Large Language Models need accurate and up-to-date information when generating text for specific domains or with content from private data sources. For this challenge, Retrieval Augmented Generation pipelines are an effective solution. With this, relevant content from a vector database is identified and added to the LLM prompt, providing the necessary context for an ongoing chat.
This article investigates RAG pipelines with the Haystack framework. You will learn the essential RAG setup and utilization steps in the context of this pipeline, starting with VectorDB setup, continuing with data ingestion and similarity search, and finally the complete RAG pipeline.
The technical context of this article is Python v3.11 and haystack-ai v2.1.1. All code examples should work with newer library versions too, but may require code updates.
Haystack and ChromaDB
Haystack is a versatile and effective library for creating configurable component-based pipelines. From document stores and embedding algorithms, to converters, rankers and readers, any requirements for structured content processing can be implemented. It also integrates several LLM engines and APIs. In an earlier blog post about Haystack for solving NLP tasks, I already showed this pipeline concept to create custom template prompts that were filled for specific NLP tasks.
Haystack supports ChromaDB - however only its data format, it has yet no adapter to communicate with a ChromaDB instance. Therefore, the implementation needs to start with data ingestion and local persistence.
Vector Database Setup and Data Ingestion
The ChromaDocumentStore object is instantiated by passing the collection name, the embedding model, and an optional directory path.
from haystack_integrations.document_stores.chroma import ChromaDocumentStore
document_store = ChromaDocumentStore(
"documents",
"default",
"./chroma_db")
To my surprise, when given an already populated directory where a ChromaDB instance with another framework was stored, this object remains empty!
document_store.count_documents()
# 0
Digging into the [Haystack code base on GitHub]( Which planets are mentioned in the novel?), I could not figure out how to change this behavior, and therefore the document creation step needs to be repeated.
The text chunks need to be created with the following settings to stay consistent with my previous article:
- Embedding format:
ONNXMiniLM_L6_V2model (see also the 10 different embedding models supported by haystack) - Chunk size: 1000
- Chunk overlap: None
The complete ChromaDB setup and ingestion pipeline is shown in the following code:
from haystack.components.converters import TextFileToDocument
from haystack.components.preprocessors import DocumentSplitter
converter = TextFileToDocument()
docs = converter.run(sources=["../ebooks/book1.txt"])
splitter = DocumentSplitter(split_by="word", split_length=1000, split_overlap=0)
chunked_docs = splitter.run(docs['documents'])
Document(id=927c4bb373754826ec5af55cc6f8c6bfaa7cf2962ef2feb6c8c2403b86a6a393, content: 'to read Mercenary’s Star ! The Gray Death Legion, fresh from its victory on Trellwan, takes ship for...', meta: {'file_path': '../ebooks/book1.txt', 'source_id': '5828aceb56fba19d8dc05ddcbd7b279cdd4b22d5025343cc1542004127ee3464', 'page_number': 1}), Document(id=f4613ed6b2399ee2152d98135b9ee250c632316e9e15361901dff02a36154ded, content: 'J. Ciaravella Blood Will Tell by Jason Schmetzer Hunting Season ok1.txt', 'source_id': '5828aceb56fba19d8dc05ddcbd7b279cdd4b22d5025343cc1542004127ee3464', 'page_number': 1})]}
from haystack_integrations.document_stores.chroma import ChromaDocumentStore
roma_db_haystack")
document_store.write_documents(chunked_docs['documents'])
print(document_store.count_documents())
#102
Similarity Search
When the document store is populated, we can perform a similarity search as shown:
from haystack_integrations.document_stores.chroma import ChromaDocumentStore
document_store = ChromaDocumentStore("documents", "ONNXMiniLM_L6_V2", "./chroma_db_haystack")
print(document_store.count_documents())
#102
res = document_store.search(["Which planets are mentioned in the book?"], top_k=3)
print(len(res[0]))
# 3
print(res[0][0])
#Document(id=a2c1ee4a2d489e1596d2b0572e517ea929ac6cca7b7a5080c6ec7496f3918f23, content: 'hours, and Singh’s report would bring the Duke and his armada to Trellwan before another local year ...', meta: {'file_path': '../ebooks/book1.txt', 'page_number': 1, 'source_id': '5828aceb56fba19d8dc05ddcbd7b279cdd4b22d5025343cc1542004127ee3464'}, score: 1.349907398223877, embedding: vector of size 384)
Haystack supports very different LLM Engines. The engine of my choice is Ollama, and it can be used as shown:
from haystack_integrations.components.generators.ollama import OllamaGenerator
generator = OllamaGenerator(
model="llama3",
url = "http://localhost:11434/api/generate",
generation_kwargs={"temperature": 0.1}
)
res = generator.run("What is BattleTech?")
