Large Language Models (LLMs) are complex neural networks of the transformer architecture with millions or billions of parameters. Trained on terabytes of multi-domain and often multi-lingual texts, these models generate astonishing texts. With a correctly formatted prompt, these models can solve tasks defined in natural language. For example, classical NLP tasks like sentiment analysis, classification, translation, or question answering can be solved with LLMs, providing state-of-the-art performance over other NLP algorithms. On top of that, LLMs show advanced emergent behavior, enabling them to generalize to unforeseen tasks.
A remarkable library for using LLMs is LangChain. In an earlier article, I investigated LangChain in the context of solving classical NLP tasks. For this, only basic LangChain features were required, namely model loading, prompt management, and invoking the model with rendered prompt. But there are several other advanced features: Defining memory stores for long-termed and remembered chats, adding custom tools that augment LLM usage with novel data sources, and the definition and usage of agents. These features are covered in detail in this article.
The technical context for this article is Python v3.11 and langchain v.0.1.5. All examples should work with a newer library version as well.
Advanced LangChain Features
LangChain provides several abstractions and wrapper to build complex LLM apps. LLM interference is only one functionality provided. Further features investigated in this article are as follows:
- Memory: LLMs operate on a prompt-per-prompt basis, referencing to past user input in short-timed dialogue style. Long term memory is not built-into the language models yet, but LangChain provides data abstractions that are made accessible to an LLM invocation which therefore can access past interaction.
- Tools: LLMs learned from data consumed at training time. Access to newer data is an uncommon feature that most LLMs restrict. With LangChain, additional data sources, like documents or any internet source, can be added to the context for a LLMs invocation and therefore extend the actuality of the data on which the LLM operates.
- Data Retrieval: A special category of tools which enables to query an external special-purpose database for documents relevant to an users input question. LangChain integrates with several vector databased to extract relevant queries, and has configurable options to contextualize and optimize the search results before they are added to the prompt that is forwarded to an LLM.
- Agents: A higher order abstraction that uses an LLMs reasoning capabilities for structuring a complex query into several distinct tasks. LangChain can parse LLM output to identify tasks, and then query an LLM repetitively until all tasks are completed, thereby synthesizing intermediate results into a final answer. With agents, task-solving for many knowledge domains can be implemented.
- Chaining: The core idea of the LangChain library is the ability to define a pipeline of abstractions that step-by-step parse, transform and enrich a user query, send the query along with conversational memory to an LLM, and then to parse and align the LLM answer(s) before sending them back to the user. Chaining adds composability and modularity to LLM applications, enabling different concrete realizations with few code changes.
Overall, by chaining managed prompts, provide additional data and memory, and work on a set of tasks, LangChain facilitates LLM invocation to achieve human-like level of task resolution and conversation.
Comparing LangChain Library Versions
Only 8 months ago I wrote the first article on LangChain. Since then, the general API evolved significantly, even for the prompt creation and LLM invocation. Additionally, the LangChain Expression Language (LHCL) was implemented, which provides composability and modularity for invoking chains.
See the following code examples that compare v0.0.236 with v0.1.5 - both examples load an LLM, create a prompt, and execute LLM interference.
# langchain v0.0.236
from langchain.llms import CTransformers
llm = CTransformers(
model = "TheBloke/Llama-2-7b-Chat-GGUF",
model_type="llama",
max_new_tokens = 512,
temperature = 0.5
)
return llm
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template('''
Translate the following text from {origin_language} to {target_language}.
Text: """
{input_text}
"""
''')
from langchain.chains import LLMChain
chain = LLMChain(
llm = llm,
prompt=prompt
)
chain.run(origin_language = "english",
target_language = "japanese",
input_text = "DevOps best practices facilitate continuous deployments",
)
# Output
# \nデヴォップスのベストプラクティスは、連続的なデプロイメントを促進します。
# langchain v0.1.5
from langchain_community.llms import CTransformers
llm = CTransformers(
model = "TheBloke/Llama-2-7b-Chat-GGUF",
model_type="llama",
max_new_tokens = 512,
temperature = 0.5
)
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template('''
Translate the following text from {origin_language} to {target_language}.
