
Fine-Tuning and evaluating LLMs require significant hardware resources, mostly GPUs. Building an on-premise machine learning computer is always an option. But unless you are running this machine 24-7, rented infrastructure for a short period of time may be the better option. And additionally, you get access to scalable hardware for the workload type: Why stop with a single 24GB GPU when you can have 10?
This article explores paid cloud provider products and platforms with a focus on running Jupyter notebooks and hosting LLMs. You will get to learn each platforms features and the available runtime. At the end of the article, I will give a personal recommendation which platform to use for what.
This article was written and researched in April 2024. Available hardware options and platform features might have changed when you read this article.
Platform Overview
The following providers with a one-click hosted Jupyter notebook are covered:
Additionally, following providers for general LLM hosting and finetuning are presented:
Hosted Jupyter Notebook Provider
Google Colab
Colab is the most commonly mentioned free platform encountered in many projects and blog post. For LLM fine-tuning, quantization and evaluation, a Collab notebook containing a proof-of-concept is most likely linked. And when opened, the reason become clear: A Jupyter instance opens, and when you are logged in, you can start a session and execute the Python code immediately.
On top of the Jupyter notebook instance, several other features are offered via the GUI, such as one-click saving to Google storage, export the Notebook as a GitHub gist, or the option to open a file browser. Another interesting option is to connect the notebook to a GCE VM or to a local runtime, combining the software features with a hardware base of your choice.
At the time of writing this article, the free-tier Colab starts an image of Ubuntu 22.04 with Python 3.10 and several other pre-installed libraries. Three different runtime environments can be used:
CPU
- CPU: 1x Intel Xeon @ 2.20GHz
- RAM: 12 GB
TPU
- CPU: 1x Intel Xeon @ 2.20GHz
- RAM: 12 GB
- TPU: TPU v2
T4 GPU
- CPU: 1x Intel Xeon @ 2.20GHz
- RAM: 12 GB
- Tesla T4 16GB
Using the free tier collab comes with some restrictions. The runtime stability is not guaranteed - VMs may be preempted before your code finishes to run. And a strict session timeout is applied. Unless you regularly refresh the browser window, your session may also end premature.
There is also a paid variant, called Colab Pro, that advertises these benefits: 100 computer units, more memory and faster GPUs, and the option to use a terminal for connecting to the runtime. According to my internet search, this means access to NVIDIA A100 and V100 GPUs and up to 52GB RAM.
Kaggle
Kaggle is a sophisticated platform for machine learning projects. It provides datasets, models and code repositories, learning and collaboration features like forums, courses and competition, and Jupyter notebooks.
Kaggle notebooks use Jupyter but offer a different UI with less options. In contrast, other options were added: a) use any Kaggle model or dataset as an input b) pin the environment to a timestamp, which guarantees that the same OS packages remain available, c) save the notebook as a specific version, and d) schedule the notebook to run periodically.
A Kaggle Jupyter notebook instance starts Ubuntu 20.04 with Python 3.10 installed via conda. Four runtimes are supported:
Default
- CPU: 2x Intel Xeon @ 2.2GHz
- RAM: 32 GB
GPU T4x2
- CPU: 2x Intel Xeon @ 2.2GHz
- RAM: 32 GB
- GPU: 2x T4 16GB
GPU P100
- CPU: 2x Intel Xeon @ 2.0GHz
- RAM: 32 GB
- GPU: P100 16GB
TPU VMv3-8
- CPU: 2x Intel Xeon @ 2.0GHz
- RAM: 32 GB
- TPU: P100 16GB
Kaggle also imposes some restrictions. The GPU environments are capped at 30h usage each week, the TPU environments at 20h, and the maximum session duration is 12 hours, but you need to periodically refresh the browser.
Kaggle was acquired by Google, and the old paid version Kaggle Pro is superseded by the option to connect a Kaggle notebook with custom GCP VM instances, giving you more hardware power when required.
