Natural Language Processing with Large Language Modesl is the current state of the art. Investigating how classical NLP tasks became to be solved by LLMs can be observed with using the HuggingFace transformers library.
This library is special in several ways. First of all, it provides loading a huge amount of pretrained models with different architecture, training parameter and training input data. Second, the models support different high-level semantic NLP tasks like classification and word prediction, but only if they have been trained for this purpose. Finally, the “classical” text processing steps, like tokenization or lemmatization, are handled by the models themselves, so text can be processed as-is.
This article provides a concise overview to the transformers library. You will learn how to install it, how to select a suitable model, and see examples how to apply it for NLP tasks such as translation, summarization and question answering.
The technical context for this article is python v3.11 and transformers v.4.30. All examples should work with a newer library version too.
Installation
Transformers can be installed via Python pip:
python3 -m pip install transformers
The library can be loaded in any Python program and is ready to be used immediately. But to use it effectively for an NLP task, you first need to select and download one of the many pre-trained models.
Model Selection
The model hub a total of 88463 concrete NLP models, several of them being fine-tuned version of base models. Given these numbers, choosing an appropriate model for a specific tasks can be daunting, especially since models are added frequently or updated, and the model complexity and applicability continues to grow.
To find a model, different decision angles should be chosen:
- Model family and origin: There are not one, but several transformer architectures. The NLP model family catalogue contains 206 entries. For each family, different models are provided. For example, for the BERT model, the original BERT base-uncased model is a fork of the original research papers open-source repository. And additionally, several fine-tuned models exist as well, such as bert-large-NER for named entity recognition. Another example are available large language model, like the most recent falcon-40b, which is provided by a non-profit research company.
- Compatibility with other NLP libraries: The compatibility table shows which model is compatible with which Python framework, supported are amongst others PyTorch, Tensorflow or Flax.
- NLP task: Most models support tasks that are provided as different pipelines. To find which tasks are supported, several information pages can be consulted: The help page What Transformers can do delivers quick examples, the page NLP task guide provides discussions and model usage details, the NLP pipelines an overview table. Finally, both the task overview as well as the model hub enable quick selection of appropriate models. In summary, the following tasks are supported, grouped into categories that also structure the remainder of this article.
| Name | Description | Pipelines |
|---|---|---|
| Token Classification | Provide Annotations to Tokens of an input text | `token-classification`, `ner` |
| Text Classification | Evaluate to which document class or sentiment a text belongs | `text-classification`, `sentiment-analysis`, `zero-shot-classification` |
| Translation | Translate a text into another language | `translation`, `translation_xx_to_yy` |
| Summarization | Provide an excerpt or generated summary of a text | `summarization` |
| Question Answer | Provide an excerpt or generated text for a question | `question-answering`, `table-question-answering`, `text2text-generation` |
| Dialogue | Provide open-ended conversation within a memorized context and with emergent capabilties like reasoning, question-answer and more | `conversational` |
In the remainder of this article, for each of these tasks, an executable example is shown. But lets start with an example first.
Example: Word Prediction with BERT
To load and use a model, the transformers library supports generalized API calls and model-specific wrappers.
The generalized calls resolve model configurations and model instances from the hub by using the model names. Here is the relevant snippet:
from transformers import AutoModel
model_name = "bert-large-cased-whole-word-masking"
model = AutoModel.from_pretrained(model_name)
model
# BertModel(
# (embeddings): BertEmbeddings(
# (word_embeddings): Embedding(28996, 1024, padding_idx=0)
# (position_embeddings): Embedding(512, 1024)
# (token_type_embeddings): Embedding(2, 1024)
# (LayerNorm): LayerNorm((1024,), eps=1e-12, elementwise_affine=True)
# (dropout): Dropout(p=0.1, inplace=False)
# )
However, an AutoModel has limitation, for example it will not have a configured tokenizer or other text processing steps. Therefore, to load models with the intention of running pipeline task, it is recommended to use wrapper classes for the specific model type, and to instantiate it with the name of the pretrained model.
from transformers import BertModel
model = BertModel.from_pretrained("bert-large-cased-whole-word-masking")
When the model is loaded, you can create a pipeline object by naming the task you want to handle and pass in the model. In the following example, a fill-mask tasks is executed, in which the model predicts a masked word. You need to pass in a tokenizer object as well, independent of whether the model was created by a wrapper class or as an AutoModel.
from transformers import BertModel, BertTokenizer
model_name = "bert-large-cased-whole-word-masking"
model = BertModel.from_pretrained(model_name)
tokenizer = BertTokenizer.from_pretrained(model_name)
task = pipeline('fill-mask', model=model, tokenizer=tokenizer)
task("Artificial intelligence (AI) is intelligence demonstrated by [MASK].")