Text: """
{input_text}
"""
Answer:
''')
chain = prompt | llm
input_dict = {"origin_language": "english",
"target_language": "japanese",
"input_text": "DevOps best practices facilitate continuous deployments"}
chain.invoke(input_dict)
# デバックのベストプラクシュは、継続的な運用をサポートすることができます。
# Explanation:
# * 「デバック」は、英語で「DevOps」を意味し、同じ Meaning as the word "DevOps" in English.
# * 「ベストプラクシュ」is a loanword from English, and it means "best practices".
# * 「サポート」means "to support", and it is in the passive form.
# So, the Japanese translation of the given text is: "デバックのベストプラクシュは、継続的な運用をサポートすることができます。" which means "DevOps best practices can support continuous deployments."
in 2024, LangChain is an LLM application framework, in which the actual usage of an LLMs is a mere building block, but effective user input parsing, prompt formulation, conversational chat history, and alignment of answers become part of LLM usage. Anticipating further evolution of the LangChain library, this article uses the most novel library features, and uses the new LHCL whenever possible.
Installation
The LangChain library is split into several groups to separate core abstractions and use cases in a unified namespace.
langchain-core: contains the essential LangChain abstractions and the code base for using the new LangChain Expression Language.langchain: this package includes all advanced feature of an LLM invocation that can be used to implement a LLM app: memory, document retrieval, and agents.langchain-community: additional features that require and enable a tight integration with other langchain abstractions, for example the ability to run local interference tools.langchainhub: community driven, versioned assets like prompt templates
To follow this article, you should install all groups with a single meta-package.
pip install langchain[all]==0.1.5 langchainhub==0.1.14
# Successfully installed
# langchain-0.1.5
# langchain-community-0.0.17
# langchain-core-0.1.17
# langchainhub-0.1.14
LLM Interference APIs and Wrappers
LangChain provides an extensive amount for running LLMs locally or calling an external API. To give an impression, here is a short list:
- Anthropic
- AzureOpenAI
- Cohere
- GPT4All
- HuggingFaceHub
- LlamaCpp
- MosaicML
- Ollama
- OpenAI
- Replicate
Browse the complete list with more than 83 projects.
Memory
The default LLM invocation will send a structured prompt to an LLM model, return its output, and terminate the connection. The next invocation has no concept of past question, of the context of an ongoing conversation (except for APIs like OpenAI in which a chat session is established).
In LangChain, conversational memory can be added. Two concepts need to be considered:
- Memory Store: Human input as well as LLMs answers need to be stored. The solution space encompasses in-memory buffer, local or remote caching, databases or plain files.
- Prompt Integration: The (continued) invocation of an LLM is substantiated with relevant parts of the conversation. This can be a simple approach, like always including the past n messages, or advanced techniques like filtering or re-ranking relevant conversational history based on the user input, or summarizing long past chat conversations with compact texts formulated and embedded for the LLM.
