Large Language Models are a ubiquitous technology that revolutionizes the way we work with computers. LLMs in the size of around 7B provide good capabilities and include up-to-date knowledge. With a combination of a specialized data format and quantization, these models can be executed on modes consumer hardware with a six-core CPU and 16GB RAM.
This blog post continues the investigation of running LLMs locally. As before, you will get a brief description of the tool, then see copy-and-paste ready code snippets for installation, model loading, and starting interference. All tools will be compared at a glance, and I will give a personal recommendation.
The technical context of this article is a computer with a recent Linux or OsX distribution, Python v3.11, and the most recent version of the tools. All instructions should work with newer versions of the tools as well.
Library Overview
This article investigates the following librararies:
The concrete hardware requirements can be modest. The reference computer used for running the tools is from 2019 - a Linux PC with Ubuntu 22.04 and the following hardware specs:
- Ryzen 3 1600X (3.6 GHZ, 6 core, 12 threads)
- Geforce GTX 970 (4GB, 1114 MHz)
- 64GB DDR4 RAM (2400 MHz) note: this is an upgrade to my earlier system, since I wanted try more complex models too
- 256GB M2 SSD
To test the text generation capabilities of these modes, the following prompt will be used:
PROMPT="You are a helpful AI assistant.\
Please answer the following question.\
Question: Which active space exploration missions are conducted by NASA?\
Answer:"
Lit GPT
| CLI | API | GUI | GPU Support | NVDIA | AMD | Included Models |
|---|---|---|---|---|---|---|
| ✅ | ❌ | ❌ | ✅ | ✅ | ❌ | 20 |
This project aims to run LLMs on modest computer hardware, providing efficient quantization methods, and a readable code base to encourage other programs to add their specific use cases. The supported models revolve around LLaMA and its variants, but it also supports Pythia, Gemma and Phi.
A strong requirement for lit GPT is to have a NVDIA GPU and CUDA support activated on the target computer - I could not find an option to run the model on the CPU only. Another limitation as pointed out in this issue on GitHub is that model execution only uses 1 CPU core because its PyTorch code base is not yet optimized for multi-core processors.
Installation & Model Loading
git clone <https://github.com/Lightning-AI/lit-gpt>
cd lit-gpt
pip install -r requirements-all.txt
For each model, the project contains an installation file. This file also mentions the to-be expected GPU RAM requirement. Furthermore, it shows how to use different quantization methods.
Given the 4GB limit of my reference computer, I decided to use the pythia-1b model.
pip install 'huggingface_hub[hf_transfer] @ git+https://github.com/huggingface/huggingface_hub'
python scripts/download.py --repo_id databricks/dolly-v2-3b
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/databricks/dolly-v2-3b
Model Interference
python generate/base.py --quantize bnb.nf4 --checkpoint_dir checkpoints/databricks/dolly-v2-3b --precision 16-true --max_new_tokens 2048 --prompt "${PROMPT}"
Stats
Loading model 'checkpoints/databricks/dolly-v2-3b/lit_model.pth' with {'name': 'dolly-v2-3b',
'hf_config': {'org': 'databricks',
'name': 'dolly-v2-3b'},
'block_size': 2048,
'vocab_size': 50254,
'padding_multiple': 512,
'padded_vocab_size': 50280,
'n_layer': 32,
'n_head': 32,
'n_embd': 2560,
'rotary_percentage': 0.25,
'parallel_residual': True,
'bias': True,
'lm_head_bias': False,
'n_query_groups': 32,
'shared_attention_norm': False,
'_norm_class': 'LayerNorm',
'norm_eps': 1e-05,
'_mlp_class': 'GptNeoxMLP',
'gelu_approximate': 'none',
'intermediate_size': 10240,
'rope_condense_ratio': 1,
'rope_base': 10000,
'n_expert': 0,
'n_expert_per_token': 0,
'head_size': 80,
'rope_n_elem': 20}
Time to instantiate model: 0.32 seconds.
Time to load the model weights: 6.99 seconds.