print(res)
# {'replies': ['BattleTech, also known as MechWarrior: BattleTech, is a science fiction franchise ...],
#'meta': [
# {'model': 'llama3',
# 'created_at': '2024-05-20T09: 04: 03.565395Z',
# 'done': True,
# # ...
# }]
# }
RAG Pipeline
Now we can build the complete RAG pipeline. It consists of these steps:
- Load the documents
- Split the documents into 1000-word chunks
- Store the documents inside ChromaDB
- Define an LLM engine
- Define a prompt template with placeholder variables
- Define a retriever component to perform a similarity search on the vector database
- Create a pipeline object that connects the retriever to the prompt, and the prompt to the LLM
Here is the complete code:
from haystack.components.converters import TextFileToDocument
from haystack.components.preprocessors import DocumentSplitter
converter = TextFileToDocument()
docs = converter.run(sources=["../ebooks/book1.txt"])
splitter = DocumentSplitter(split_by="word", split_length=1000, split_overlap=0)
chunked_docs = splitter.run(docs['documents'])
from haystack_integrations.document_stores.chroma import ChromaDocumentStore
document_store = ChromaDocumentStore("documents", "ONNXMiniLM_L6_V2", "./chroma_db_haystack")
print(document_store.count_documents())
from haystack_integrations.components.generators.ollama import OllamaGenerator
generator = OllamaGenerator(
model="llama3",
url = "http://localhost:11434/api/generate",
timeout=240,
generation_kwargs={"temperature": 0.5}
)
from haystack import Pipeline
from haystack.components.builders.prompt_builder import PromptBuilder
from haystack_integrations.components.retrievers.chroma import ChromaQueryTextRetriever
template = """
You are a knowledgeable librarian that answers questions from your supervisor.
Constraints:
- Think step by step.
- Be accurate and precise.
- Answer briefly, in few words.
- Reflect on your answer, and if you think you are hallucinating, repeat this answer.
Context: {{ context }}
Question: {{ query }}?
"""
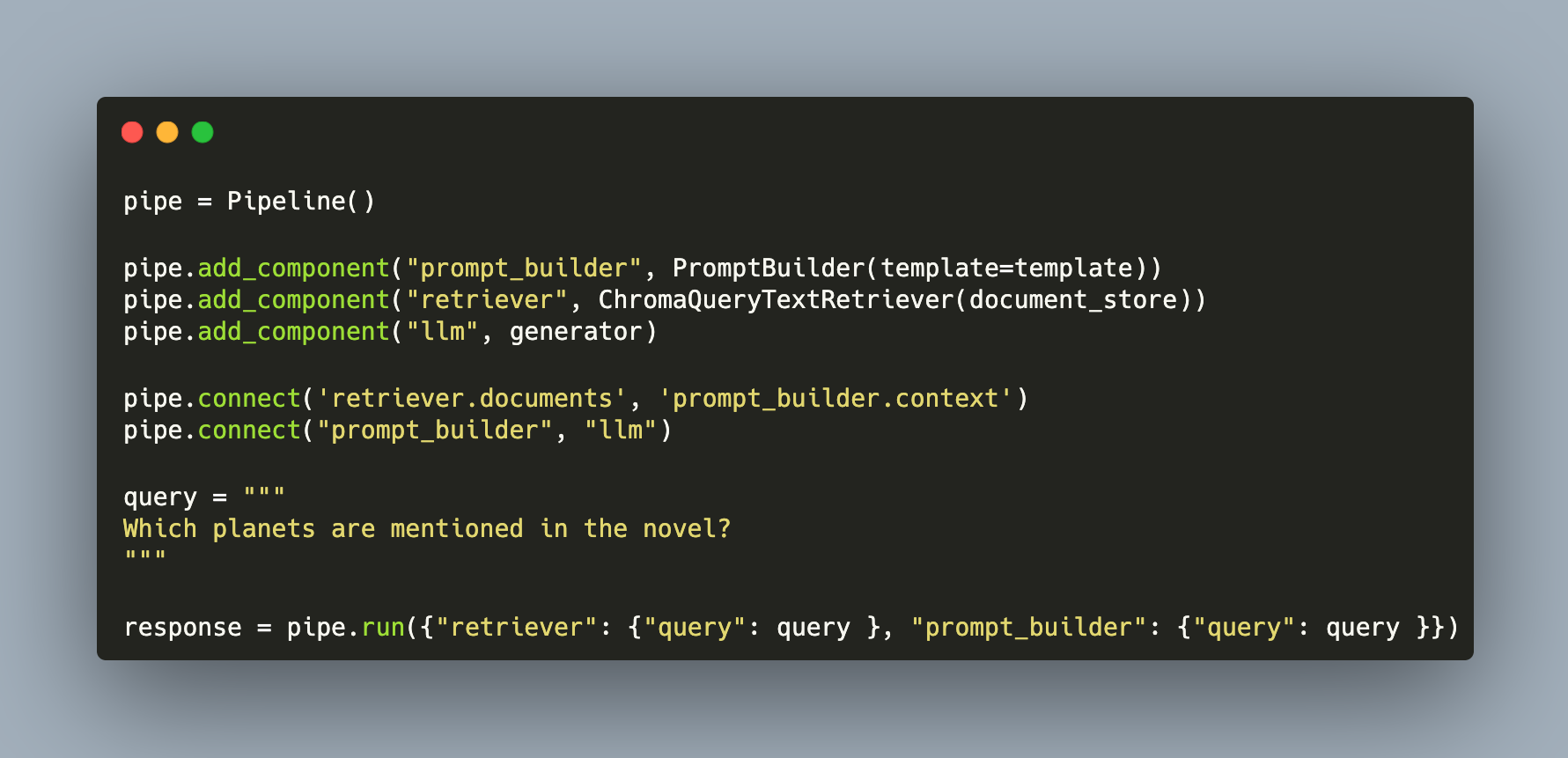
pipe = Pipeline()
