Large Language Models have one crucial limitation: They can only generate text determined by the training material that they consumed. To produce accurate and correct facts, and to access recent or additional information, a Retrieval Augmented Generation (RAG) framework is added to the LLM invocation. The basic idea is to fetch relevant content from a (vector)database, optionally transpose or summarize the findings, and the to insert this into the prompt for the LLM. With this, a specific context for the LLM language generation is provided.
In my quest to design a question-answer system, RAG and agents are the most advanced methods. This blog posts starts a series about RAG frameworks. You will learn how to setup a (vector) database that stores text content, how to implement a retrieval from this database given a user query, and finally how to insert this information into a prompt for an LLM. The specific focus of this article is the LangChain framework.
The technical context of this article is Python v3.11 and langchain v0.2.0. All code examples should work with newer library versions too, but may require code updates.
Vector Databases
Before Large Language Models became as popular as they are now, the idea of using vectors to identify similarity between texts or images was around for about 8 years already. Vector databases store vector representations of any content, encoded with an embedding. Using vector arithmetic, the most similar content can be identified and retrieved. And using the embedding, it is transformed to the original data type.
Several commercial and free-to-use vector databases were developed. Looking ahead in this blog post series, I want to use the same database as the backend for all RAG frameworks. At the time of writing this article in May 2024, the status is as shown:
- LangChain: ChromaDB, Fais, Lance
- Haystack: ChromaDB, Milvus, Pinecone, QDrant, Weaviate (+ other text document stores)
- Autogen: ChromaDB, PgVectorDB
As you see, ChromaDB is supported by all frameworks.
Vector Database Setup
ChromaDB can be used in two different ways. Either as a dedicated server or container that exposes the ChromaDB API, or as an in-memory data store that combines the native API and RAG framework specific modifications.
To get a dedicated ChromaDB instance running as a Docker container, the ChromaDB GitHub repository contains all required files. Clone this repository, then start the container with the commands shown:
git clone -b 0.5.0 --depth=1 https://github.com/chroma-core/chroma
cd chroma
docker-compose up -d
When the Docker container is started, you can access it via curl.
curl -vv localhost:8080/api/v1/heartbeat
LangChain provides a dedicated client implementation that can be used to access a ChromaDB server locally or persists the data to a local directory. Although the setup above created a Docker container, I found working with a local directory to be better working, and only considered this option.
Data Ingestion
The next step is to design and implement how the data should be included in the vector databases. This step exposes a magnitude of options that determine how effective the database is for the given tasks. For text data, these aspects include chunk length, the number of tokens that are stored, the chunk overlap, the extend to how much tokens from a previous chunk are included in the current chunk, and which metadata is stored additionally. Another crucial aspect is the embedding format, determining multi-modality and multi-language capabilities. The ChromaDB Python client can be configured to use any embedding model from the HuggingFace Sentence Transformer library. At the time of writing this article, this lists included 6100 entries.
For all of these reasons, a sensible set of defaults need to be defined and applied. The choice is as follows:
- Embedding format: ChromaDB default model
all-MiniLM-L6-v2 - Chunk size: 1000
- Chunk overlap: None
These settings are applied to configure a TextLoader and embedding object in the following code:
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings.sentence_transformer import (
SentenceTransformerEmbeddings,
)
from langchain_text_splitters import CharacterTextSplitter
loader = TextLoader("../ebooks/ebook1.txt")
docs = loader.load_and_split()
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
To create the database and persist it in the ./chroma_db directory, run the following code:
from langchain_chroma import Chroma
db = Chroma.from_documents(docs, embedding_function, persist_directory="./chroma_db")
The persisted db has the following file structure:
chroma_db
├── 6d30a848-4dae-42f8-b7a2-c9a066ec9439
│ ├── data_level0.bin
│ ├── header.bin
│ ├── length.bin
│ └── link_lists.bin
├── b2bcebe2-5b6e-42ac-a921-5842fc759317
└── chroma.sqlite3
Similarity Search
Here is an example how to access the locally persisted ChromaDB store with a similarity search, returning the best matching content:
db = Chroma(persist_directory="./chroma_db", embedding_function=embedding_function)
docs = db.similarity_search("Which planets are mentioned in the book?")
len(docs)
# 4
docs[3]
# Document(
# page_content="activity. Ecology : A few of the wide variety [...],
# metadata={'source': '../ebooks/ebook1.txt'}
# )
RAG Pipeline & LLM Invocation
LangChain can be invoked in the new expression language format, in which interchangeable components are chained into one invocation, or in the classic format by using objects. For the latter option, the object RetrievalQA can be used.
The RAG pipeline is created in five subsequent steps:
- Load the chroma db data
- Create a templated prompt
- Create the LLM instance
- Define the
RetrievalQAobject - Execute the chain
# import
from langchain_chroma import Chroma
from langchain_community.embeddings.sentence_transformer import (
SentenceTransformerEmbeddings,
)
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
print("load_db")
db = Chroma(persist_directory="./chroma_db", embedding_function=embedding_function)
print("done")
template = """
You are a knowledgeable librarian that answers questions from your supervisor.
Constraints:
- Think step by step.
- Be accurate and precise.
- Answer briefly, in few words.
- Reflect on your answer, and if you think you are hallucinating, repeat this answer.
Question: {{ query }}?