Seed set to 1234
# Time for inference 1: 17.52 sec total, 14.61 tokens/sec
# Memory used: 2.18 GB
Text Output
Mission TOI 378 was the first mission that sent a robot to the planet Mars from another planet. The mission lasted 8 months, and was a success. The crew of this NASA space mission included: 1. Michael J. Williams, a research scientist; 2. Sandra E. Evans, a biologist; 3. Sandra Elizabeth Griffith, a biologist; 4. Harry Whittington, an aerospace engineer; 5. David G. Stevenson, an aerospace engineer; 6. Ellen O. Lundgren, a biologist; 7. Christina M. Schwartz, a research scientist; and 8. Kenneth A. Intihar, an aerospace engineer.
Mission TOI 378 was sent to Mars in November 2015, and returned to Earth in June 2016. The mission used the Doveboun 2 rover, and the Skycrane mobile arm to collect samples for return to Earth. Mission TOI 378 is the first successful Mars landing of a rover by a US agency.
Mission TOI 378 was the third of six such missions planned for the 2022 time frame.
Mission TOI 413 was the second successful mission that sent a robot to the planet Mars from another planet. The mission lasted 8 months, and was a success. The crew of this NASA space mission included: 1. Michael J. Williams, a research scientist; 2. Sandra E. Evans, a biologist; 3. Sandra Elizabeth Griffith, a biologist; 4. Harry Whittington, an aerospace engineer; 5. David G. Stevenson, an aerospace engineer; 6. Ellen O. Lundgren, a biologist; 7. Christina M. Schwartz, a research scientist; and 8. Kenneth A. Intihar, an aerospace engineer.
Mission TOI 413 was sent to Mars in 2015, and returned to Earth in 2016. The mission used the Curiosity rover, and the Skycrane mobile arm to collect samples for return to Earth. Mission TOI 413 is the second successful Mars landing of a rover by a US agency.
Mission TOI 413 was the fifth of six such missions planned for the 2022 time frame.
Mission TOI 430 was the third successful mission that sent a robot to the planet Mars from another planet. The mission lasted 12 months, and was a success. The crew of this NASA space mission included: 1. Michael J. Williams, a research scientist; 2. Sandra E. Evans, a biologist; 3. Sandra Elizabeth Griffith, a biologist; 4. Harry Whittington, an aerospace engineer; 5. David G. Stevenson, an aerospace engineer; 6. Ellen O. Lundgren, a biologist; 7. Christina M. Schwartz, a research scientist; and 8. Kenneth A. Intihar, an aerospace engineer.
Mission TOI 430 was sent to Mars in 2022, and returned to Earth in 2023. The mission used the InSight-Lander, and the BeagleBone Blackboard for surface operations. Mission TOI 430 is the third successful Mars landing of a rover by a US agency.
Mission TOI 430 was the sixth of six such missions planned for the 2022 time frame.
Mission TOI 431 was the fourth successful mission that sent a robot to the planet Mars from another planet. The mission lasted 12 months, and was a success. The crew of this NASA space mission included: 1. Michael J. Williams, a research scientist; 2. Sandra E. Evans, a biologist; 3. Sandra Elizabeth Griffith, a biologist; 4. Harry Whittington, an aerospace engineer; 5. David G. Stevenson, an aerospace engineer; 6. Ellen O. Lundgren, a biologist; 7. Christina M. Schwartz, a research scientist; and 8. Kenneth A. Intihar, an aerospace engineer.
Mission TOI 431 was sent to Mars in 2022, and returned to Earth in 2023. The mission used the InSight-Lander, and the BeagleBone Blackboard for surface operations. Mission TOI 431 is the fourth successful Mars landing of a rover by a US agency.
Mission TOI 431 was the seventh of six such missions planned for the 2022 time frame.
Mission TOI 432 was the fifth successful mission that sent a robot to the planet Mars from another planet. The mission lasted 12 months, and was a success. The crew of this NASA space mission included: 1. Michael J. Williams, a research scientist; 2. Sandra E. Evans, a biologist; 3. Sandra Elizabeth Griffith, a biologist; 4. Harry Whittington, an aerospace engineer; 5. David G. Stevenson, an aerospace engineer; 6. Ellen O. Lundgren, a biologist
LocalAI
| CLI | API | GUI | GPU Support | NVDIA | AMD | Included Models |
|---|---|---|---|---|---|---|
| ❌ | ✅ | ❌ | ✅ | ✅ | ❌ | 16 (and any model in GGML/GGUF format) |
This project aims to bring a variety of LLMs to consumer hardware. By default, all models are quantized and run on CPU only. The vast amount of supported LLMs spans different model formats, such as GGML/GGUF and Transformers, as well as model modality, including text, images, audio and video. Models can be used via an OpenAI API compatible format.