[{'score': 0.6048021912574768,
'token': 6555,
'token_str': 'machines',
'sequence': 'Artificial intelligence ( AI ) is intelligence demonstrated by machines.'},
{'score': 0.10071849077939987,
'token': 2815,
'token_str': 'technology',
'sequence': 'Artificial intelligence ( AI ) is intelligence demonstrated by technology.'},
For just running a task, there is no need to explicitly create the model object beforehand, you can use the model name as-is.
task = pipeline('fill-mask', model='bert-large-cased-whole-word-masking')
Finally, you don’t even need to provide a model to a pipeline task, a default model will be chosen (I could not figure out how these default models are determined or configured).
task = pipeline(task="fill-mask")
task("Artificial intelligence (AI) is intelligence demonstrated by <mask>")
# # No model was supplied, defaulted to distilroberta-base and revision ec58a5b (https://huggingface.co/distilroberta-base).
...
[{'score': 0.11110831797122955,
'token': 12129,
'token_str': ' robots',
'sequence': 'Artificial intelligence (AI) is intelligence demonstrated by robots'},
{'score': 0.06050176918506622,
'token': 4687,
'token_str': ' AI',
'sequence': 'Artificial intelligence (AI) is intelligence demonstrated by AI'},
{'score': 0.04493508115410805,
'token': 20721,
'token_str': ' robotics',
Interestingly, you can also force models to work with pipelines that they were not trained for, but the results cannot be used in a meaningful way.
bert_pipeline = pipeline("text-classification", model="bert-base-uncased")
print(bert_pipeline)
# <transformers.pipelines.text_classification.TextClassificationPipeline object at 0x15c2dd410>
bert_pipeline("Artificial intelligence (AI) is intelligence demonstrated by [MASK]")
[{'label': 'LABEL_1', 'score': 0.559747576713562}]
bert_pipeline = pipeline("text-generation", model="bert-base-uncased")
print(bert_pipeline)
#<transformers.pipelines.text_generation.TextGenerationPipeline object at 0x15d370310>
bert_pipeline("Artificial intelligence (AI) is intelligence demonstrated by [MASK]")
[{'generated_text': 'Artificial intelligence (AI) is intelligence demonstrated by [MASK] the.........'}]
Token Classification
Pipelines: token-classification, ner
This group includes tasks that label individual tokens in the input set, which can be used for named-entity recognition and part-of-speech tagging.
NER recognition is dependent on the model. The following model detects location (LOC), organizations (ORG), person (PER) and Miscellaneous (MISC).
model_name = "dslim/bert-base-NER"
#source: https://en.wikipedia.org/wiki/Space_colonization#Conceptual
text = '''According to Bloomberg's Jack Clark, 2015 was a landmark year for artificial intelligence, with the number of software projects that use AI within Google increased from a "sporadic usage" in 2012 to more than 2,700 projects'''
task = pipeline(task="token-classification", model=model_name)
task(text)
[{'entity': 'B-PER',
'score': 0.9996131,
'index': 10,
'word': 'Francis',
'start': 45,
'end': 52},
{'entity': 'I-PER',
'score': 0.99930227,
'index': 11,
'word': 'Drake',
'start': 53,
'end': 58},
{'entity': 'B-PER',
'score': 0.999265,
'index': 13,
'word': 'Christoph',
'start': 63,
'end': 72},
{'entity': 'I-PER',
'score': 0.9988273,
'index': 14,
'word': 'Columbus',
'start': 73,
'end': 81},
{'entity': 'B-LOC',
'score': 0.9908462,
'index': 18,
'word': 'Moon',
'start': 95,
'end': 99},…]
For POS tagging, several more models exist as well. Also note that the following example only works when a TokenClassificationPipeline instead of the generic pipeline is used.
