehicular automation">Vehicular automation</a>
</li>
</ul>
</div>
<div id="mw-hidden-catlinks" class="mw-hidden-catlinks mw-hidden-cats-hidden">Hidden categories: <ul>
<li><a href="/wiki/Category:CS1_Japanese-language_sources_(ja)"
title="Category:CS1 Japanese-language sources (ja)">CS1 Japanese-language sources (ja)</a></li>
<li><a href="/wiki/Category:Articles_with_short_description"
title="Category:Articles with short description">Articles with short description</a></li>
<li><a href="/wiki/Category:Short_description_is_different_from_Wikidata"
title="Category:Short description is different from Wikidata">Short description is different from Wikidata</a>
</li>
<li><a href="/wiki/Category:Use_dmy_dates_from_April_2023" title="Category:Use dmy dates from April 2023">Use dmy
dates from April 2023</a></li>
<li><a href="/wiki/Category:Articles_containing_potentially_dated_statements_from_December_2021"
title="Category:Articles containing potentially dated statements from December 2021">Articles containing
potentially dated statements from December 2021</a></li>
<li><a href="/wiki/Category:All_articles_containing_potentially_dated_statements"
title="Category:All articles containing potentially dated statements">All articles containing potentially
dated statements</a></li>
<li><a href="/wiki/Category:All_articles_with_unsourced_statements"
title="Category:All articles with unsourced statements">All articles with unsourced statements</a></li>
<li><a href="/wiki/Category:Articles_with_unsourced_statements_from_June_2021"
title="Category:Articles with unsourced statements from June 2021">Articles with unsourced statements from
June 2021</a></li>
<li><a href="/wiki/Category:Articles_using_small_message_boxes"
title="Category:Articles using small message boxes">Articles using small message boxes</a></li>
<li><a href="/wiki/Category:Incomplete_lists_from_April_2023"
title="Category:Incomplete lists from April 2023">Incomplete lists from April 2023</a></li>
<li><a href="/wiki/Category:Incomplete_lists_from_June_2021"
title="Category:Incomplete lists from June 2021">Incomplete lists from June 2021</a></li>
</ul>
</div>
</div>
Only the categories from the first list, identified by mw-normal-catlinks, should be parsed. To solve this, I wrote the following function that uses the requests library to load the full web page, and then uses regular expressions to extract the categories:
def get_categories(article_name):
wiki = wiki_api.Wikipedia(language = 'en')
p = wiki.page(article_name)
if not p.exists:
return None
r = requests.get(p.fullurl)
html = r.text.replace('\r', '').replace('\n', '')
catlinks_regexp = re.compile(r'class="mw-normal-catlinks".*?<\/div>')
catnames_regexp = re.compile(r'<a.*?>(.*?)<\/a>')
cat_src = catlinks_regexp.findall(html)[0]
cats = catnames_regexp.findall(cat_src)
if len(cats) == 0:
return ['Uncategorized']
else
return cats[1:len(cats)]
Let’s see the categories for “Vehicular automation” and “Artificial intelligence”.
get_categories('Vehicular_automation')
#['Uncrewed vehicles', 'Vehicular automation']
get_categories('Artificial_intelligence')
#['Artificial intelligence',
# 'Cybernetics',
# 'Computational neuroscience',
# 'Computational fields of study',
# 'Data science',
# 'Emerging technologies',
# 'Formal sciences',
# 'Intelligence by type',
# 'Unsolved problems in computer science']
With this function, only relevant categories are extracted.
Step 1: Data Preparation
To extract the Wikipedia articles and their categories properly, a modified SciKit learn pipeline is used. It’s based on the same unmodified WikipediaCorpusTransformer object - see my article about Wikipedia article corpus transformation - and a modified Categorizer that uses the above described method.