SageMaker Studio Lab
Amazon offer the SageMaker Studio platform as an entry to machine learning projects. Similar to the other products so far, it provides several features to support the full machine learning lifecycle, starting with input data, pipelines, version models and deployments. And with SageMaker Studio Lab, a free entry level Jupyter notebook with a visually modified UI is offered.
The host environment in SageMaker Studio Lab is Ubuntu 20.04 with Python 3.9. Two runtimes are available:
CPU
- CPU: 2x Intel Xeon Platinum 8259CL 2.50GHz
- RAM: 16GB GB
GPU
- CPU: 2x Intel Xeon Platinum 8259CL 2.50GHz
- RAM: 16GB GB
- GPU: T4 16GB
The free tier restrictions are: CPU max 8h each day, max 4h continued used, and GPU max 4h each day and 4h continued use. The paid version is called SageMaker Studio Classic and offers 30+ different types of VMs. See the full list in the official documentation.
Vast AI
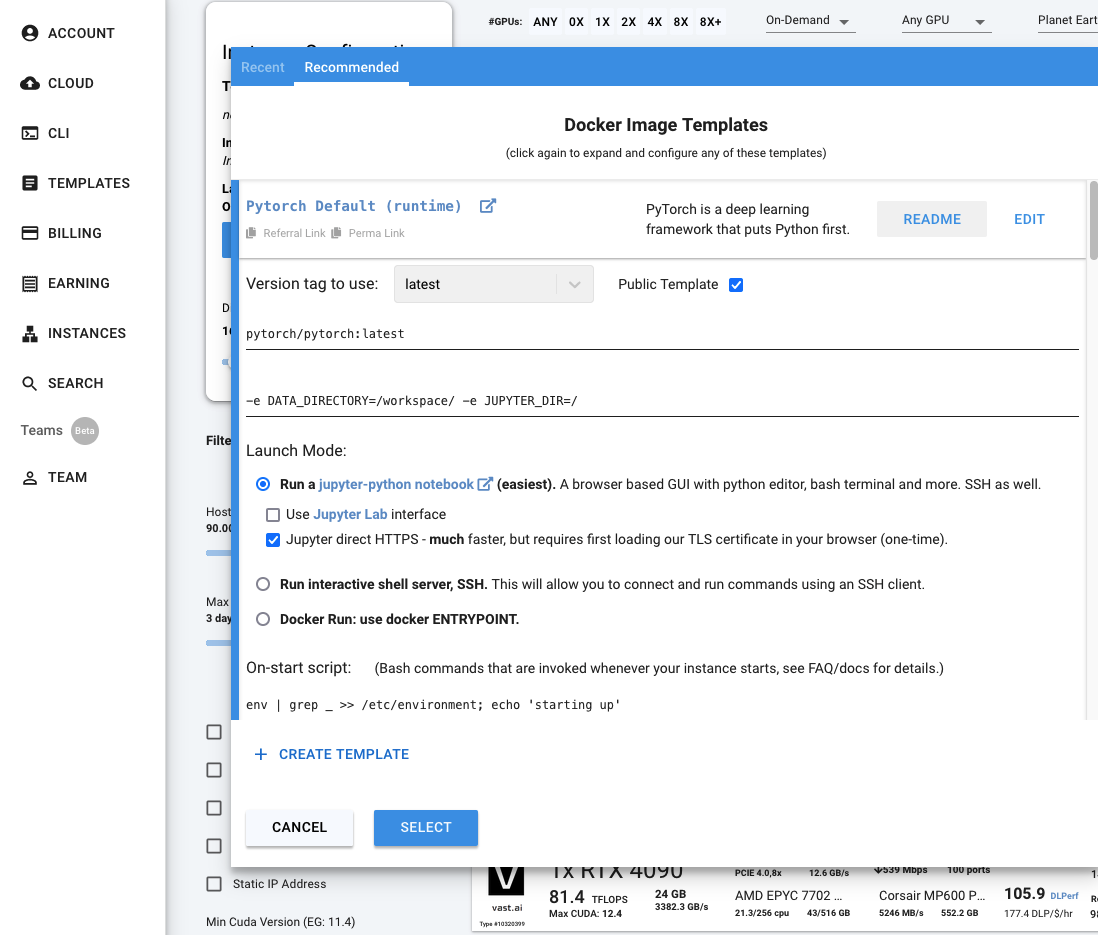
This unique platform is a marketplace for on-demand GPU servers with an astonishing amount of hardware configurations. From entry level 4 core CPUs with 8GB GPUs to 40 core with 8x 24GB GPUs plus fibre-optics connected data center computer - you can find any combination that meets the requirements. You have full visibility of all incurring costs and can host servers on-demand or interruptible.