from transformers import AutoTokenizer, AutoModelForTokenClassification, TokenClassificationPipeline
from transformers import pipeline
model_name = "QCRI/bert-base-multilingual-cased-pos-english"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name)
task = TokenClassificationPipeline(model=model, tokenizer=tokenizer)
text = "Artificial intelligence (AI) is intelligence demonstrated by computers, as opposed to human or animal intelligence."
task(text)
[{'entity': 'JJ', 'score': 0.97445834, 'index': 1, 'word': 'Arti', 'start': 0, 'end': 4}, {'entity': 'JJ', 'score': 0.9924096, 'index': 2, 'word': '##ficial', 'start': 4, 'end': 10}, {'entity': 'NN', 'score': 0.99903476, 'index': 3, 'word': 'intelligence', 'start': 11, 'end': 23}, {'entity': '-LRB-', 'score': 0.9993954, 'index': 4, 'word': '(', 'start': 24, 'end': 25}, {'entity': 'NNP', 'score': 0.83791345, 'index': 5, 'word': 'AI', 'start': 25, 'end': 27}, {'entity': '-RRB-', 'score': 0.9993837, 'index': 6, 'word': ')', 'start': 27, 'end': 28}, {'entity': 'VBZ', 'score': 0.99947506, 'index': 7, 'word': 'is', 'start': 29, 'end': 31}, {'entity': 'NN', 'score': 0.99937004, 'index': 8, 'word': 'intelligence', 'start': 32, 'end': 44}, {'entity': 'VBN', 'score': 0.9978248, 'index': 9, 'word': 'demonstrated', 'start': 45, 'end': 57}, {'entity': 'IN', 'score': 0.9998036, 'index': 10, 'word': 'by', 'start': 58, 'end': 60}, {'entity': 'NNS', 'score': 0.99938047, 'index': 11, 'word': 'computers', 'start': 61, 'end': 70}, {'entity': ',', 'score': 0.9999342, 'index': 12, 'word': ',', 'start': 70, 'end': 71}, {'entity': 'IN', 'score': 0.9960103, 'index': 13, 'word': 'as', 'start': 72, 'end': 74}, {'entity': 'VBN', 'score': 0.99729484, 'index': 14, 'word': 'opposed', 'start': 75, 'end': 82}, {'entity': 'TO', 'score': 0.99986374, 'index': 15, 'word': 'to', 'start': 83, 'end': 85}, {'entity': 'JJ', 'score': 0.8945883, 'index': 16, 'word': 'human', 'start': 86, 'end': 91}, {'entity': 'CC', 'score': 0.9997588, 'index': 17, 'word': 'or', 'start': 92, 'end': 94}, {'entity': 'NN', 'score': 0.74084973, 'index': 18, 'word': 'animal', 'start': 95, 'end': 101}, {'entity': 'NN', 'score': 0.9996666, 'index': 19, 'word': 'intelligence', 'start': 102, 'end': 114}, {'entity': '.', 'score': 0.9999201, 'index': 20, 'word': '.', 'start': 114, 'end': 115}]
Text Classification
Pipelines: text-classification, sentiment-analysis, zero-shot-learning
For a binary classification, which means the text is either of positive or negative connotation, many models exist.
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
text = "Artificial intelligence (AI) is intelligence demonstrated by computers, as opposed to human or animal intelligence."
task = pipeline(task="text-classification", model=model_name)
task(text)
# [{'label': 'POSITIVE', 'score': 0.9228528738021851}]
More nuanced classifications are highly dependent on the model. The following model differentiates 16 classes, from joy to nervousness to disappointment.
model_name = "SamLowe/roberta-base-go_emotions"
text1 = '''Artificial intelligence (AI) is intelligence demonstrated by computers, as opposed to human or animal intelligence.'''
text2 = '''Artificial intelligence was founded as an academic discipline in 1956, and in the years since it has experienced several waves of optimism, followed by disappointment and the loss of funding (known as an "AI winter"), followed by new approaches, success, and renewed funding.'''