This projects provides fully configured and pre-built Docker containers, requiring no installation on the target computer at all. These containers either have a model included or they include the local-ai binary only and you can provision any GGUF model file. Furthermore, they support CPU-only and NVDIA GPUs too. On its roadmap, features like documents uplod, AMD GPU support, and running the new non-transformer model Mamba.
Installation & Model Loading
docker run -ti -p 8080:8080 localai/localai:v2.9.0-ffmpeg-core tinyllama-chat
Model Interference
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "tinyllama-chat",
"messages": [{"role": "user", "content": "You are a helpful AI assistant.Please answer the following question Question: Which active space exploration missions are conducted by NASA? Answer:"}], "temperature": 0.1, " max_tokens":100
}'
Stats
The startup contains log messages about the models technical environment.
CPU info:
model name : AMD Ryzen 5 1600 Six-Core Processor
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb hw_pstate ssbd ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif overflow_recov succor smca sev
CPU: AVX found OK
CPU: AVX2 found OK
CPU: no AVX512 found
@@@@@
7:41PM DBG no galleries to load
7:41PM INF Starting LocalAI using 4 threads, with models path: /build/models
7:41PM INF LocalAI version: v2.9.0 (ff88c390bb51d9567572815a63c575eb2e3dd062)
7:41PM INF Preloading models from /build/models
7:41PM INF Downloading "<https://huggingface.co/TheBloke/TinyLlama-1.1B-Chat-v0.3-GGUF/resolve/main/tinyllama-1.1b-chat-v0.3.Q8_0.gguf>"
7:41PM INF Downloading /build/models/84fe2946ae6893ef8c676f248157ad62.partial: 34.2 MiB/1.1 GiB (3.07%) ETA: 2m38.733611013s
┌───────────────────────────────────────────────────┐
│ Fiber v2.50.0 │
│ <http://127.0.0.1:8080> │
│ (bound on host 0.0.0.0 and port 8080) │
│ │
│ Handlers ........... 105 Processes ........... 1 │
│ Prefork ....... Disabled PID ................ 14 │
└───────────────────────────────────────────────────┘
Unfortunately, interference execution does not reveal any stats.
Text Output
The most active space exploration mission of NASA is the International Space Station (ISS). The ISS is a complex of three orbiting laboratories that are maintained by the United States, Russia, and Europe. The ISS is a research facility that is designed to support human spaceflight and is designed to operate for at least the 2030s.
The ISS is a major component of the United States' space exploration program and is a key element of the nation's capabilities in space. The ISS is a complex of three orbiting laboratories that are maintained by the United States, Russia, and Europe. The ISS is designed to support human spaceflight and is designed to operate for at least the 2030s.
llamafile
| CLI | API | GUI | GPU Support | NVDIA | AMD | Included Models |
|---|---|---|---|---|---|---|
| ❌ | ✅ | ✅ | ✅ | ✅ | ✅ | 9 (and any model in GGUF format) |
Collapsing the complexity of running LLMs into one executable file is the goal of this project. The llamafile binary supports Linux, Windows, OsX and even runs on ARM computers such as the Raspberry Pi. Models can be run with CPU-only or GPU. The project provides 9 llamafiles for popular models, but it can also be used with any other GGUF file.
Installation & Model Loading
wget --continue -O llava.bin https://huggingface.co/jartine/llava-v1.5-7B-GGUF/resolve/main/llava-v1.5-7b-q4.llamafile?download=true
chmod +x llava.bin
./llava.bin -ngl 9999
Model Interference
The model starts a local GUI that shows configuration parameters for the loaded LLM as well as fields to customize the prompt.
The chat prompt can be inserted, and a new screen loads that shows the chat.