The machines are provisioned with Docker images. In addition to Cuda and PyTorch environments with a hosted Jupyter notebook, you can also find templates that directly start a hosted LLM with an API or even a WebUI.
To test the available offers, I choose a machine with 8 cores, 128GB RAM, 2x 24GB GPU and the cuda-jupyter template - for less than 0,50$ a hour! Just after 30 seconds of renting this machine, I could open the Jupyter Notebook on a hosted Ubuntu 20.04 with Python 3.8. Printing the available hardware showed this:
# CPU
model name: AMD EPYC 7252 8-Core Processor
cpu MHz: 1496.828
cpu cores: 8
# RAM
MemTotal: 131841012 kB
# OS
Linux ace1bfb4a221 5.4.0-162-generic #179-Ubuntu SMP Mon Aug 14 08:51:31 UTC 2023 x86_64 x86_64 x86_64 GNU/Linux
# GPU
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.54.03 Driver Version: 535.54.03 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA RTX A5000 On | 00000000:41:00.0 Off | Off |
| 30% 14C P8 16W / 230W | 1MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
| 1 NVIDIA RTX A5000 On | 00000000:42:00.0 Off | Off |
| 30% 13C P8 18W / 230W | 1MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
Paperspace
Paperspace is a machine learning platform with two different products. The first product is called Core, which enables to host custom containers with public or private images. The second product is Gradient, it offers the creation of notebooks, workflows, models, and deployments.
Gradient notebooks are based on Jupyter. When opened, they show the familiar code-cell structure to add code or markdown. To the left of the UI, you have options to see the files, access a terminal, connect to data sources, and see hardware metrics. You can also access a notebook with the default Jupyter UI.
An interesting feature is to create custom container images called templates. This gives you full control of the hosted environment. You can also capture the entire disk image as a custom template, saving time when loading external models or when custom software needs to be compiled.
