Large Language Models (LLMs) are neural networks trained on terabytes of input data that exhibit several emergent behaviors with which advanced semantic NLP tasks like translation, question answering, and text generation evolve from the model itself without any further finetuning. This remarkable feature has given them the name Foundation Models, language models capable to push the frontier of NLP to almost human-level language competence.
One of the most popular LLM library is LangChain. It facilitates LLM loading and usage from several sources, and it provides convenient abstractions for managing complex prompts with user-defined input data. LangChain code is a flexible wrapper around LLM APIs, simplifying swapping concrete LLMs without much code change, and it provides additional abstractions like adding conversational memory or tools that fetch data from different sources that is used to create LLM input. With this foundation, creating sophisticated LLM applications becomes both versatile and easy.
This blog post is an introduction to LangChain. First, you will learn how to install and configure a Python project with LangChain. Second, you will see how all classical syntactic and semantic NLP tasks can solved with the powerful prompt management feature. All examples are defined as ready-to-use code snippets.
The technical context of this article is Python v3.10 and langchain v0.0.236. The examples should work with newer versions too.
Installation and Library Overview
The installation is a one-liner invoking pip:
pip install langchain
Other than that, you need to have access to one of the supported LLMs, which can be either locally installed or available via an API. At the time of writing, more than 48 LLMs are supported, including models from HuggingFace Hub, OpenAI and LLama.
LangChain provides a thin wrapper around any LLMs - basically a short configuration of model name, temperature, and an API key. For example, to start using OpenAI, the following lines are sufficient:
from langchain.llms import OpenAI
llm = OpenAI(
temperature=0.9,
model_name="text-babbage-001",
openai_api_key=os.environ.get("OPENAI_API_KEY")
)
llm.predict("What is AI?")
'Artificial intelligence (AI) is a field of computer science and machine learning that creates algorithms that can learn and recognize patterns and relationships in data sets.'
The input to an LLM model can be a simple string as shown above, or a more complex prompt consisting of the context, the desired speech style, and the concrete task that a user wishes to accomplish. Managing prompts effectively, and providing reusable templates, is a core feature of LangChain. And with this, many advanced NLP tasks boil down to provide the correct combination of prompts and data augmentation tools.
Introduction: Invoking LangChain with OpenAI
Most of LangChain examples and code snippets use OpenAI, and it will be my LLM of choice for the remainder of this article.
To use an OpenAI model, you need to have a registered account and generate an API key.
To invoke an LLM, a thin wrapper around a hosted LLM API is used, and then any prompt can be used to query a model. Here is an example for using the OpenAI API:
from langchain.llms import OpenAI
llm = OpenAI(
temperature=0.9,
model_name="text-babbage-001",
openai_api_key=os.environ.get("OPENAI_API_KEY")
)
text = '''
What is a good name for online blog which writes about DevOps best practices?
'''
llm.predict(text)
'DevOps Edge'
Take a special look at the model parameter - you need to choose and provide a model name that is appropriate for the task at hand. With OpenAI, the differentiation is about the endpoints. The /v1/completions hosts GPT3 derivates (the davinci, curie, babbage and ada models.), but is also considered deprecated at the time of writing this article. The /v1/chat/completions enables GPT3.5 and GPT4.0 variants - and only these are usable to provide the chat functionality. See the complete model list.
The LangChain wrapper for OpenAI is shown in the following example:
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
chat = ChatOpenAI(
temperature=0.0,
model_name="gpt-3.5-turbo",
openai_api_key=os.environ.get("OPENAI_API_KEY")
)
chat.predict_messages(
[
HumanMessage(content="Please help me to translate this text from English to Japanese: I'm working as a DevOps Engineer")
]
)
AIMessage(content='私はDevOpsエンジニアとして働いています。', additional_kwargs={}, example=False)
With prompts, the context of larger conversations is determined. Prompt templates are text abstraction in which dynamic input can be inserted during the invocation of an LLM. These prompts should be written with consulting the LLMs help pages - for OpenAI, see the effective prompts documentation.
Continuing with the example of language translation, the following template defines placeholder for the origin and target language, as well as the input sentence.
from langchain.prompts import PromptTemplate
translation_prompt = PromptTemplate.from_template('''
Translate the following text from {origin_language} to {target_language}.