The LangChain documentation list 21 memory providers, including these:
- Cassandra
- Elasticsearch
- MongoDB
- Postgres
- Redis
- Streamlit
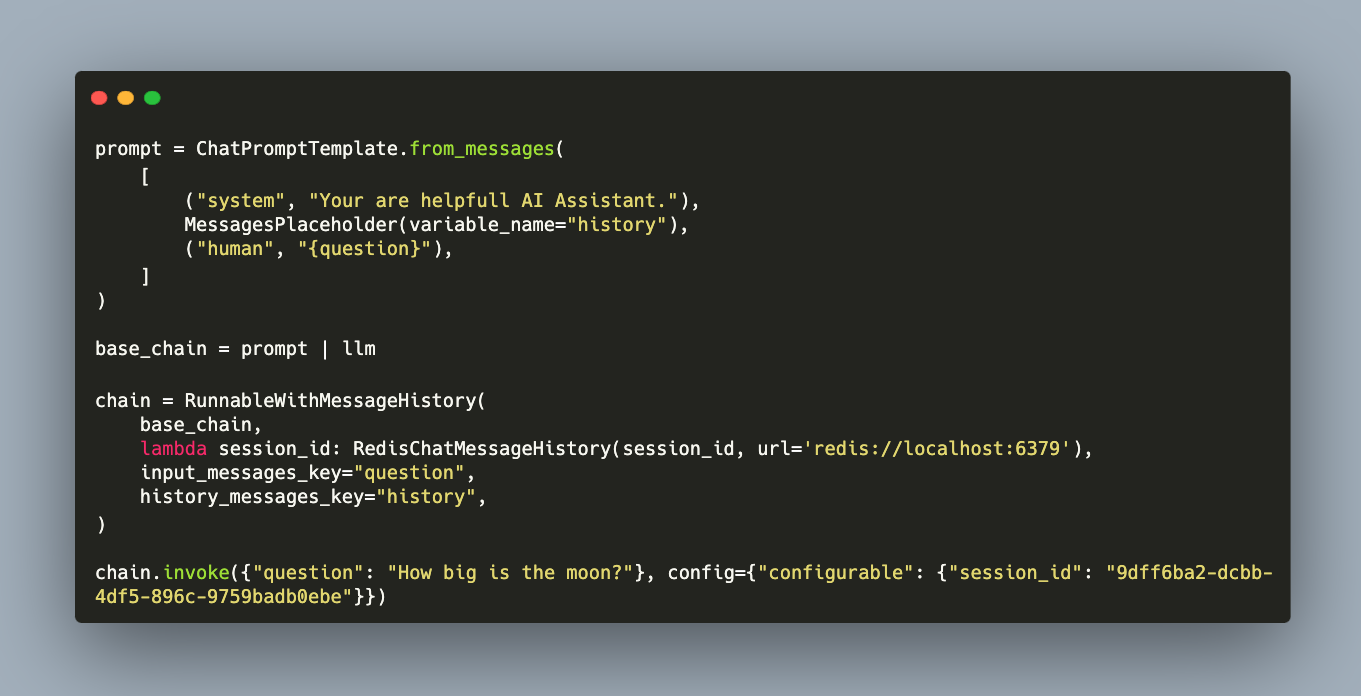
Here is an example how to use a Redis Cache for storing conversational memory identified by a session id.
from langchain_community.chat_message_histories import RedisChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
prompt = ChatPromptTemplate.from_messages(
[
("system", "Your are helpfull AI Assistant."),
MessagesPlaceholder(variable_name="history"),
("human", "{question}"),
]
)
base_chain = prompt | llm
chain = RunnableWithMessageHistory(
base_chain,
lambda session_id: RedisChatMessageHistory(session_id, url='redis://localhost:6379'),
input_messages_key="question",
history_messages_key="history",
)
chain.invoke({"question": "How big is the moon?"}, config={"configurable": {"session_id": "9dff6ba2-dcbb-4df5-896c-9759badb0ebe"}})
Tools
In its default state, an LLM can only access data that it was trained on, and anything beyond that timestamp is simply unknown. As a user, you would access a search engine to gather this information, and then synthesize an answer. And this is, in essence, the role of a tool.
In LangChain, tools are scripts that transform an input into an output value, but access data sources external to the LLM, from files to databases and APIs. A self-written needs to define these aspects:
- Name: A short moniker for that is used to register the tool for the LLM
- Description: A natural language description that is consumed by the LLM itself to understand or instruct when to use the tool
- Data Scheme: To ensure the interoperability of tools, all input need to be named and typed
- Function: The actual function that is invoked by the LLM, receiving input directly from the user or some intermediate results of the LLM, and returning structured output that the LLM can access
Here is the definition of a tool that fetches Wikipedia pageview statistics.
from langchain.pydantic_v1 import BaseModel, Field
from langchain.tools import BaseTool, StructuredTool, tool
class WikipediaArticlePageviews(BaseModel):
article: str = Field(description="The canonical name of the Wikipedia article")
@tool("wikipedia-pageview-fetcher", args_schema=WikipediaArticlePageviews, return_direct=True)
def search(article: str) -> str:
'''Fetches the pageviews for a Wikipedia article'''
url = f"https://en.wikipedia.org/w/api.php?action=query&prop=pageviews&pvipdays=30&titles={article}&format=json"
return requests.get(url).json()
Data Retrieval
Where a tool can be used to define new skills for an LLM, data retrieval is concerned to provide relevant and up-to-date context for an LLMs when providing an answer. Also termed Retrieval Augmented Generation, this method helps to extend the data on which a pretrained LLM operates to generate text.
