
Large Language Models have fascinating abilities to understand and output natural language texts. From knowledge databases to assistants and live chatbots, many applications can be build with an LLM as a component. The capability of an LLM to follow instructions is essential for these use cases. While closed-source LLMs handle instructions very good, pretrained open-source model may not have the skill to follow instructions rigorously. To alleviate this, instruction fine-tuning can be utilized.
This article explores the landscape of fine-tuning. It starts with a high-level description of fine-tuning, then lists instruction data-sets and fine tuning libraries, and ends with evaluation methods and concrete projects. With this overview, you can define and select a concrete combination of applicable tools to jump-start your own fine-tuning project.
The Origin of Instruction Fine-Tuning
A pre-trained LLM typically consumed billions of tokens with the usual goal of predicting a masked word or (autoregressively) the next word in a continuous stream. How these models behave when asked to perform a concrete task is dependent on the quality and number of task-liked texts that were used for training. In the early beginning of LLMs, typical NLP benchmarks were used to determine the models capability, and even earlier, the LLMs needed to be task fine-tuned for just those specific tasks.
During the continued evolution of LLMs, which I covered in earlier blog pots about Gen1 LLMs and Gen2/Gen3 LLMs, several observations were made. Two general observations are a) increasing model complexity and consumed pre-training tokens and b) including high-quality data containing several types of tasks improve LLM capabilities significantly. And a very specific one was shown in the Google research paper Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. In this paper, researchers re-formulate classical NLP tasks like textual entailment, sentence similarity or translations as text-to-text mappings. By training a model with this data, task performance achieved new levels. This first example of instruction fine-tuning for better task generalization became a foundation for all future LLMs as well.
Fine-tuning LLMs is an active and vibrant subject tackled by practitioners, open-source developers and researchers alike. From datasets to training and evaluation, several hubs and libraries exists. In order to understand the available options and make an educated choice for a practical approach, the following sections highlight essential findings, and will support you in architecting your own fine-tuning project.
Datasets
Researchers and open-source communities published several freely available instruction fine-tuning datasets. A comprehensive and complete overview is given in the GitHub repositories |awesome-instruction-datasets and Awesome-instruction-tuning.
Considering datasets used in academic research, the following picture shows the dataset evolution.
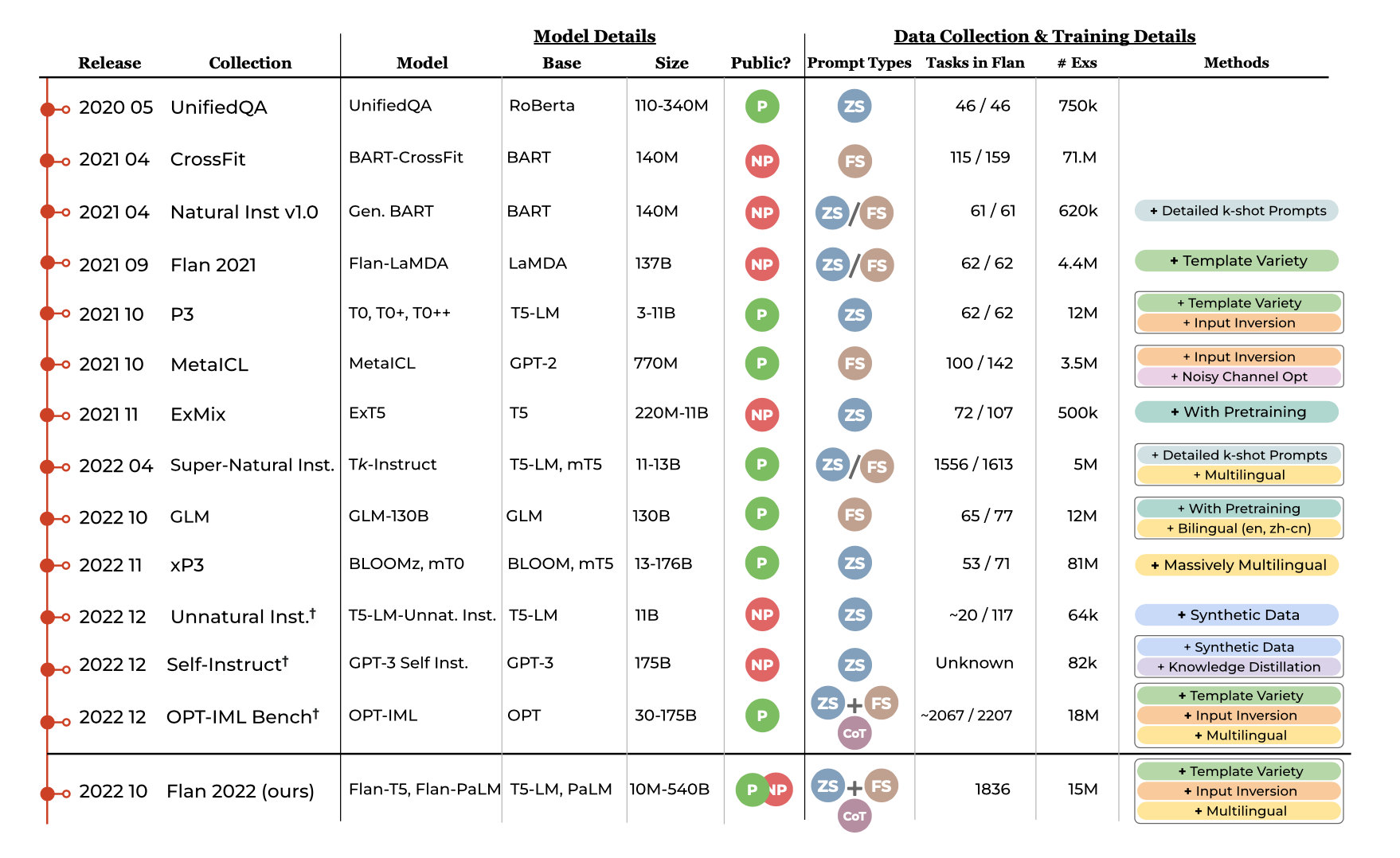
Source: The Flan Collection: Designing Data and Methods for Effective Instruction Tuning, https://arxiv.org/abs/2301.13688
The most important academic research datasets are these:
- Natural Instructions: This dataset contains 1500 tasks, including question answering, summarization, fact generation, answer and question checking, and direct language translations for several language pairs.
- P3: This public data set was used to evaluate prompt formatting and training of the T0 evaluation models. It contains a rich set of tasks, mostly classical NLP tasks like question answering, classification and interference from sources like Wikipedia and Yelp.
- FLAN: A master dataset including and combining different other sets. It contains 1826 tasks in a standard prompt, including instructions that invoke chain-of-thoughts reasoning for the target model.
While these sets are manually curated, the current trend is to use a powerful LLMs, like GPT3.5 and GPT4, to generate instruction fine-tuning prompts and answers automatically. In this category, the following sets are recommended:
- Alpaca Stanford: A 52K dataset created with GPT3.5, containing prompts formatted according to OpenAI prompt engineering methods. The task span areas such as summarizing, editing and rewriting text, as well as given explanations or performing calculations.
- Guanaco: A multilingual dataset that extends the Alpaca data with tasks for grammar analysis, language understanding, and self-awareness.
- Self Instruct: A large synthetic dataset that was created with GPT, it includes 52k instructions and 82k input/output mappings. Furthermore, the research paper shows a methodology to allow an LLM to self-improve by using the model’s output for data generation.
Training and Fine-Tuning Libraries
Fine-tuning an LLM modifies the model weights and/or add new layers to it. For instruction-finetuning, the essential steps remain: Convert input text to tokens, generate next best-word output probability, convert the token to an output string, and then compute a metric to determine the backward propagation gradient. These steps are repeated until the given metric does not improve anymore.
While any generic fine-tuning library can be used, the importance and observed LLM capability improvements of instruction-fine tuning created its own library ecosystem. However, one big obstacle needs to be scaled. A full re-training of an LLM with 7B parameters or greater requires substantial computing resources, several GPUs with 40GB memory and more are required.
The answer to this challenge is quantization - methods that reduce the amount of memory and computational costs by compressing and transforming an LLM. These methods are summarized with the term Parameter Efficient Fine-Tuning. Two most prominent ones are:
- Lora: In the Low-Rank Adaption approach, an LLMs weights matrix is decomposed into two smaller matrixes. The smaller matrixes are projections, their multiplication represents the complete matrix. These smaller matrixes can be exposed for fine-tuning, leading to delta-updates of the original weights. For a very readable explanation, check How to fine-tune a Transformer (pt. 2, LoRA).
- Adapters: A technique in which an LLMs layers are frozen, but additional small layers inserted and then trained. By training the adapters only, the fine-tuning process becomes computational efficient, and furthermore, adapters can be combined to converge single fine-tuned models to a common one.