Alternatively, you can use the REST API endpoint, which is OpenAI API compatible.
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer no-key" \
-d '{
"model": "LLaMA_CPP",
"messages": [
{
"role": "user",
"content": "You are a helpful AI assistant. Please answer the following question. Question: Which active space exploration missions are conducted by NASA? Answer:"
}
]
}' | python3 -c '
import json
import sys
json.dump(json.load(sys.stdin), sys.stdout, indent=2)
print()
'
Stats
slot 0 is processing [task id: 0]
slot 0 : kv cache rm - [0, end)
print_timings: prompt eval time = 6242.70 ms / 81 tokens ( 77.07 ms per token, 12.98 tokens per second)
print_timings: eval time = 5921.72 ms / 44 runs ( 134.58 ms per token, 7.43 tokens per second)
print_timings: total time = 12164.42 ms
slot 0 released (125 tokens in cache)
{"timestamp":1709754335,"level":"INFO","function":"log_server_request","line":2386,"message":"request","remote_addr":"127.0.0.1","remote_port":42124,"status":200,"method":"POST","path":"/v1/chat/completions","params":{}}
{"timestamp":1709754373,"level":"INFO","function":"log_server_request","line":2386,"message":"request","remote_addr":"127.0.0.1","remote_port":36244,"status":500,"method":"POST","path":"/v1/chat/completions","params":{}}
slot 0 is processing [task id: 46]
slot 0 is processing [task id: 46]
slot 0 : kv cache rm - [0, end)
print_timings: prompt eval time = 4423.04 ms / 58 tokens ( 76.26 ms per token, 13.11 tokens per second)
print_timings: eval time = 67587.39 ms / 473 runs ( 142.89 ms per token, 7.00 tokens per second)
print_timings: total time = 72010.43 ms
slot 0 released (531 tokens in cache)
Text Output
NASA has several active space exploration missions, including:
1. Mars 2020: This mission is part of NASA's Mars Exploration Program and aims to search for signs of past or present life on the red planet. The rover is equipped with advanced instruments to study geology, climate, and potential habitability of Mars.
2. Europa Clipper: This mission is focused on exploring Jupiter's icy moon, Europa, which is believed to have a subsurface ocean that could harbor life. The spacecraft will conduct detailed studies of the moon's surface and subsurface environment.
3. Psyche: This mission is set to explore an asteroid named Psyche, which is thought to be the remains of an early planetary building block. It aims to understand the asteroid's composition and history.
4. Artemis I: The first flight in NASA's Artemis program, this mission will send an uncrewed Space Launch System (SLS) rocket to the Moon, demonstrating its capabilities and paving the way for future crewed missions to the lunar surface.
5. James Webb Space Telescope: This ambitious project is set to study the universe's earliest galaxies, stars, and planetary systems. The telescope will be able to observe infrared light from distant objects, providing new insights into the history of our cosmos.
6. Nancy Grace Roman Space Telescope: This mission will study the formation and evolution of galaxies in the universe, focusing on the early universe when stars and galaxies were forming. It is set to launch in 2031.
7. WFIRST: The Wide-Field Infrared Survey Telescope (WFIRST) will conduct a survey of the sky in infrared light, searching for distant galaxies and studying dark energy's effects on the universe's expansion. It is expected to launch in 2028.
These are some of NASA's active space exploration missions, showcasing the agency's commitment to advancing our understanding of the universe and its many mysteries.
PrivateGPT
| CLI | API | GUI | GPU Support | NVDIA | AMD | Included Models |
|---|---|---|---|---|---|---|
| ❌ | ✅ | ✅ | ✅ | ✅ | ✅ | 6 (and any model in GGUF format) |
This project aims to provide a local LLM chat application complete with chat history and a vector databases to use local documents as chat material. Its installation is highly modular, enabling choices such as the LLM interference engine (local ollama or lllama.cpp, online AWS Sagemake or OpenAI), embeddings models, and vector databases (qdrant, chroma, postgres).