"""
from langchain_community.llms import Ollama
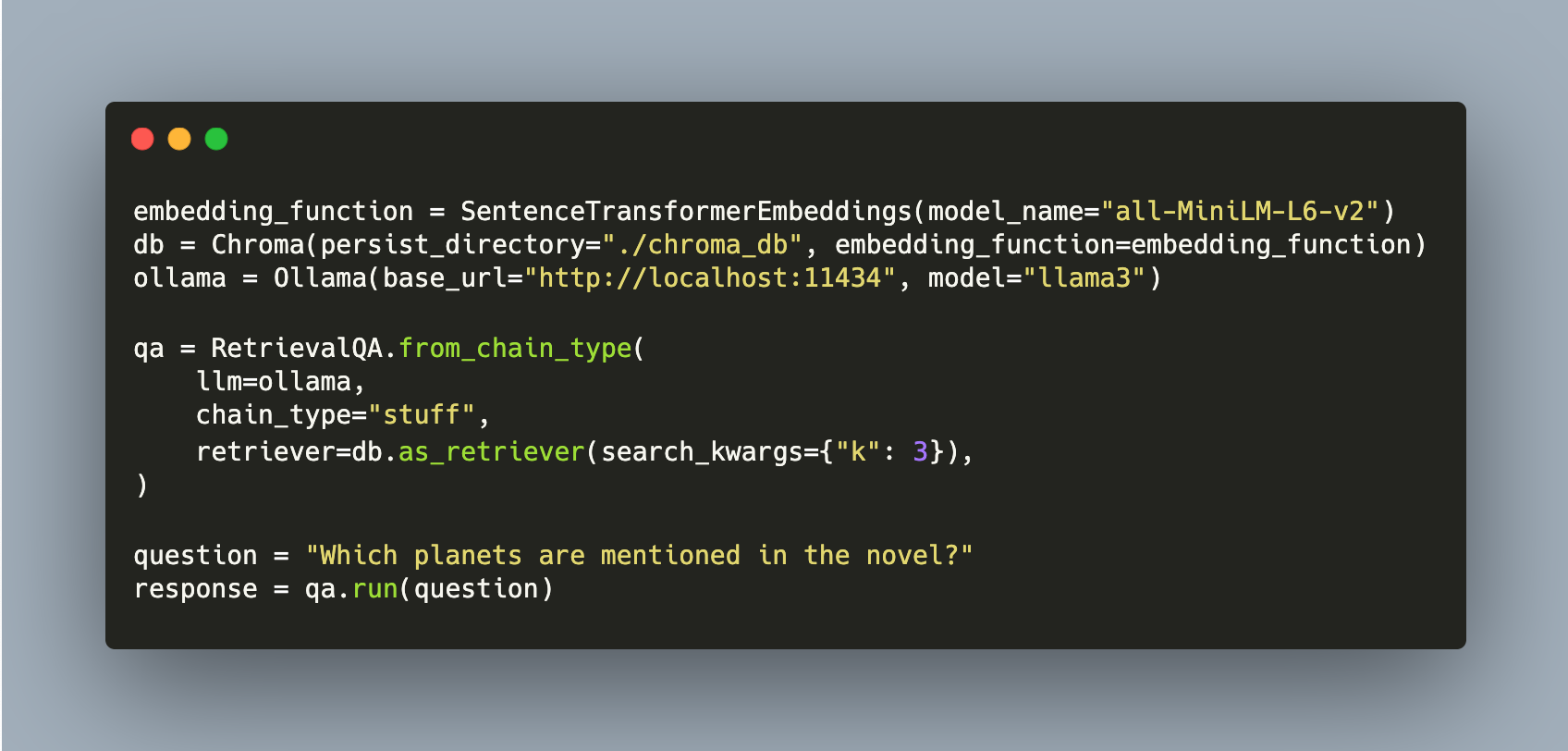
ollama = Ollama(base_url="http://localhost:11434", model="llama3")
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm=ollama,
chain_type="stuff",
retriever=db.as_retriever(search_kwargs={"k": 3}),
)
question = "Which planets are mentioned in the novel?"
response = qa.run(question)
print(response)
Example Execution
Note: Originally, I wanted to use a Project Gutenberg eBooks. But after using several LLMs, I noticed that some of them were trained on these books, and could answer questions without the need of a RAG frameworks. Therefore, I used the novel “Decision at Thunder Rift” from the BattleTech series as the context. You can read a small summary at sarna.net. Yes, I’m aware that this websites content may have been used to train a most recent LLM… .
Using the LangChain RAG with a LLaMA 3 model to query about the content of the eBook “Decision at Thunder Rift” revealed these answers:
Q: Who is Singh?
A: Singh is Harimandir Singh, the leader of the bandits who are attacking the Castle on Trellwan. He is the one who has been working behind the scenes to undermine Grayson's plans and is ultimately responsible for the chaos and destruction that is unfolding on the planet.
Q: On which planets does the novel play?
A: The novel "BATTLETECH LEGENDS: DECISION AT THUNDER RIFT" plays on the planet of Solaris VII and Thunder Rift.
Q: Which BattleMech was used by Grayson?"
A: Grayson used a Shadow Hawk BattleMech.
Conclusion
Retrieval Augmented Generation frameworks help to overcome an LLMs limitation on relevant and up-to-date content. Content is converted to a vector representation, stored in a vector database, and retrieved to be included in the prompt that is send to an LLM. This article is a practical introduction to RAG using the LangChain framework. You learned how to setup the ChromaDB vector database, design the data ingestion code that converts a text into chunks, how to perform a similarity search with the vectorized content, and finally how to design a full RAG pipelines that combines contend extraction, prompt generation and LLM invocation.