A full explanation and comparison of available methods is explained in the paper Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning. The following picture gives an indication to the available scope:
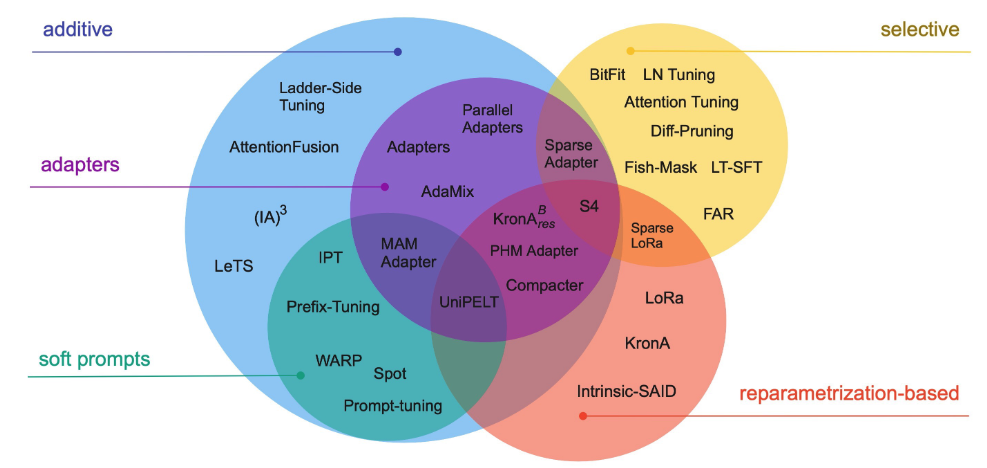
The combination of interest into fine-tuning and availability of quantization libraries makes effective fine-tuning on consumer grade hardware possible. Following libraries can be used:
- transformer trainer: With the quintessential transformer library, loarding LLMs and their tokenizer becomes only a few lines of Python code. On top of this, the
trainerobject facilitates the definition of all training hyperparameters, and then runs distributed training on several nodes and GPUs. - bitsandbytes: A wrapper for an PyTorch-compatible LLM such as the transformer model. It provides 8-bit and 4-bit quantization, reducing the required RAM or GPU-RAM amount tremendously.
- peft: An umbrella library that implements many state-of-the art quantization methods discovered in scientific research. Concrete methods are explained in the documentation, most notably soft prompts and infused adapters.
- trl: An acronym for Transformer Reinforcement Learning, it provides essential abstractions for incorporating reinforcement learning techniques. Specifically, following steps are applied: a) supervised fine-tuning, in which datasets with expected labels are contained. b) reward modeling, in which training data is separated into accepted and non-accepted answers. c) proximal policy optimization, from the same-named research paper, which is an algorithm applied to the reward model application to the generations of the model.
Evaluation Libraries
LLMs generate sophisticated texts. Since their inception, text generation capabilities were measured. Initially with typical NLP benchmarks like SQUAD for question-answering or QNLI for natural language interference. Recently with knowledge-domain spanning tests, like questions about economics, biology and history up to complete high-school admission tests, and also measuring language toxicity.
To make these measurements transparent and reproducible, several libraries were created.
- instruct-eval: Model evaluation and comparison for held-out instruction datasets. This library strongly integrates with transformers to load causal LM (autoregressive decoder-only) and sequence-to-sequence (encoder-decoder models) LM checkpoints. It also covers aspects like LLM security (jail-breaking LLM prompts), writing capability of LLMs (informative, professional, argumentative, and creative)
- evaluation-harness: Framework for testing LLMs on 60 different tasks. Integrates with transformers and the quantization libary
peft. and all models that can be accessed via OpenAI API (which opens the door to use ollama.ai and similar local hosting libraries too). Opinioned training library with PyTorch bare metal instructions: - HELM: This framework combines several accepted evaluation datasets from scientific papers, such as natural questions, openbook question answering, and massive multi-task language understanding. Additionally, other language metrics like efficiency, bias, and toxicity can be measured. The library can be used to evaluate a continuously growing list of both closed and open-source models, and it integrates with transformer models that expose causal language modelling features.
Projects and Notebooks
To complete this research article, the following lists shows very concrete examples how to fine-tune Gen2 and Gen3 LLMs.
- LLaMA: Fine tuning with chat data using quantized LORA and supervised fine-truning training.
- LLaMA2 This notebook shows how to fine-tune a 7B LLaMA 2 model with a 16GB GPU. The specific libraries resolve around the Huggingface ecosystem:
transformers,accelerate,peft,trl, andbitsandbytes. - MPT: The MPT model from mosaic is a fully open-source model with a performance like LLaMA. This notebook shows how to apply LORA adapters that for fine-tuning with a chat-interaction dataset.
- OPT: In this notebook, Metas OPT model is used, and LORA adapters trained on an example dataset. The notebooks shows how to export only these trained adapters, and how to load them to instantiate a quantized model for evaluation.
Conclusion
In this article, you learned about the landscape of instruction fine-tuning of LLMs. You learned about datasets, quantization methods, fine-tuning libraries, and concrete projects. Effective fine-tuning can be achieved by loading a quantized models (reduces RAM storage) and parameter efficient fine-tuning methods (only re-adjusting partial weights or a weights representation). This quantized model can then be evaluated on a broad, task-agnostic benchmark yielding relative performance scores on a wide array of different tasks. With this landscape uncovered, a specific combination of datasets and libraries can be made. The next article show a practical example for fine-tuning a LLaMA 2 model.