Text: """
{input_text}
"""
''')
Then, the prompt can be just configured with any language combination and text that is required. The following example invokes the prompt for an English to a Japanese translation.
t = translation_prompt.format(
origin_language = "english",
target_language = "japanese",
input_text = "DevOps best practices facilitate continuous deployments",
)
llm.predict(t)
\nデヴオップスのベストプラクティスは、連続的なデプロイメントを促進します。
All of LangChain abstractions - the chat models, the prompts, and the tools (covered later) - can be wrapped in a chain. A chain is both a convenient wrapper and parametrizable, e.g. key-value pairs are defined and passed to prompts.
To define and invoke the language translation task, following code is required:
from langchain.chains import LLMChain
chain = LLMChain(
llm = llm,
prompt=translation_prompt
)
chain.run(origin_language = "english",
target_language = "japanese",
input_text = "DevOps best practices facilitate continuous deployments",
)
\nデヴォップスのベストプラクティスは、連続的なデプロイメントを促進します。
And with these corner stones, most of the semantic NLP tasks can be solved with an effective prompt and chain invocation of a powerful LLM. To be honest, the following tasks could be achieved with LangChain by directly using a dedicated API of an LLM. But with LangChain you gain the flexibility to switch to another LLM with few lines of configuration.
NLP Tasks
By using LangChain with prompts that follow the OpenAI effective prompts documentation, following NLP tasks can be implemented:
- Token Classification
- Text Classification
- Summarization
- Translation
- Question Answering
- Text Generation
- Dialog
Overall, I was very impressed with the results, and most times already the very first prompt generated the expected results.
The following sections only show the prompt definition, its invocation in a chain and the result. To run them, the following boilerplate needs to be defined as well:
from langchain import OpenAI, ConversationChain
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# the used model might be deprecated when you read this article
# replace with gpt-3.5-turbo or gpt-4.0
llm = OpenAI(
temperature=0.9,
model_name="text-davinci-003",
openai_api_key=os.environ.get("OPENAI_API_KEY")
)
Token Classification
The first task is to provide the grammatical structure of a sentence, identifying the nouns, verbs and adjectives. This was also one of the hardest prompts to write, trying to find one that all models understand. Let’s see how the models provides a reflected grammar model from its input.
prompt = PromptTemplate.from_template('''
Define the grammatical structure in the following sentence. Provide a list of pairs in which the word and its gramatical structure is expressed.
Text 1: As of 2016, only three nations have flown crewed spacecraft: USSR/Russia, USA, and China.
Grammatical structure:
As ADP
of ADP
2016 NUM
, PUNCT
only ADV
three NUM
nations NOUN
have AUX
flown VERB
crewed VERB
spacecraft NOUN
. PUNCT
Text: """
{text}
"""
''')
chain = LLMChain(
llm = llm,
prompt=prompt
)
# text source: https://en.wikipedia.org/wiki/Spacecraft#Crewed_spacecraft
chain.run(
text = "The first crewed spacecraft was Vostok 1, which carried Soviet cosmonaut Yuri Gagarin into space in 1961, and completed a full Earth orbit. "
)
# ++++ Result ++++
Grammatical structure:
The ART
first ADJ
crewed VERB
spacecraft NOUN
was AUX
Vostok PROPN
1 NUM
, PUNCT
which REL
carried VERB
Soviet ADJ
cosmonaut NOUN
Yuri PROPN
Gagarin PROPN
into ADP
space NOUN
in ADP
1961 NUM
, PUNCT
and CONJ
completed VERB
a DET
full ADJ
Earth PROPN
orbit NOUN
This result is fantastic!
