Large Language Models are a fascinating technology capable of many classic and advanced NLP tasks, from text-classification and sentiment analysis to reading comprehension and logical interference. During their evolution, starting with Gen1 in 2018 with model like GPT and Bert, to Gen4 2024 models like GPT-4 and LLAmA2, they have gained significant skills and capabilities.
My goal is to understand and design closed-book question answering systems with the help of LLMs. In a previous article, I identified seven different approaches. This article is the first, exploring fine-tuning a Gen1 LLM.
Specifically, this article shows how to fine-tune a GPT-2 model with the Corpus of Linguistic Acceptability dataset from the GLUE benchmark. You will learn how to structure these goals into phases similar to other machine learning projects, understand the data structure of the training dataset, see how to tokenize the dataset, and then to train the model. Each step lists the essential Python source code too.
The technical context of this article is Python v3.11 and transformers v4.37.2. All instructions should work with newer versions of the tools as well.
LLM Fine Tuning Process
Large Language Models are neural networks with the transformer architecture. Fine-Tuning changes either the models architecture, e.g. by adding additional layers following the transformer blocks, or it changes the models parameter, its weights and biases. To understand all available options, also see my earlier article about Fine-Tuning Transformer Language Models.
In principle, fine-tuning steps resemble a machine learning project. It starts with the definition of the goal, selects and review the training dataset, preprocessing, training setup and execution. In the specific context of an LLM, these steps are as follows:
- Goal Definition: Define the concrete NLP tasks or skill that you want to add or improve on the LLM. You also select which LLM you want to use.
- Data Selection & Exploration: Selection and inspection of the dataset to understand how the text is formatted, and also to identify data errors and missing values
- Data Preprocessing: An essential step to ensure the dataset is compatible with the LLM. Most important is correct tokenization, special token insertion (e.g. in BERT, use the
[CLS]token at the beginning of a sentence to communicate the intention of the training), and removing tokens not contained in the vocabulary. Finally, split the dataset into train, validation and test. The train and test dataset are used to evaluate how good the model performs its tasks, and the validation dataset is used to compare the performance of several models to find the best overall candidate, - Training Parameter Definition: Define the type of modifications for the LLM, and determine training hyperparameter like the learning rate. Also, the training metrics needs to defined.
- Training Execution: The actual training of the model with the defined hyperparameters. Also, available CPU, RAM and GPU resources are utilized effectively without any configuration.
- Model Usage & Deployment: Test the model and persist it into an executable form.
These steps might seem daunting, a lot happened since 2018. Looking back to articles like Fine-tuning a BERT model or BERT Fine-Tuning Tutorial with PyTorch show how many manual considerations were needed, and how many different libraries were required. But since then, interest into LLM and library support increased by huge margins, resulting in sophisticated libraries that solve many details.
LLM Fine Tuning with the Transformers Library
HuggingFace Transformers, and additional libraries from the same manufacturer, provide an integrated API for dataset preparation, training parameter definition and training execution. Essentially, above tasks are supported as follows:
- Data Selection & Exploration: Preprocessed datasets are available with an integrated downloader
- Data Preprocessing: With the help of
AutoTokenizers, the tokenization rules required for an LLM are automatically applied to the input data. Padding and truncating need to be implemented manually, but can be defined as custom functions that are supplied to the tokenizer. Also, the train, test and validation split is done automatically. - Training Parameter Definition: Sensible default training parameters, derived from a long period of experiences, are automatically created. These parameters reflect the kind of NLP tasks that should be solved (e.g. text classification or question answering), and a goal-specific metric can be defined manually too.
- Model Training Execution: The training step utilize that target computer(s) available CPU, RAM and GPU resources without any configuration.
- Model Usage & Deployment: The trained model consists of files that represent its parameters. This representation can be used with the Transformers library as-is, and it can be converted to other executable formats.
For me, it remains intellectually vexing to fine-tune a model from scratch. But in this article, the transformer library will be used.