The pipeline definition is as follows:
pipeline = Pipeline([
('corpus', WikipediaCorpusTransformer(root_path=root_path)),
('categorizer', Categorizer()),
])
The updated Categorizer implementation uses the code from the previous section, but also processes articles which have no categories, which is then represented by the dictionary object {'Uncategorized':1}.
class Categorizer(SciKitTransformer):
def __init__(self):
self.wiki = wiki_api.Wikipedia(language = 'en')
self.catlinks_regexp = re.compile(r'class="mw-normal-catlinks".*?<\/div>')
self.catnames_regexp = re.compile(r'<a.*?>(.*?)<\/a>')
def get_categories(self, article_name):
p = self.wiki.page(article_name)
if p.exists:
try:
r = requests.get(p.fullurl)
html = r.text.replace('\r', '').replace('\n', '')
cat_src = self.catlinks_regexp.findall(html)[0]
cats = self.catnames_regexp.findall(cat_src)
if len(cats) > 0:
return dict.fromkeys(cats[1:len(cats)], 1)
except Exception as e:
print(e)
return {'Uncategorized':1}
def transform(self, X):
X['categories'] = X['title'].apply(lambda title: self.get_categories(title))
return X
When running the pipeline, the following DataFrame is created:
Step 2: Data Transformation For Spacy
The next step is to take the DataFrame object, perform a test-train split, and create the Spacy DocBin objects.
For the data split, SciKit Learn’s handy train_test_split method is used, with its helpful initial_state variable to ensure repeatable results.
train, test = train_test_split(X, test_size=0.2, random_state=42, shuffle=True)
Next, the data sets need to be transformed to a Spacy DocBin object and persisted on disk.
The individual steps are as follows:
- Create the
DocBinobject - Load spacy default model
en_core_web_lgfor vectorizing the text - Create a dictionary of all categories from all articles
- For each category, apply text vectorization to its
rawtext, and in the category dictionary object, set all applicable categories to the value1 - Finally, create a Spacy
Docobject and store it in theDocBinobject
Let’s examine the category creation a bit more, because it is complex in itself:
- Transform the pandas Series object for all data in the
"categories"column to a list - Join all lists together
- Create a set from all lists (to reduce duplicate entries)
- Create the dictionary with a dictionary comprehension for each entry of the list
Considering all of these aspects, the final functions is as follows:
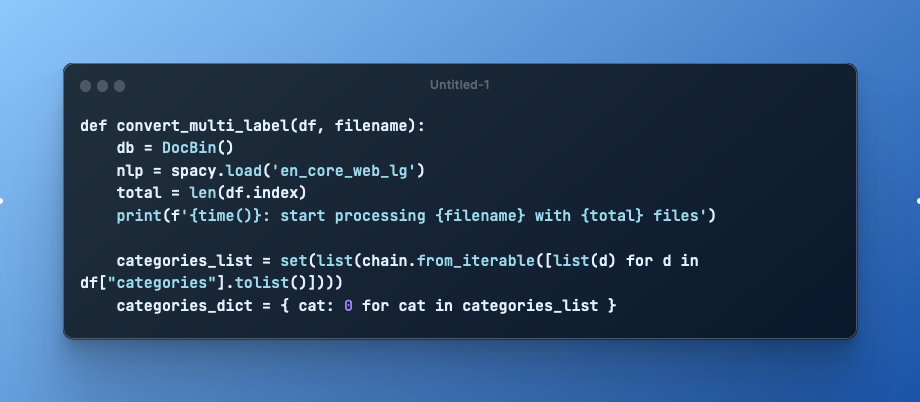
def convert_multi_label(df, filename):
db = DocBin()
nlp = spacy.load('en_core_web_lg')
total = len(df.index)
print(f'{time()}: start processing {filename} with {total} files')
categories_list = set(list(chain.from_iterable([list(d) for d in df["categories"].tolist()])))
categories_dict = { cat: 0 for cat in categories_list }
#print(categories_dict)
count = 0
for _, row in df.iterrows():
count += 1
print(f'Processing {count}/{total}')
doc = nlp(row['raw'])
cats = copy(categories_dict)
for cat in row['categories']:
cats[cat] = 1
doc.cats = cats
#print(doc.cats)
db.add(doc)
print(f'{time()}: finish processing {filename}')
db.to_disk(filename)
Then, running it on the splited data:
convert_multi_label(train, 'wikipedia_multi_label_train2.spacy')
2023-07-06 19:22:47.588476: start processing wikipedia_multi_label_train3.spacy with 217 files