task = pipeline(task="text-classification", model=model_name)
task(text1)
[{'label': 'neutral', 'score': 0.8950573205947876}]
task(text2)
[{'label': 'disappointment', 'score': 0.7222175002098083}]
The final classification pipeline works especially well with emergent capabilities of large language models. The input needs to be a text and a set of suggested labels. In the following example, an excerpt from the Wikipedia article about space exploration is the input text, and the candidate categories includes the articles categories as displayed on Wikipedia, together with additional categories. As is shown, the ordered probability of the categories is quite correct.
from transformers import pipeline
task = pipeline("zero-shot-classification")
# default model is facebook/bart-large-mnli
# Source: https://en.wikipedia.org/wiki/Space_colonization#History
text = '''
When the first space flight programs ...
...
In 1977 finally the ...
'''
candidate_labels = ['Documentation',
'Computer',
'Phone',
'Spaceflight concepts',
'Open problems',
'Space colonization',
'Colonialism',
'Solar System',
'Movie']
res = task(text, candidate_labels)
sorted(list(zip(res['labels'], res['scores'])), key = lambda x:x[1], reverse=True)
[('Spaceflight concepts', 0.2542096972465515),
('Open problems', 0.18996372818946838),
('Space colonization', 0.18421387672424316),
('Colonialism', 0.12988941371440887),
('Solar System', 0.06426611542701721),
('Phone', 0.05195607990026474),
('Documentation', 0.051204368472099304),
('Computer', 0.043274108320474625),
('Movie', 0.03102256916463375)]
Summarization
Pipelines: summarization
This task consumes a large text to summarize its key aspects.
The following example show how the Wikipedia article about AI safety is summarized. Model capability differs a lot: Sometimes, only the first sentences are reflected, at other times, excerpts from different part of the text or even a generated answer might occur.
The summarization of the default model:
from transformers import pipeline
task = pipeline("summarization")
# default model is sshleifer/distilbart-cnn-12-6
task(text)
[{'summary_text': " First space flight programs partly used and continued to use colonial spaces on Earth, such as places of indigenous peoples at the RAAF Woomera Range Complex, Guiana Space Centre or for astronomy at the Mauna Kea telescope . When orbital spaceflight was achieved in the 1950s colonialism was still a strong international project, e.g. The first space stations were succeeded by the ISS, today's largest human outpost in space ."}]
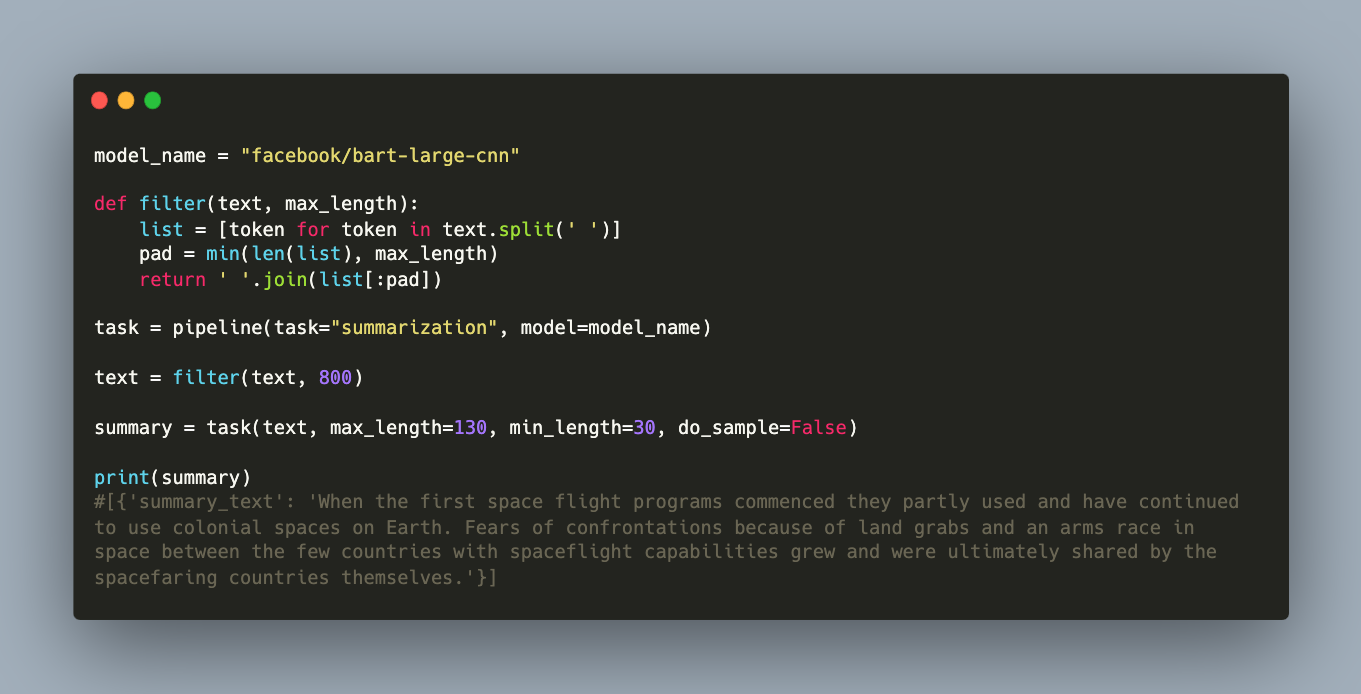
Some models await a fixed input size of 1024 tokens, so a custom filter method might be needed. Here is an example.
model_name = "facebook/bart-large-cnn"
def filter(text, max_length):
list = [token for token in text.split(' ')]
pad = min(len(list), max_length)
return ' '.join(list[:pad])