Plenty runtimes are supported - see the following VM configuration screenshot and the list of available runtimes.
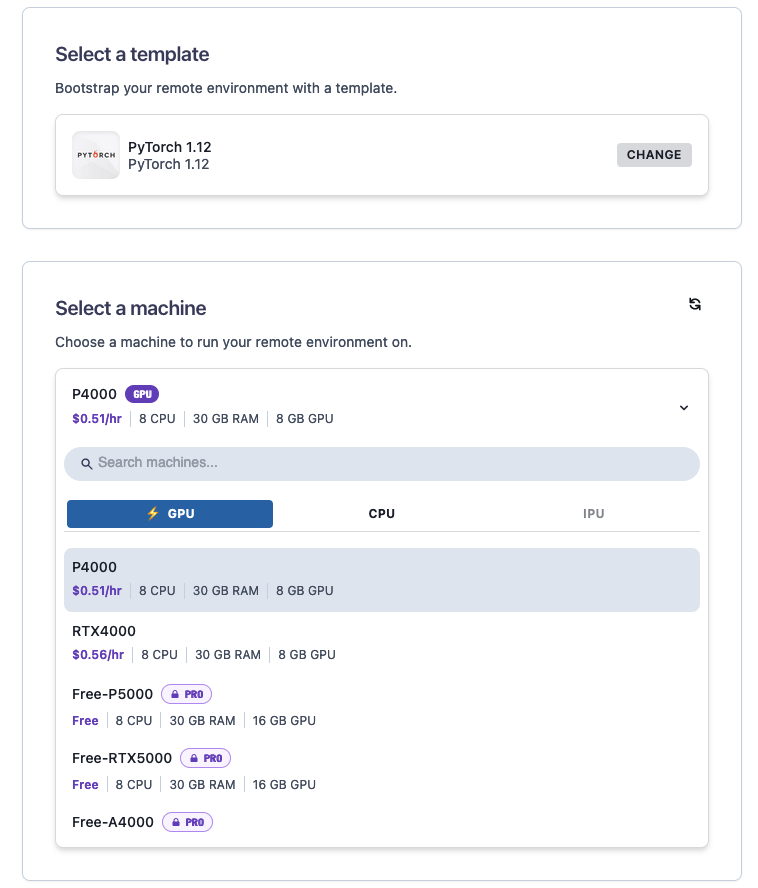
P4000
- CPU: 8x
- RAM: 30GB
- GPU: 8GB
RTX4000
- CPU: 8x
- RAM: 30GB
- GPU: 8GB
P5000
- CPU: 8x
- RAM: 30GB
- GPU: 16GB
A4000
- CPU: 8x
- RAM: 45GB
- GPU: 16GB
A5000
- CPU: 8x
- RAM: 45GB
- GPU: 24GB
A6000
- CPU: 8x
- RAM: 45GB
- GPU: 48GB
Paperspace comes with different service levels: free, pro, growth, enterprise. Each plan has a monthly subscription fee, and either gives you access to free or paid resources. In the free plan, sessions have a timeout of 6 hours.
LLM Hosting Provider
Replicate
Replicate is a cloud provider with a focus on hosting (muti-model) LLMs. They provide an easy interface to host LLMs as well as supporting LLM fine-tuning and evaluation using different tiered hardware specs.
For fine-tuning an LLM, a very specific approach needs to be followed: Providing JSONL formatted input data that confirms with the LLMs expected input format, and then using a client API to push to a dedicated endpoint. There is no option to use quantization. The documentation is extensive and gives several full-scale tutorials like Fine-tune a language model.
The following runtimes are offered:
Nvidia T4 GPU
- CPU: 4x
- RAM: 8GB
- GPU: 16GB
Nvidia A40 GPU
- CPU: 4x
- RAM: 16GB
- GPU: 48GB
Nvidia A40 GPU (Large)
- CPU: 10x
- RAM: 72GB
- GPU: 48GB
Nvidia A100 (40GB) GPU
- CPU: 10x
- RAM: 72GB
- GPU: 40GB
Nvidia A100 (80GB) GPU
- CPU: 10x
- RAM: 144GB
- GPU: 80GB
8x Nvidia A40 (Large) GPU
- CPU: 48x
- RAM: 680GB
- GPU: 8x48GB
Several hosted LLMs are supported: LLaMA2 (7B,13B,70B), Mistral 7B and Mixtral 8x7B. The Mistral 7b costs $0.05 per 1M input tokens and $0.25 per 1M output tokens.
Octo AI
OctoAi is another cloud provider that is focused on hosting LLMs and vision models. Their product compute service supports open-source model like Mixtral, Mistral, Llama 2. Additionally, a custom developed model can be used. Another product is called octo stack, a network solution that integrates on-premise or cloud hosted environments via VPN with a corporate infrastructure.