# Processing 1/217
# Processing 2/217
# ...
# Processing 4/217
# Processing 217/217
# 2023-07-06 19:25:06.319614: finish processing wikipedia_multi_label_train3.spacy
convert_multi_label(test, 'wikipedia_multi_label_test2.spacy')
# 2023-07-06 19:25:10.557678: start processing wikipedia_multi_label_test3.spacy with 55 files# files
# Processing 1/55
# Processing 2/55
# Processing 3/55
# # ...
# Processing 55/55
# 2023-07-06 19:25:55.963293: finish processing wikipedia_multi_label_test3.spacy
Training
Training is started by running the command line interface spacy train with the following parameters:
- training pipeline configuration file
- training and testing input data
- output directory where the trained model is stored
Example command:
spacy train spacy_wikipedia_multi_label_categorization_pipeline.cfg \
--paths.train wikipedia_multi_label_train2.spacy \
--paths.dev wikipedia_multi_label_test2.spacy \
--output wikipedia_multi_label_model
During training, several information is shown: Details about the configuration itself, hardware capabilities, and a table containing the statistical data that is produced. (For a full explanation, see my previous article.)
2023-07-06 18:47:11.934948: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
✔ Created output directory: wikipedia_multi_label_model
ℹ Saving to output directory: wikipedia_multi_label_model
ℹ Using CPU
=========================== Initializing pipeline ===========================
[2023-07-06 18:47:16,428] [INFO] Set up nlp object from config
[2023-07-06 18:47:16,441] [INFO] Pipeline: ['tok2vec', 'textcat_multilabel']
[2023-07-06 18:47:16,445] [INFO] Created vocabulary
[2023-07-06 18:47:18,144] [INFO] Added vectors: en_core_web_lg
[2023-07-06 18:47:18,144] [INFO] Finished initializing nlp object
[2023-07-06 18:48:01,253] [INFO] Initialized pipeline components: ['tok2vec', 'textcat_multilabel']
✔ Initialized pipeline
============================= Training pipeline =============================
ℹ Pipeline: ['tok2vec', 'textcat_multilabel']
ℹ Initial learn rate: 0.001
E # LOSS TOK2VEC LOSS TEXTC... CATS_SCORE SCORE
--- ------ ------------ ------------- ---------- ------
0 0 7.66 0.28 2.53 0.03
0 200 148.32 1.37 2.55 0.03
1 400 0.00 1.04 2.83 0.03
2 600 0.01 1.04 2.65 0.03
3 800 0.00 1.21 2.68 0.03
4 1000 0.04 1.13 2.74 0.03
5 1200 0.00 1.09 2.62 0.03
6 1400 0.00 1.11 2.59 0.03
7 1600 0.00 1.27 2.49 0.02
8 1800 0.00 1.26 2.47 0.02
9 2000 0.00 1.23 2.56 0.03
Training Logbook
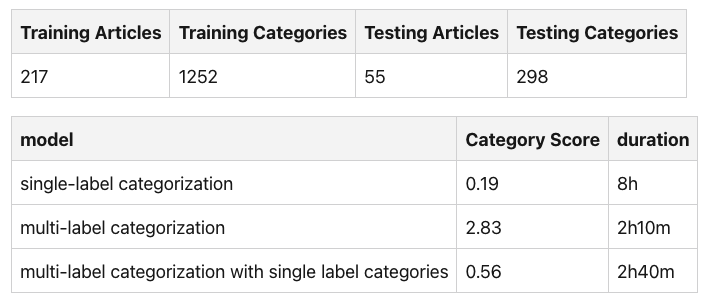
After some initial training and testing with multilabel classification, I decided to add two additional trained models as well and compare their results. In total, the following models were trained:
- single-label categorization
- multi-label categorization
- multi-label categorization with single label categories
All models were trained with the same optimizer:
[training.optimizer]
@optimizers = "Adam.v1"
beta1 = 0.9
beta2 = 0.999
L2_is_weight_decay = true
L2 = 0.01
grad_clip = 1.0
use_averages = false
eps = 0.00000001
learn_rate = 0.001
The following tables summarize the training process and duration.