To follow along all code examples, run this command:
poetry init --quit
poetry add transformers@4.37.2 datasets@2.17.0 jupyter@1.0.0 evaluate@0.4.1 scikit-learn@1.4.1.post1 torch@2.2.0
Step 1: LLM Fine-Tuning Goal Definition
The goal is to fine-tune the GPT-2 model with additional linguistic skills to increase its capAbility for question-answering. The following code shows how to use this model and ask a question about the space agency NASA given the first two paragraphs from the official Wikipedia article.
from transformers import pipeline
model_name = 'openai-community/gpt2'
model = pipeline(
"question-answering", model=model_name
)
query = {
"question": "What is NASA?",
"context": '''
The National Aeronautics and Space Administration (NASA) is an independent
agency of the U.S. federal government responsible for the civil space
program, aeronautics research, and space research. Established in 1958, it
succeeded the National Advisory Committee for Aeronautics (NACA) to give
the U.S. space development effort a distinctly civilian orientation,
emphasizing peaceful applications in space science.[4][5][6] It has since
led most American space exploration, including Project Mercury, Project
Gemini, the 1968–1972 Apollo Moon landing missions, the Skylab space
station, and the Space Shuttle. It currently supports the International
Space Station and oversees the development of the Orion spacecraft and the
Space Launch System for the crewed lunar Artemis program, the Commercial
Crew spacecraft, and the planned Lunar Gateway space station.
NASA's science is focused on better understanding Earth through the Earth
Observing System;[7] advancing heliophysics through the efforts of the
Science Mission Directorate's Heliophysics Research Program;[8] exploring
bodies throughout the Solar System with advanced robotic spacecraft such as
New Horizons and planetary rovers such as Perseverance;[9] and researching
astrophysics topics, such as the Big Bang, through the James Webb Space
Telescope, the Great Observatories and associated programs.[10] The Launch
Services Program oversees launch operations and countdown management for
its uncrewed launches.
'''
}
answer = model(query)
print(answer)
The answer depends on the model temperature - it gave me the following answer:
{'score': 0.0027772255707532167, 'start': 304, 'end': 369, 'answer': '.S. space development effort a distinctly civilian orientation,\n\t'}
Step 2: Data Selection & Exploration
The General Language Understanding Evaluation, or short GLUE, is an universal benchmark consisting of human-annotated datasets. It covers a variety of advanced NLP tasks, including text generation, knowledge & interference, and natural language understanding. One task is the Corpus of Linguistic Acceptability, in which a short sentence classified as either linguistically acceptable or not acceptable.
The original dataset, available from the GLUE homepage, contains a list of sentences, 5 different votes from human observer about its linguistic acceptability, and a final label. Here is an example. Cleary, the first sentence is acceptable, and the second is not.
1 1 1 1 1 1 I served my guests.
0 * 0 0 0 0 0 He can will go
Let’s load this dataset with the transformers library. For this, we need to lookup the dataset name as well as the relevant slice from the dataset browser.
from datasets import load_dataset
data = load_dataset('glue', 'cola')
# Downloading readme: 100%|████████████████████████████| 35.3k/35.3k [00:00<00:00, 30.0MB/s]
# Downloading data: 100%|█████████████████████████████████| 251k/251k [00:00<00:00, 669kB/s]
# Downloading data: 100%|███████████████████████████████| 37.6k/37.6k [00:00<00:00, 217kB/s]
# Downloading data: 100%|███████████████████████████████| 37.7k/37.7k [00:00<00:00, 208kB/s]
# Generating train split: 100%|█████████████| 8551/8551 [00:00<00:00, 1077074.19 examples/s]
# Generating validation split: 100%|█████████| 1043/1043 [00:00<00:00, 508031.48 examples/s]
# Generating test split: 100%|███████████████| 1063/1063 [00:00<00:00, 430195.40 examples/s]
The first time when a new dataset is loaded, source and configuration files will be downloaded and stored on your computer, then they are available in other projects too. Inspect the dataset’s data structure with a simple print.
print(data)
# DatasetDict({
# train: Dataset({
# features: ['sentence', 'label', 'idx', 'input_ids', 'attention_mask'],
# num_rows: 8551
# })
# validation: Dataset({
# features: ['sentence', 'label', 'idx', 'input_ids', 'attention_mask'],
# num_rows: 1043
# })
# test: Dataset({
# features: ['sentence', 'label', 'idx', 'input_ids', 'attention_mask'],
# num_rows: 1063
# })
# })
As you see, this set is already split into train, validation, and test. Lets see two examples from the training dataset.
print(data['train'][0])
# {'sentence': "Our friends won't buy this analysis, let alone the next one we propose.", 'label': 1, 'idx': 0}
print(data['train'][42])
# {'sentence': 'They made him to exhaustion.', 'label': 0, 'idx': 42}
Each data item consists of an idx identfier, the sentence and a label where 1 means accepted and 0 means not accepted.