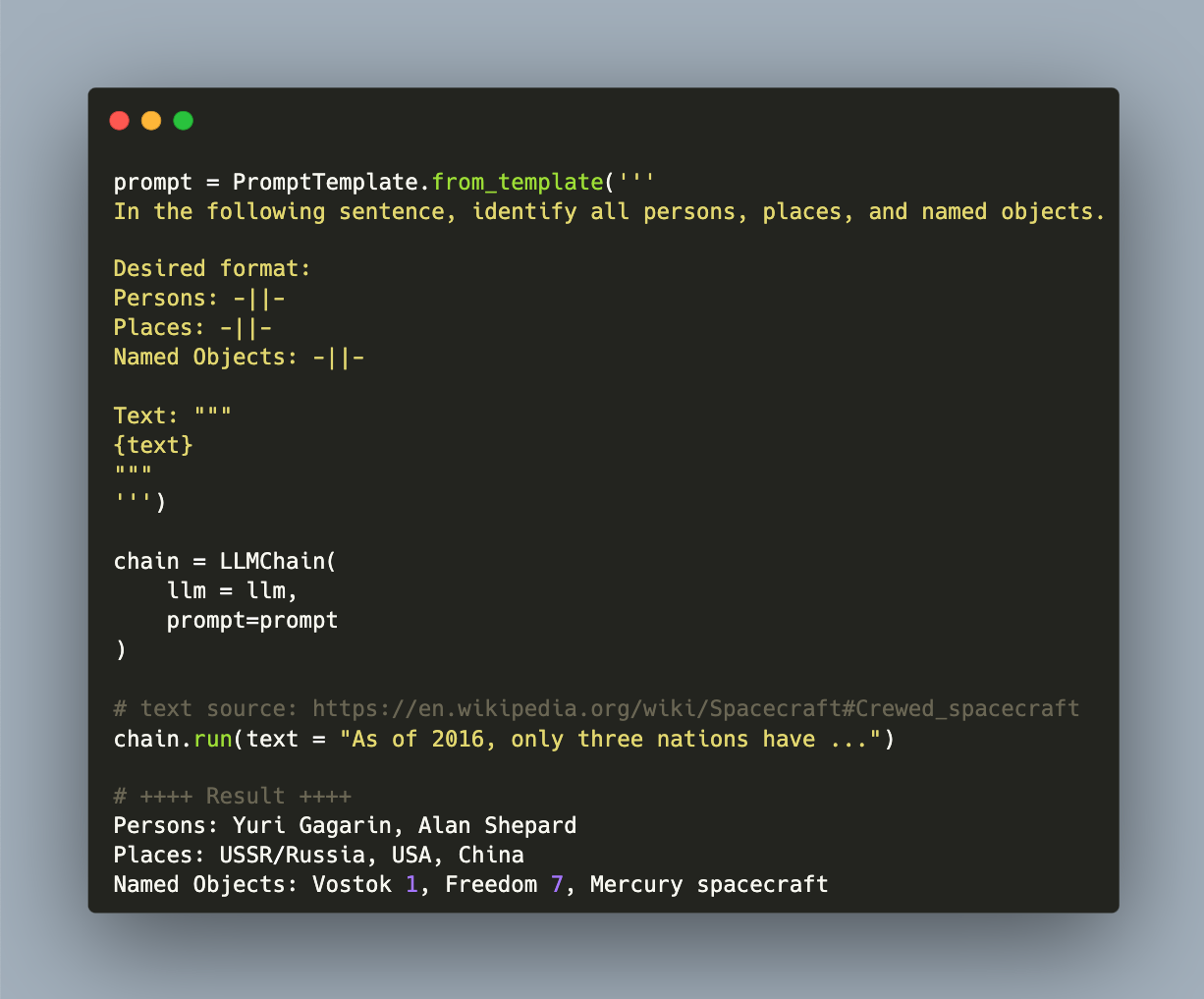
The second task in the token classification category is Named Entity Resolution. In this case, the prompt needs to mention which types of entitles should be extracted and describe the expected output format too. Here is the snippet:
prompt = PromptTemplate.from_template('''
In the following sentence, identify all persons, places, and named objects.
Desired format:
Persons: -||-
Places: -||-
Named Objects: -||-
Text: """
{text}
"""
''')
chain = LLMChain(
llm = llm,
prompt=prompt
)
# text source: https://en.wikipedia.org/wiki/Spacecraft#Crewed_spacecraft
chain.run(
text = "As of 2016, only three nations have flown crewed spacecraft: USSR/Russia, USA, and China. The first crewed spacecraft was Vostok 1, which carried Soviet cosmonaut Yuri Gagarin into space in 1961, and completed a full Earth orbit. There were five other crewed missions which used a Vostok spacecraft. The second crewed spacecraft was named Freedom 7, and it performed a sub-orbital spaceflight in 1961 carrying American astronaut Alan Shepard to an altitude of just over 187 kilometers (116 mi). There were five other crewed missions using Mercury spacecraft."