Installation & Model Loading
git clone https://github.com/imartinez/privateGPT
cd privateGPT
pyenv install 3.11
pyenv local 3.11
poetry install --extras "ui llms-ollama"
To use the ollama backend (and the mistal7b model), you also need to execute the following statements:
ollama pull mistral
ollama serve
Model Interference
Start the PrivateGPT application:
poetry run python3.11 -m private_gpt
It can be accessed via GUI and a REST API endpoint.
Stats
During startup, details about the model configuration are printed.
llm_load_vocab: special tokens definition check successful ( 259/32000 ).
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 32000
llm_load_print_meta: n_merges = 0
llm_load_print_meta: n_ctx_train = 32768
llm_load_print_meta: n_embd = 4096
llm_load_print_meta: n_head = 32
llm_load_print_meta: n_head_kv = 8
llm_load_print_meta: n_layer = 32
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_gqa = 4
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: n_ff = 14336
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 1000000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_yarn_orig_ctx = 32768
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: model type = 7B
llm_load_print_meta: model ftype = mostly Q4_K - Medium
llm_load_print_meta: model params = 7.24 B
llm_load_print_meta: model size = 4.07 GiB (4.83 BPW)
llm_load_print_meta: general.name = mistralai_mistral-7b-instruct-v0.2
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: PAD token = 0 '<unk>'
llm_load_print_meta: LF token = 13 '<0x0A>'
llm_load_tensors: ggml ctx size = 0.12 MiB
llm_load_tensors: mem required = 4165.48 MiB
During interference, familiar llama.cpp stats are printed:
llama_print_timings: load time = 17548.65 ms
llama_print_timings: sample time = 139.83 ms / 359 runs ( 0.39 ms per token, 2567.42 tokens per second)
llama_print_timings: prompt eval time = 13967.01 ms / 82 tokens ( 170.33 ms per token, 5.87 tokens per second)
llama_print_timings: eval time = 71151.92 ms / 358 runs ( 198.75 ms per token, 5.03 tokens per second)
llama_print_timings: total time = 182317.19 ms
Text Output
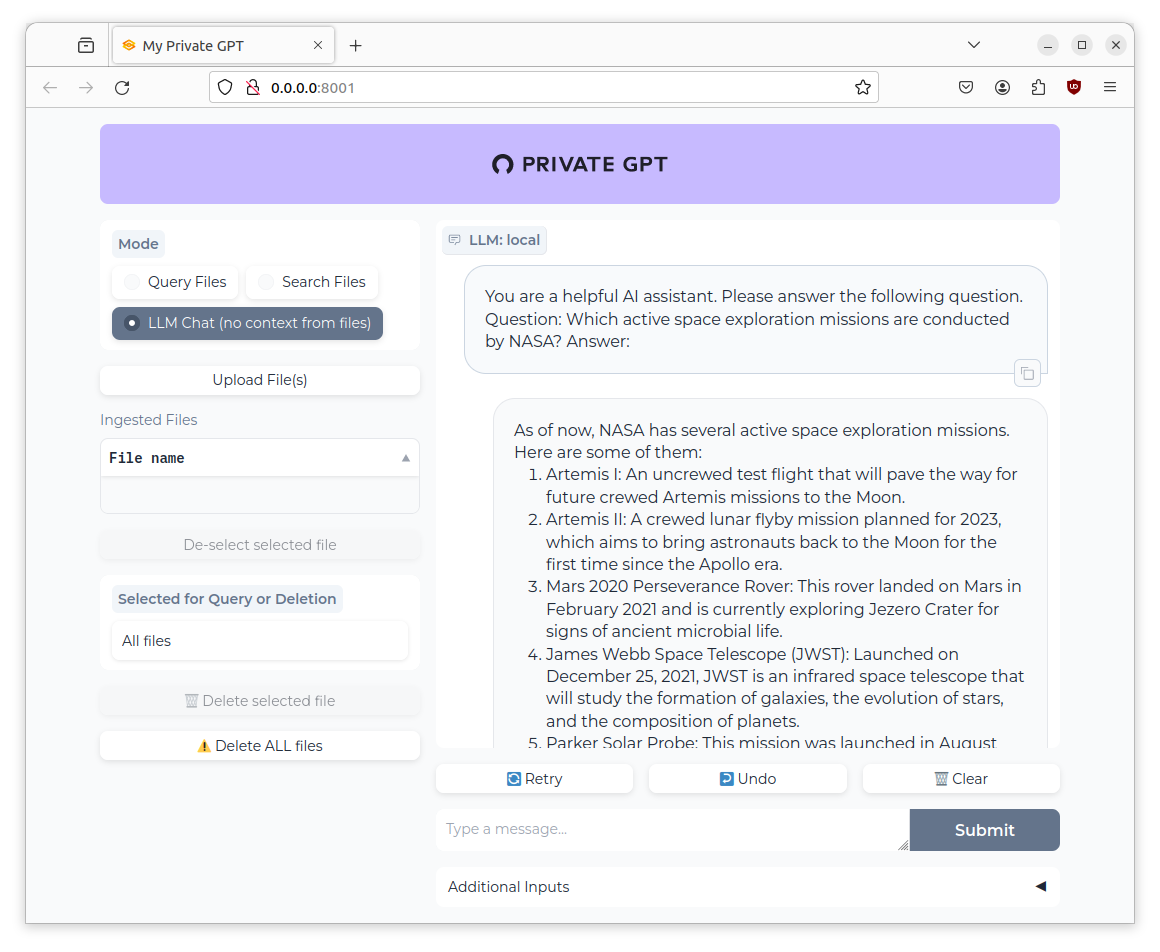
As of now, NASA has several active space exploration missions. Here are some of them:
1. Artemis I: An uncrewed test flight that will pave the way for future crewed Artemis missions to the Moon.
2. Artemis II: A crewed lunar flyby mission planned for 2023, which aims to bring astronauts back to the Moon for the first time since the Apollo era.
3. Mars 2020 Perseverance Rover: This rover landed on Mars in February 2021 and is currently exploring Jezero Crater for signs of ancient microbial life.