Step 3: Data Preprocessing
The training data needs to be tokenized following the models’ tokenization scheme. When using a model with the Transformers libary, the AutoTokenizer object will do all the heavy lifting: Adding special control tokens, and removing any input tokens that are not part of the models vocabulary. We need to define a tokenization method and decide the padding and truncation.
tokenizer=AutoTokenizer.from_pretrained(model_name)
def tokenize_dataset(dataset):
return tokenizer(dataset['sentence'], padding='max_length', truncation=True)
The tokenizer is applied as follows.
tokenized_data = cola.map(tokenize_dataset, batched=True)
And the tokenized dataset examples are these:
print(tokenized_data['train'][0])
# {'sentence': "Our friends won't buy this analysis, let alone the next one we propose.", 'label': 1, 'idx': 0, 'input_ids': [5122, 2460, 1839, 470, 2822, 428, 3781, 11, 1309, 3436, 262, 1306, 530, 356, 18077, 13], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
Step 4: Training Parameter Definition
Training Hyperparameters
Default and sensible training parameter are provided by just instantiating a TrainingArguments object.
training_args = TrainingArguments(output_dir="gpt2_linguistic_finetuning")
Lets see some of the default arguments:
print(training_args)
# TrainingArguments(
# _n_gpu=0,
# adafactor=False,
# adam_beta1=0.9,
# learning_rate=5e-05,
# load_best_model_at_end=False,
# log_level=passive,
# max_grad_norm=1.0,
# max_steps=-1,
# num_train_epochs=3.0,
# optim=OptimizerNames.ADAMW_HF,
# optim_args=None,
# output_dir=test_trainer,
# per_device_eval_batch_size=8,
# per_device_train_batch_size=8,
# remove_unused_columns=True,
# report_to=['tensorboard'],
# resume_from_checkpoint=None,
# seed=42,
# torch_compile=False,
# torchdynamo=None,
# warmup_ratio=0.0,
# warmup_steps=0,
# weight_decay=0.0
# )
Metrics Definition
To compare two models, a metric need to be defined. This metric is a function that receives a trained model, usually referred to as a checkpoint during training, and calculates a total score based on the validation dataset.
For the Corpus of Linguistic Acceptability, this metric is Mathews Cors. You can read the involved math’s on wikipedia and roll your own function, or use a built-in-function.
import evaluate
metric = evaluate.load("glue", "mrpc")
MetricS needs be wrapped in a metrics computation function, which will then be used during the training process.
def compute_metrics(eval_preds):
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
Step 5: Training Execution
For the training execution to start, define a DataCollator object. This is not a typo - “collate” means to sort and proof datasets. This object wraps the tokenized data and creates the final batches for the trainer.