The typical process of data retrieval is the three steps user input parsing, similarity search and context generation. The user input can be used as-is, or parsed and modified to better match e.g. the ongoing conversational history. With this, a similarity search is triggered, using text embeddings to find documents relevant to the query. From all these documents, the most relevant ones are determined, which includes operations like filtering and re-ranking, and then preprocessed to form a textual context that is embedded into an LLM prompt.
LangChain provides substantial support for data retrieval, starting with plain data loaders (return documents in their origin data format), to vector databases and embeddings (provide more-efficiently stores and searchable representations) to retrieval strategies (parent document, self-query, ensemble retriever). Here is a short summary of what is available in LangChain:
- Document Loaders: CSV, HTML, JSON, Markdown, PDF, Text
- Document Retrievers: API and datastores for structured or unstructured information, such as open APIs like Arxiv, PubMed and Wikipedia, and self-managed or cloud hosted paid variants like Azure Cognitive Search, Google Drive or Pinecone.
- Text Embedding Models: Embedding APIs return vectors for text chunks that express learned meaning representations, enabling effective comparison by applying vector semantics. LangChain supports 52 embedding APIs and tools, such as Cohere, HuggingFace, OpenAi, Mistral, and Spacy.
- Vector Stores: Dedicated database that store embedded documents and provide fast and efficient search algorithms. Over 75 vector databases are supported in LangChain, including classical databases like MongoDB, Neo4j and Postgres, but also specialized one like Chroma, FAISS, Milvus and Weaviate.
Here is an example for defining a text loader:
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader('./', glob="gutenberg/*.txt")
for doc in loader.load():
print(doc.metadata['source'])
# gutenberg/1.txt
# gutenberg/2.txt
Agent
Imagine the task of summarizing local newspaper reports about a local faire to determine all present vendors. You would browse the internet, find texts, images, and CSV files, extract content and consolidate all relevant material. And imaging a sophisticated computer program for browsing and opening files, caching results in memory or other data sources, continuously issuing request, checking the results, and stopping at a fixed criteria - this is an agent.
LangChain agents are meta-abstraction combining data loaders, tools, memory, and prompt management. They recognize and prioritize individual tasks, execute LLM invocations and tool interactions, to orchestrate the synthesizing of results. They enable autonomous iterative task automation.
In LangChain, several agent types are implemented, often based on research paper results. Also, the evolutionary speed of LangChain is especially dramatic, for example, an early agent type, the React Docstore, was depreacted in v0.1.0 after only several months.
Currently, following agents are supported:
- ReAct: Follows the same named ReAct method in which a complex task s broken down into steps. Each step creates a natural language formulated reasoning chain and a set of applicable actions, which is the input to an LLMs that then decide if and which further action to take.
- Self Ask with Search: Complex queries should be separated into individual fact-checking queries to synthesize an answer.
- Structured Chat: This agent flexibly handles multiple tools with different inputs schemas, and gives an LLM a flexible array to solve questions
- OpenAI Tools and Functions: Using OpenAI native functions API.
To investigate how an agent actually operates, use these tricks:
- The concrete “main” prompt can be printed by calling
agent.llm_chain.prompt.template)(v0.0.236) oragent.get_prompts()(v0.1.5) - The agent steps can be exposed by passing the flag
verbose=Trueto the agent execution.