The compute service offers these hardware types for hosting:
Small
- CPU: 4x
- RAM: 16GB
- GPU: T4 16GB
Medium
- CPU: 8x
- RAM: 32GB
- GPU: A10G 24GB
Large 40
- CPU: 12x
- RAM: 144GB
- GPU: 40GB
Large 80
- CPU: 12x
- RAM: 144GB
- GPU: 80GB
Small
- CPU: 10x
- RAM: 144GB
- GPU: 80GB
Hosted LLMs include LLaMA2 (13B, 70B), CodeLLaMA (7B, 13B, 34B), LLaMAGuard 7B, Mistral 7B, Hermes 2 7B, Mixtral 8x7B, and Nous Hermes 2 Mixtral 8x7bB. On OctoAI, a hosted Mistral 7B costs $0.10 per 1M input tokens and $0.25 per 1M output tokens.
Fal AI
The FAL platform advertises itself for image generation only. When looking closer into the documentation, other services become visible. First, multimodal models are available, such as the vision models and text to audio. Second, you can provision your own models. And third, the Fal client library exposes annotations which can turn any function to be running in the cloud. This enables to LLMs too, as shown in their tutorial Running Llama 2 with vLLM.
Following GPU runtimes are offered.
GPU A100
- CPU: 10
- RAM: 64GB
- GPU: 40GB
GPU A6000
- CPU: 14
- RAM: 100GB
- GPU: 16GB
GPU A10G
- CPU: 8
- RAM: 32GB
- GPU: 24GB
Compute-only runtimes are available as well:
- CPU: 8
- RAM: 16GB
M
- CPU: 2
- RAM: 2GB
S
- CPU: 1
- RAM: 1GB
Run Pod
This platform enables the deployment of any type of application that can be put inside a Docker container. You simply select a public Docker image or provide your own, configure the endpoint, and deploy on the available runtimes. This allows you to host a JupyterNotebook, as well as any LLM with an OpenAI compatible endpoint by using the special vLLM Endpoint type.
The amount of runtimes is impressive and customizable - you can choose from 1 to 8GPUs. Here is a small excerpt only.
H100 80GB PCIe
- CPU: 16x
- RAM 188 GB RAM
- GPU: 80 GB
A100 80GB
- CPU: 12x
- RAM 83 GB RAM
- GPU: 80 GB
RTX A6000
- CPU: 8xP
- RAM 50 GB RAM
- GPU: 48 GB
L40
- CPU: 16x
- RAM 58 GB RAM
- GPU: 48 GB
Supported LLMs are LLaMA2 (7B, 13B), Pygmillion (6B). For LLaMA2 7b, 1M Tokens cost $ 0.75.
Cerebrium AI
The final platform has serverless GPU infrastructure as its focus. Cerebrium develops a flexible Python library with which hosted projects can be specified and implemented. The specification can include specific Python pip, conda and apt packages, and the implementation is a Python file that exposes expected functions to start an application. To show the flexibility of this framework, their public Github repository cerebrium-prebuilts shows examples such as hosting LLMs, vision models and more.
Provided runtimes can be dynamically calculated. You need to select one of the available GPU types (H100, A100, A6000 and more), and the CPU and RAM are calculated to meet availability metrics. Or you specify the required hardware of GPU, CPU and RAM in your products.
The pricing is calculated in seconds per used GPU, CPU and RAM GB, plus monthly storage.
Conclusion
When working with LLMs for fine-tuning, quantizing or evaluation, scalable hardware resources are important. This article investigated free and paid cloud products and platforms.
For hosting a Jupyter notebook, the providers Collab, Kaggle, SageMaker Studio Lab, VastAI and Paperspace were presented. My recommendation is as follows. For free-tier accounts, Kaagle provides a slow CPU but generous 2x 16GB GPUs, which is sufficient for a small LLM LoRa fine-tuning or evaluation (but you need to refresh the browser session). For paid accounts, Gradient offers reasonably costs and a polished UI which lets you save data and notebooks. And if you need considerable resources, use vast.ai to find very powerful machines, but you need to copy your notebook content manually.
For LLM hosting and finetuning, these providers were investigated: Replicate, OctoAI, Fal, RunPid and Cerebrium AI. From these, Replicate has the best price, and Cerebrium the best flexibility for self-hosting LLMs.