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
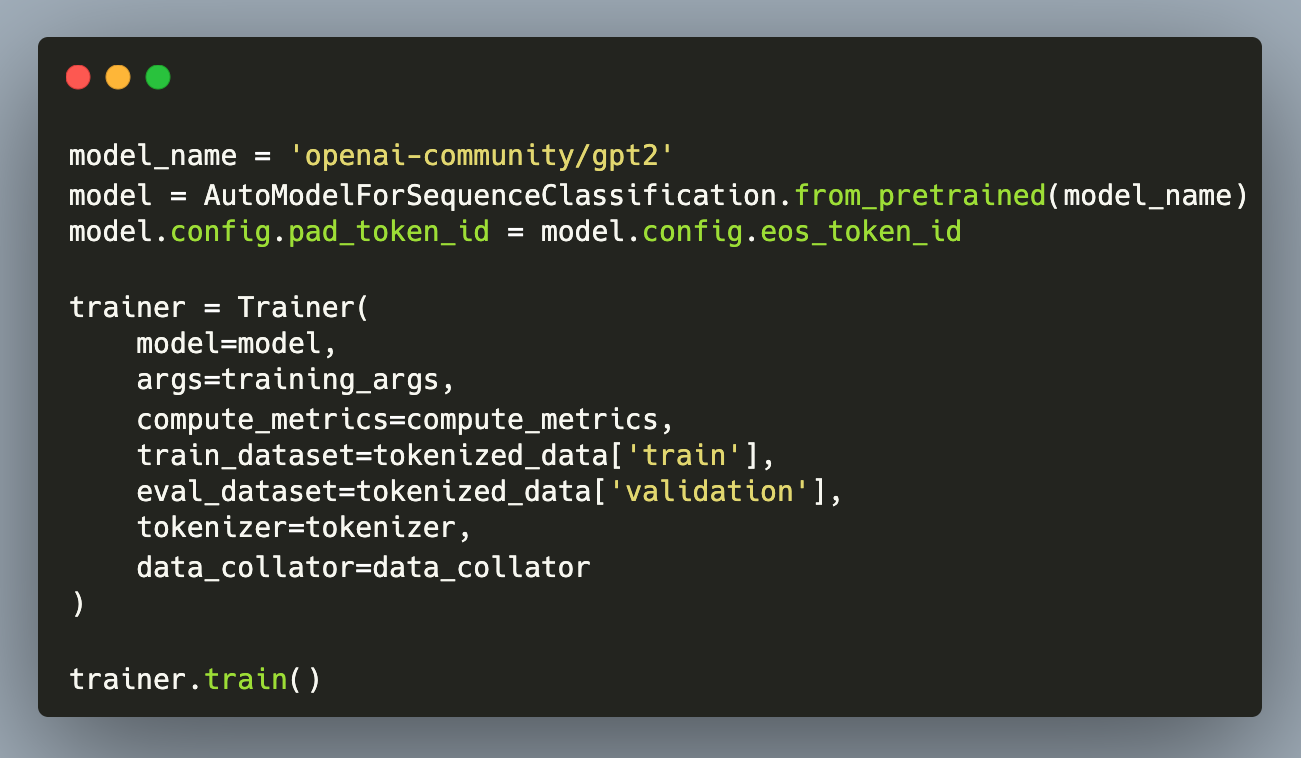
And one more object is needed: The model itself. This model needs to be loaded as a sequence classification model with this snippet:
model = AutoModelForSequenceClassification.from_pretrained(model_name)
Finally, all pieces to create the trainer object are completed, and the training can start.
model = AutoModelForSequenceClassification.from_pretrained(model_name)
trainer = Trainer(
model=model,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=tokenized_data['train'],
eval_dataset=tokenized_data['validation'],
data_collator=data_collator,
tokenizer=tokenizer
)
trainer.train()
During training, you will see several log messages indicating progression, including the number of epochs that are trained, and the metrics being calculated.
# Step Training Loss
# You're using a GPT2TokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
# ...
# {'loss': 0.6299, 'learning_rate': 4.2204552541315874e-05, 'epoch': 0.47}
# 16%|███████▋ | 517/3207 [13:51<1:12:46, 1.62s/it]
# ...
# {'loss': 0.6299, 'learning_rate': 4.2204552541315874e-05, 'epoch': 0.47}
# {'loss': 0.6069, 'learning_rate': 3.4409105082631746e-05, 'epoch': 0.94}
# {'loss': 0.524, 'learning_rate': 2.6613657623947615e-05, 'epoch': 1.4}
# {'loss': 0.4908, 'learning_rate': 1.8818210165263487e-05, 'epoch': 1.87}
# {'loss': 0.3874, 'learning_rate': 1.1022762706579358e-05, 'epoch': 2.34}
# {'loss': 0.3571, 'learning_rate': 3.2273152478952295e-06, 'epoch': 2.81}
# {'train_runtime': 5085.7487, 'train_samples_per_second': 5.044, 'train_steps_per_second': 0.631, 'train_loss': 0.4906835505476911, 'epoch': 3.0}
# 100%|███████████████████████████████████████████████| 3207/3207 [1:24:45<00:00, 1.59s/it]
# Finish training
Note: Two tutorials detail alternative training environments, see Train in native PyTorch and Train a TensorFlow model with Keras.
Step 6: Model Usage & Deployment
When the training is finished, you can save any of the checkpoints or the last model:
trainer.save_model('gpt2_linguistic_fft')
Model Files
Trained models are essentially PyTorch models with additional configuration files. Lets take a closer look to the data:
.
├── config.json
├── merges.txt
├── optimizer.pt
├── pytorch_model.bin
├── rng_state.pth
├── scheduler.pt
├── special_tokens_map.json
├── tokenizer.json
├── tokenizer_config.json
├── trainer_state.json
├── training_args.bin
└── vocab.json
Both pytorch_model.bin and training_args.bin are binary files, but the others show interesting information. Here are the details of some files
config.json: Contains the complete model configuration, detailing its type, its architecture (number of layers, dimensions etc.) and the specific use case for which this model was trained.