Comparison
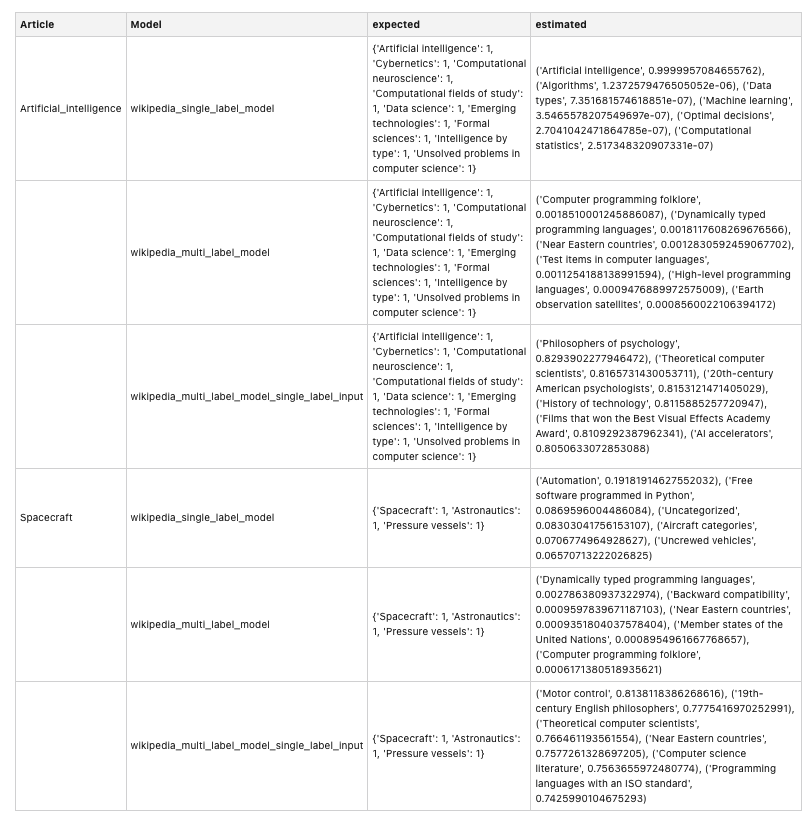
Finally, let’s compare the model’s category estimation. The following models extract the article name, raw text, and category from the DataFrame object, and then creates a Spacy nlp object to process the raw text and generate categories.
def estimate_cats(model, article):
name = article["title"]
text = article["raw"]
expected_cats = article["categories"]
nlp = spacy.load(f'{model}/model-best')
doc = nlp(text)
estimated_cats = (sorted(doc.cats.items(), key=lambda i:float(i[1]), reverse=True))
print(f'Article {name} || model {model}"')
print(expected_cats)
print(estimated_cats)
The following table summarizes the results for the articles about artificial intelligence and spacecraft.
Summary
Spacy is a NLP library in which pre-built models accomplish NLP tasks, like tokenization and lemmatization, and NLP semantics, like part-of-speech tagging, out-of-the-box. Internally, these tasks are represented and abstracted by a pipeline object, which can be extended with additional tasks. This article showed how to add text categorization to Spacy for processing Wikipedia articles. You learned how to extract Wikipedia article categories from the raw HTML representation of the articles, how to extend Spacy with a text categorization task, how to prepare the training data and execute the training with Spacy. Overall, three different models were trained: single-label categorization, multi-label categorization, and multi-label categorization with single label categories. The final section compared the categorization results for two articles.