task = pipeline(task="summarization", model=model_name)
text = filter(text, 800)
summary = task(text, max_length=130, min_length=30, do_sample=False)
print(summary)
[{'summary_text': 'When the first space flight programs commenced they partly used and have continued to use colonial spaces on Earth. Fears of confrontations because of land grabs and an arms race in space between the few countries with spaceflight capabilities grew and were ultimately shared by the spacefaring countries themselves.'}]
Translation
Pipelines: translation, translation_xx_to_yy
This task translates texts from one natural language to another. The model needs to be chosen for its supported languages beforehand.
Example for chinese to english text.
model_name = "Helsinki-NLP/opus-mt-zh-en"
chinese_to_english = pipeline("translation", model=model_name)
# Source: https://zh.wikipedia.org/wiki/%E5%A4%AA%E7%A9%BA%E7%A7%BB%E6%B0%91
text = '''
与太阳最近的恒星比邻星,距離地球遠達四光年。假设太阳系只有硬币大小,那么比邻星的位置就是在這个硬币一百米半径以外。
正是因为系外星體距离如此遠,現時我们基本上是沒有能力抵达任何一顆系外星體:我们最快的飞行器不僅要依靠火箭引擎,还要加上星體重力助推,才能达到上百马赫。而火箭助推加太阳系内星體重力助推的极限应该在一千马赫以内(一千马赫的速度可以花两分钟绕地球半徑一圈,或五个月出行星圈)。按这个极限速度走一光年的距离要八百八十一年。以目前飛行最远的人造物体——旅行者1号的速度,将要花上七万三千六百年的时间到达比邻星。
'''
chinese_to_english(text)
[{'translation_text': "It is precisely because the outer star is so far away that we are basically unable to reach any one of the extraterrestrials: our fastest vehicle depends not only on a rocket engine, but also on the gravity of the star. And the rocket is supposed to boost the gravity of the solar system within a thousand makhs (a thousand makhs can take two minutes around the Earth's radius a circle, or five months out of the planetary circle). It takes 881 years to walk at this threshold. At the current speed of the most distant objects, Traveler 1, it will take 73,000, 600 years to reach the next star."}]
The pipeline abstraction translation_xx_to_yy defaults to a model which has 4 languages, so the mapping needs to be specific. Here is an example for translating english to romanian:
task = pipeline("translation_en_to_ro")
# Source: https://en.wikipedia.org/wiki/Space_colonization
text = '''
Many arguments for and against space settlement have been made.[3] The two most common in favor of colonization are survival of human civilization and life from Earth in the event of a planetary-scale disaster (natural or human-made), and the availability of additional resources in space that could enable expansion of human society. The most common objections include concerns that the commodification of the cosmos may be likely to enhance the interests of the already powerful, including major economic and military institutions; enormous opportunity cost as compared to expending the same resources here on Earth; exacerbation of pre-existing detrimental processes such as wars, economic inequality, and environmental degradation.