pipe.add_component("prompt_builder", PromptBuilder(template=template))
pipe.add_component("retriever", ChromaQueryTextRetriever(document_store))
pipe.add_component("llm", generator)
pipe.connect('retriever.documents', 'prompt_builder.context')
pipe.connect("prompt_builder", "llm")
query = """
Which planets are mentioned in the novel?
"""
response = pipe.run({"retriever": {"query": query }, "prompt_builder": {"query": query }})
print(response['llm']['replies'])
Example
Using the LangChain RAG with a LLaMA 3 model to query about the content of the eBook “Decision at Thunder Rift” revealed these answers:
Q: Who is Singh?
A: A straightforward question! According to the documents provided, Singh appears to be a character in the book "Battletech: Decision at Thunder Rift". Unfortunately, without more context or information about the story, I cannot provide further details about who Singh is or what role they play.
Q: Which planets are mentioned in the novel?
A: A straightforward question! According to my analysis of the provided documents, the planet "Trellwan" is mentioned in the novel.
Q: Which BattleMech was used by Grayson?
A: No specific BattleMech is mentioned as being used by Grayson in the provided documents.
Conclusion
Haystack is a versatile library integrating different LLMs and supporting advanced RAG pipelines. In this blog article you learned how to build a RAG pipeline from scratch by following these steps: a) creating a locally-persisted ChromaDB instance, b) configuring and executing a text-splitter to store chunks in the database, c) perform a similarity search in the persisted data, and d) define a full RAG pipeline that retrieves relevant content from the vector databases, embeds them as a context in an LLM prompt, and invokes the LLM. Comparing Haystack to LangChain, both frameworks support the same use cases, but haystack provides several additional components to clean and convert the content passed along the pipeline. However, the answers provided with the Haystack pipeline are not as good as those from Langchain – even tweaking the models temperature did not help.