)
# ++++ Result ++++
Persons: Yuri Gagarin, Alan Shepard
Places: USSR/Russia, USA, China
Named Objects: Vostok 1, Freedom 7, Mercury spacecraft
This result is absolutely correct.
Text Classification
For a text classification task, the prompts need to instruct about expecting a category, and provide the category list.
prompt = PromptTemplate.from_template('''
Identify the category of each of the following texts. The available categories are neutral, approval, disapproval, realization, joy, embarrassment.
Text: """
{text}
"""
''')
chain = LLMChain(
llm = llm,
prompt=prompt
)
# text source: https://en.wikipedia.org/wiki/Spacecraft#Crewed_spacecraft
chain.run(
text = '''
Text 1: The spacecraft succeeded in landing on the moon.
Text 2: Mission control had a stressful time during the takeoff, approaching the moon, and the landing.
Text 3: Speculators surrounding the spacecraft takeoff shed tears of laughter.
Text 4: Some committee members doubted the space missions goals.
'''
)
# ++++ Result ++++
Text 1: Realization
Text 2: Disapproval
Text 3: Joy
Text 4: Disapproval
Interestingly, you can also ask for free-form classification, and the LLM creates appropriate categories automatically. The following results are also quite convincing.
prompt = PromptTemplate.from_template('''
For each of the following text, determine their unique category. Choose the categories on your own.
Text: """
{text}
"""
''')
chain = LLMChain(
llm = llm,
prompt=prompt
)
# text source: https://en.wikipedia.org/wiki/Spacecraft#Crewed_spacecraft
chain.run(
text = '''
Text 1: The spacecraft succeeded in landing on the moon.
Text 2: Mission control had a stressful time during the takeoff, approaching the moon, and the landing.
Text 3: Speculators surrounding the spacecraft takeoff shed tears of laughter.
Text 4: Some committee members doubted the space missions goals.
'''
)
# ++++ Result ++++
Text 1: Space Exploration
Text 2: Stressful Situations
Text 3: Human Reactions
Text 4: Doubts and Skepticism'
Summarization
A prompt to summarize text could not be easier.
prompt = PromptTemplate.from_template('''
Summarize the following text.
Text: """
{text}
"""
''')
chain = LLMChain(
llm = llm,
prompt=prompt
)
# text source: https://en.wikipedia.org/wiki/Spacecraft#Uncrewed_spacecraft
chain.run(
text = '''
Many space missions are more suited to telerobotic rather than crewed operation, due to lower cost and lower risk factors. In addition, some planetary destinations such as Venus or the vicinity of Jupiter are too hostile for human survival. Outer planets such as Saturn, Uranus, and Neptune are too distant to reach with current crewed spaceflight technology, so telerobotic probes are the only way to explore them. Telerobotics also allows exploration of regions that are vulnerable to contamination by Earth micro-organisms since spacecraft can be sterilized. Humans can not be sterilized in the same way as a spaceship, as they coexist with numerous micro-organisms, and these micro-organisms are also hard to contain within a spaceship or spacesuit. Multiple space probes were sent to study Moon, the planets, the Sun, multiple small Solar System bodies (comets and asteroids).
'''
)
# ++++ Result ++++
'Telerobotic space missions are favored over crewed missions due to lower cost and risk, and are the only way to explore regions that are too hostile for humans and too far away for current technology. They also allow exploration of regions that are vulnerable to contamination by Earth micro-organisms as spacecraft can be sterilized, whereas humans cannot. Multiple probes have been sent to study the Moon, planets, Sun, and other small Solar System bodies.'
Translation
An effective translation prompt was already shown in the introduction. Here is the same form again, with the origin language, the target language, and the translatable text as inputs.
prompt = PromptTemplate.from_template('''
Translate the following text from {origin_language} to {target_language}.