'''
task(text)
{'translation_text': 'Au fost aduse multe argumente pentru şi împotriva colonizării spaţiale.[3] Cele mai comune două argumente în favoarea colonizării sunt supravieţuirea civilizaţiei umane şi a vieţii de pe Pământ în eventualitatea unui dezastru la scară planetară (natural sau provocat de om) şi disponibilitatea resurselor suplimentare în spaţiu care ar putea permite extinderea societăţii umane. Printre cele mai comune obiecţii se numără'}]
Questions Answering
Pipelines: question-answering, table-question-answering, text2text-generation
Question answering models are pre-trained, mostly open-domain, and provide different methods for asking questions. In the extractive mode, the context to the question is provided, and the model needs to extract the relevant part from this model. In the abstractive mode, the context to the question is given too, but the model formulates an answer on its own.
Several pipelines exists, here is an example for the first one question-answering:
task = pipeline(task="question-answering")
# default model is distilbert-base-cased-distilled-squad
# source: https://en.wikipedia.org/wiki/AI_safety
task(
question = "What are the risks of Artificial Intelligence?",
context = "AI safety is an interdisciplinary field concerned with preventing accidents, misuse, or other harmful consequences that could result from artificial intelligence (AI) systems. It encompasses machine ethics and AI alignment, which aim to make AI systems moral and beneficial, and AI safety encompasses technical problems including monitoring systems for risks and making them highly reliable. Beyond AI research, it involves developing norms and policies that promote safety."
)
{'score': 0.612716019153595,
'start': 66,
'end': 114,
'answer': 'accidents, misuse, or other harmful consequences'}
The pipeline text2text-generation is an example of the abstractive mode, in which the model formulates and answer itself. However, the following example produces an answer that is included verbatim in the context too.
from transformers import pipeline
task = pipeline("text2text-generation")
# default model is t5-base
question = "What are the tasks of AI safety",
# Source: https://en.wikipedia.org/wiki/AI_safety
context = "AI safety is an interdisciplinary field concerned with preventing accidents, misuse, or other harmful consequences that could result from artificial intelligence (AI) systems. It encompasses machine ethics and AI alignment, which aim to make AI systems moral and beneficial, and AI safety encompasses technical problems including monitoring systems for risks and making them highly reliable. Beyond AI research, it involves developing norms and policies that promote safety."
task(f'question:{question} ? context:{context}')
# [{'generated_text': 'monitoring systems for risks and making them highly reliable'}]
The table-question-answering pipeline is special: It provides a natural language interface to numerical data inside a table, akin to formulate SQL for data retrieval.
task = pipeline(task="table-question-answering")
# default model is distilbert-base-cased-distilled-squad
data = {
"Models": [
"question-answering",
"table-question-answering",
"text2text-generation"
],
"Instances": [
"5454",
"65",
"15496"
]
}
table = pd.DataFrame.from_dict(data)
task(
query = "How many instances exist for text2text-generation",
table=table
)
{'answer': 'AVERAGE > 15496',
'coordinates': [(2, 1)],
'cells': ['15496'],
'aggregator': 'AVERAGE'}
task(
query = "What is the total amount of all instances?",
table=table
)
{'answer': 'SUM > 5454, 65, 15496',
'coordinates': [(0, 1), (1, 1), (2, 1)],
'cells': ['5454', '65', '15496'],
'aggregator': 'SUM'}
Text Generation
Pipelines: fill-mask, text-generation
To generate plausible language from a machine has been an elaborate goal, and transfomer models have achieved it.