"model_type": "gpt2",
"n_head": 12,
"n_layer": 12,
"pad_token_id": 0,
"pad_token_id": 50256,
"problem_type": "single_label_classification",
special_tokens_map.json: A mapping for all tokens specifically used by this model
{
"eos_token": "<|endoftext|>",
"pad_token": "[PAD]",
"unk_token": "[UNK]"
}
tokenizer.json: The complete static settings of the tokenizer, detailing the truncation and padding settings, a list if added tokens, the normalizer, and the tokenizer model with a list of all tokens.
{
"version": "1.0",
"truncation": null,
"padding": null,
"added_tokens": [
{
"id": 50256,
"content": "<|endoftext|>",
"single_word": false,
"lstrip": false,
"rstrip": false,
"normalized": false,
"special": true
}
],
"normalizer": null,
"pre_tokenizer": {
"type": "ByteLevel",
"add_prefix_space": false,
"trim_offsets": true,
"use_regex": true
},
"post_processor": {
"type": "ByteLevel",
"add_prefix_space": true,
"trim_offsets": false,
"use_regex": true
},
"model": {
"type": "BPE",
"dropout": null,
"unk_token": null,
"continuing_subword_prefix": "",
"end_of_word_suffix": "",
"fuse_unk": false,
"byte_fallback": false,
"vocab": {
"!": 0,
"\"": 1,
"#": 2,
"$": 3,
"%": 4,
"&": 5,
"'": 6,
tokenizer_config.json: Contains the tokenizers applied configuration properties:
{
"add_prefix_space": false,
"bos_token": "<|endoftext|>",
"clean_up_tokenization_spaces": true,
"eos_token": "<|endoftext|>",
"model_max_length": 1000000000000000019884624838656,
"tokenizer_class": "GPT2Tokenizer",
"pad_token": "[PAD]",
"unk_token": "[UNK]"
}
Model Usage
To use a pre-trained model, the simplest approach is to define a pipeline object for the intend task. Just as with other transformer abstractions, this will simplify the invocation tremendously, starting with tokenizing the input, generating the output, decoding the output, and mapping the output to a label.
The Corpus of Linguistic Acceptability tasks is essentially a binary classification into acceptable and non-acceptable tasks. And therefore, the text-classification pipeline is the most suitable.
But first, let’s find sentences from the train and validation dataset with two different labels.
not_acceptable = dataset["validation"][30]
acceptable = dataset["validation"][31]
Then, define the text-classification pipeline …
from transformers import pipeline
fft_model_name = "gpt2_linguistic_fft"
classifier = pipeline(
"text-classification", model=gpt2_linguistic_fft
)
… and apply it:
classifier(dataset["validation"][29]['sentence'])
# [{'label': 'LABEL_0', 'score': 0.9874629378318787}]
classifier(dataset["validation"][30]['sentence'])
# [{'label': 'LABEL_1', 'score': 0.9579135775566101}]
This looks good. Now, let’s try it with invented data too.
classifier("sea I hill this top")
# [{'label': 'LABEL_0', 'score': 0.9955822825431824}]
classifier("See a hill on top")
# [{'label': 'LABEL_1', 'score': 0.9911277294158936}]
The results are quite convincing.
Question Answering with the Finetuned Model
Now let’s see how the linguistically fine-tuned version of the model performs in the question-answering task.
from transformers import pipeline
fft_model_name = "gpt2_linguistic_fft"
model = pipeline(
"text-classification", model=fft_model_name
)
answer = model(query)
print(answer)
Using the same query as in the introduction, the model gives other answers:
{'score': 0.001063833711668849, 'start': 297, 'end': 306, 'answer': '\n\tthe U.S'}
I must admit that I do not see a positive improvement, but this was just the first fine-tuning approach.
Conclusion
This article detailed the fine-tuning steps and process of the GPT2 LLM for improving its skills on linguistic acceptance with the GLUE dataset. You learned that LLM fine-tuning follows the same development steps as other machine learning models, with a special focus on data set selection and preprocessing. Leveraging the Transformers library, many aspects are covered out-of-the box including tokenization and train-test-validation split of the input data, and batch processing the training with utilizing the targets computer CPU and GPU flexible. The resulting model consists of configuration files and binary, which can be used as-is and converted to other formats too. The final comparison between the base model and the fine-tuned model in a question answering task did not show a convincing progress – but this was only the first approach, and more follow in the next articles.