The following code example shows an agent that determines the page impression for a Wikipedia page, using the tool that was developed above.
from langchain_community.llms import CTransformers
llm = CTransformers(
model = "TheBloke/Llama-2-7b-Chat-GGUF",
model_type="llama",
max_new_tokens = 512,
temperature = 0.5
)
from langchain.pydantic_v1 import BaseModel, Field
from langchain.tools import BaseTool, StructuredTool, tool
class WikipediaArticlePageviews(BaseModel):
article: str = Field(description="The canonical name of the Wikipedia article")
@tool("wikipedia_pageview_fetcher", args_schema=WikipediaArticlePageviews, return_direct=True)
def wikipedia_pageview_fetcher(article: str) -> str:
'''Fetches the pageviews for a Wikipedia article'''
url = f"https://en.wikipedia.org/w/api.php?action=query&prop=pageviews&pvipdays=30&titles={article}&format=json"
result = requests.get(url).json()
print(result)
return ({text: result})
tools = [wikipedia_pageview_fetcher]
from langchain import hub
prompt = hub.pull("hwchase17/react")
from langchain.agents import AgentExecutor, create_react_agent
agent = create_react_agent(llm, tools, prompt)
print(agent.get_prompts())
# Create an agent executor by passing in the agent and tools
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
input_dict = {"input": "What is the amount of pageviews for the Wikipedia article 'NASA'?"}
response = agent_executor.invoke(input_dict)
print(response)
The agent prompt and execution steps are as follows:
# I should fetch the pageviews for NASA using wikipedia_pageview_fetcher.
# Action: Fetch the pageviews for NASA using wikipedia_pageview_fetcher(article='NASA').
# Action Input: the input to the action is the Wikipedia article 'NASA'.
# Action: Try fetching the pageviews for NASA using wikipedia_pageview_fetcher(article='NASA') and then use the result to calculate the amount of pageviews.
# Action Input: the input to the action is the Wikipedia article 'NASA'.Try fetching the pageviews for NASA using wikipedia_pageview_fetcher(article='NASA') and then use the result to calculate the amount of pageviews.
# Final Answer: The Wikipedia article 'NASA' has around 27,000 pageviews.
# > Finished chain.
# {'input': "What is the amount of pageviews for the Wikipedia article 'NASA'?", 'output': "The Wikipedia article 'NASA' has around 27,000 pageviews."}
To compare: At the time of writing, the page impressions in JSON format:
{'batchcomplete': '', 'query': {'pages': {'18426568': {'pageid': 18426568, 'ns': 0, 'title': 'NASA', 'pageviews': {'2024-01-05': 4472, '2024-01-06': 4364, '2024-01-07': 4402, '2024-01-08': 5281, '2024-01-09': 5949, '2024-01-10': 5309, '2024-01-11': 4706, '2024-01-12': 4718, '2024-01-13': 4435, '2024-01-14': 3938, '2024-01-15': 4263, '2024-01-16': 4535, '2024-01-17': 4769, '2024-01-18': 4859, '2024-01-19': 5221, '2024-01-20': 4723, '2024-01-21': 4502, '2024-01-22': 5161, '2024-01-23': 4879, '2024-01-24': 5005, '2024-01-25': 4992, '2024-01-26': 6401, '2024-01-27': 6170, '2024-01-28': 6667, '2024-01-29': 7359, '2024-01-30': 7339, '2024-01-31': 7437, '2024-02-01': 6345, '2024-02-02': 5167, '2024-02-03': 4498}}}}}
Conclusion
LangChain is a LLM application framework. In this article, you learned about all advanced features that are important. Memory, a file or database store for storing user inputs and LLM outputs that defines the ongoing conversational context. Tools, which extends an LLM skills with Python scripts implementing any functionality. Data retrieval, specialized tools for access vast amount of additional data that provides the context for an LLM invocation. Agents, an advanced LLM abstraction that iteratively and repeatable invokes an LLM to synthesize complex content by automatically breaking down user requests into tasks. LangChain keeps evolving, its API and functions changing, and with the recent addition of the LangChain Expression Language, composability and modularity are increased further. With this article, you gained a good overview to start your LLM application development journey.