Text: """
{text}
"""
''')
chain = LLMChain(
llm = llm,
prompt=prompt
)
# text source: https://en.wikipedia.org/wiki/Spacecraft#Uncrewed_spacecraft
chain.run(
origin_language = "english",
target_language = "japanese",
text = "Many space missions are more suited to telerobotic rather than crewed operation, due to lower cost and lower risk factors",
)
# ++++ Result ++++
# 多くの宇宙ミッションは、コストが低くリスク要因も低いため、クルー操縦よりもテレロボティック操縦の方が適しています。
Questions Answering
To ask a question about a specific text is again a very straightforward prompt. The resulting summary is not a mere repetition or scraping of the input text, but a novel text.
prompt = PromptTemplate.from_template('''
Answer a question for the given text.
Question: """
{question}
"""
Text: """
{text}
"""
''')
chain = LLMChain(
llm = llm,
prompt=prompt
)
# text source: https://en.wikipedia.org/wiki/AI_safety#Black_swan_robustness
chain.run(
question = "What are the risks of Artificial Intelligence?",
text = "Rare inputs can cause AI systems to fail catastrophically. For example, in the 2010 flash crash, automated trading systems unexpectedly overreacted to market aberrations, destroying one trillion dollars of stock value in minutes. Note that no distribution shift needs to occur for this to happen. Black swan failures can occur as a consequence of the input data being long-tailed, which is often the case in real-world environments. Autonomous vehicles continue to struggle with ‘corner cases’ that might not have come up during training; for example, a vehicle might ignore a stop sign that is lit up as an LED grid. Though problems like these may be solved as machine learning systems develop a better understanding of the world, some researchers point out that even humans often fail to adequately respond to unprecedented events like the COVID-19 pandemic, arguing that black swan robustness will be a persistent safety problem"
)
# ++++ Result ++++
Answer: The risks of Artificial Intelligence include failure to correctly interpret rare inputs, black swan failures due to long-tailed input data, and difficulties responding to unprecedented events.
Text Generation
For generating texts, the prompts can include all kind of specifications: The tone, the number of words or sentences, and other restrictions. Resulting texts are manifold and surprising.
prompt = PromptTemplate.from_template('''
Continue the following text with at most 80 words and at least 3 sentences.
Text: """
{text}
"""
''')
chain = LLMChain(
llm = llm,
prompt=prompt
)
chain.run(
text = "The inhabitation and territorial use of extraterrestrial space has been proposed, for example ..."
)
# ++++ Result ++++
Many projects have been proposed to explore the feasibility of living and working in space, such as the International Space Station. On a more ambitious scale, groups have proposed sending humans on missions to colonize other planets. Elon Musk's SpaceX company is even developing the technology to accomplish this goal, with plans to launch the first manned mission to Mars by 2024. One of these projects realistically proposes sending a crew of four astronauts to the Red Planet. If successful, this would be the first human mission to an extraterrestrial body and a huge step forward in our exploration of space."
Dialog
A dialog is a stream of messages between the user and a language model. As such, the messages can be simple texts, but you could use the aforementioned prompts as well and perform a NLP tasks during a chat.
Furthermore, it’s surprising that LangChain abstraction for a chat, the ConversationChain, even works with OpenAI models that were not explicitly designed for chats. The following example runs with the old davinci-text-003 model quiet fine.
conversation = ConversationChain(
llm=llm,
verbose=True
)
conversation.run("Hello ChatGPT.")
conversation.run("I need a book recommendation for a friend.")
conversation.run("He likes science fiction books from Warhammer40K.")
# ++++ Result ++++
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Hello ChatGPT.
AI: Hi there! How can I help you?
Human: I need a book recommendation for a friend.
AI: Sure, I'd be happy to help. What kind of book does your friend like?
Human: Hi likes science fiction books from Warhammer40K
AI: Ah, I see. Warhammer40K is a popular science fiction series. I recommend the novel "Horus Rising" by Dan Abnett. It's the first book in the series and is a great place to start. I\'m sure your friend will love it!
Conclusion
The LangChain Library is a remarkable tool that extends the capabilities of large language models with several useful abstractions, such as prompts, which are structured, reusable and parametrizable texts that instruct a LLM about a specific task. This article showed how to use LangChain with an OpenAI LLM and prompts to perform a variety of NLP tasks. For each of the following tasks, an effective prompt and code snippet was shown: Token Classification, Text Classification, Summarization, Translation, Question Answering, Text Generation, Dialog. With a sufficiently powerful LLM, all NLP tasks are solvable. The results were surprisingly good, and the code boilerplate and prompt minimal, leading to effective and time-saving engineering.