The fill-mask pipelines computes possible words for mussing parts of a sentence:
task = pipeline('fill-mask')
text = "The inhabitation and territorial use of <mask> has been proposed."
task(text)
[{'score': 0.10173490643501282,
'token': 1212,
'token_str': ' land',
'sequence': 'The inhabitation and territorial use of land has been proposed.'},
{'score': 0.07234926521778107,
'token': 29084,
'token_str': ' wetlands',
'sequence': 'The inhabitation and territorial use of wetlands has been proposed.'},
{'score': 0.03514835238456726,
'token': 8879,
'token_str': ' islands',
'sequence': 'The inhabitation and territorial use of islands has been proposed.'},
And the text-generation pipeline starts from a context text to produce and open-ended text. The models capability to not repeat itself and provide meaningful text is an important characteristic for making a concrete choice.
task = pipeline("text-generation")
# default model is gpt2
# Source: https://en.wikipedia.org/wiki/Space_colonization
text = "The inhabitation and territorial use of extraterrestrial space has been proposed, for example ..."
task(text, max_length=120)
[{'generated_text': "The inhabitation and territorial use of extraterrestrial space has been proposed, for example by Daniel J. B. Anderson, R.D., in his book, The Search for the Self and our World: Evidence from Earth, Interstellar, and the Voyagers of Interstellar Life. For the remainder, the research team uses data from the ISS Exploration and Analysis Center – a major interplanetary telescope that measures the Earth from the space station.\n\nThe team's team has created a simulation where this simulation is performed using the most current methods to identify and characterize how the Earth's orbit shapes theitherly"}]
task(text, max_length=120,temperature=1.0)
[{'generated_text': "The inhabitation and territorial use of extraterrestrial space has been proposed, for example, by the Japanese and other observers.\n\nHow the moon's atmosphere works is often unknown, but scientists believe it can be manipulated and modified by aliens to give them a grip on the Earth system in a manner similar to the way humans can control the moon's temperature in a similar role. The Earth's atmosphere contains about six times more carbon dioxide than water, and the Earth's gravity helps create a large volume of water vapor that is capable of making liquid oxygen, methane and nitrogen vapors.\n\nEven if"}]
task(text, max_length=120,temperature=10.0)
[{'generated_text': "The inhabitation and territorial use of extraterrestrial space has been proposed, for example through the intermix. As such most attempts point out some interesting possibilities concerning its extratermic environment [37••]), its ability only indirectly; the nature as indicated also could affect certain processes where more or very more important data has less (although possible for instance: 'all possible things are good because every body must also happen when at least an order should be offered'), but its present scope as envisaed on behalf to humankind has been ignored and not explored as an international subject or even described (or perhaps suggested and implied upon"}]
Dialog
Pipelines: conversational
Dialog is a special form of text generation in which the model has both a context of the conversation, which means it can access prior messages that were asked as well as its own given answers. Also, the model supports a wide range of all other tasks, like translation, question answering and reasoning. Large Language Models (also called foundation models) provides these as emergent capabilities, which means the model was not explicitly trained for this tasked, but developed or evolved it during training and fine-tuning.
from transformers import pipeline, Conversation
converse = pipeline("conversational")
# default pipeline is microsoft/DialoGPT-medium
chat = [
Conversation("Hello. Nice to meet you."),
Conversation("What is your favorite book about programming languages?")
]
converse(chat)
[Conversation id: 31a01f9d-770e-4cf0-ae44-debed1e431f1
user >> Hello. Nice to meet you.
bot >> Nice to meet you too. ,
Conversation id: 9d66165c-ef55-4f82-9378-5febc090b83c
user >> What is your favorite book about programming languages?
bot >> I'm not a book person, but I really enjoyed The Language Instinct by David Lee. ]
Summary
The HuggingFace transformers library provide a powerful API to load and execute transformers model. With an impressive amount of 207 mode families and over 88463 concrete NLP models, making a concrete choice can be exiting and daunting. The most important decision factor should be the NLP tasks the model needs to accomplish, and here the library provides the helpful abstraction of a pipeline, a specific task that is supported. This article showed you ready-to-use examples for these tasks: 1) token classification, 2) text classification, 3) summarization, 4) translation, 5) question answering, 6) text generation and 7) dialog. By provide well-chosen default models, as well as a very browsable and filterable model hub, suitable and powerful models can be used with few amounts of Python code, which makes incorporating NLP into projects very accessible.