4. James Webb Space Telescope (JWST): Launched on December 25, 2021, JWST is an infrared space telescope that will study the formation of galaxies, the evolution of stars, and the composition of planets.
5. Parker Solar Probe: This mission was launched in August 2018 to study the Sun at close range and understand its fundamental physics, particularly the solar wind and solar storms.
6. OSIRIS-REx: Launched in September 2016, this spacecraft reached asteroid Bennu in December 2018 and is currently collecting samples for return to Earth in 2023.
7. Voyager 1 & 2: Although no longer active, these probes are still providing valuable data as they continue their journeys through interstellar space.
These missions represent a diverse range of objectives and destinations, all aimed at expanding our knowledge of the universe.
Document Upload
On the left side of the UI, you see the option to upload documents. I tried a TXT and PDF file, both works fine. The vectorization process automatically defines text chunks from the imported source and adds them to its database. Once completed, you need to activate the mode “Query Files” and select which documents should be considered for generating an answer.
In the following example, I created a PDF file from the Wikipedia article list of NASA missions, uploaded this document, and used the same prompt.
Interestingly, the log output shows the essentials of a retrieval augmented generation framework: A special system prompt, and the context which are excerpts from the provided file.
<s>[INST] Context information is below.
--------------------
NASA.November 6, 2013. Archived (https://web.archive.org/web/20151018013715/http://www.nasa.gov/mission_pages/mms/launch/index.html) from the original on October 18, 2015. RetrievedNovember 3, 2015.38. "NASA Selects Science Investigations for Solar Probe Plus" (http://www.nasa.gov/topics/solarsystem/sunearthsystem/main/solarprobeplus.html). NASA. Archived (https://web.archive.org/web/20120504235842/http://www.nasa.gov/topics/solarsystem/sunearthsystem/main/solarprobeplus.html) from the original on May 4, 2012.
Comparison of NASA Mercury,Gemini, Apollo, and Space Shuttlespacecraft with their launch vehicles
DiscoverySTS-120 launch,October 23, 2007List of NASA missionsThis is a list of NASA missions, both crewed and robotic,since the establishment of NASA in 1957. There are over 80currently active science missions. [1]Since 1945, NACA (NASA's predecessor) and, since January 26,1958, NASA has conducted the X-Plane Program.
--------------------
You can only answer questions about the provided context. If you know the answer but it is not based in the provided context, don't provide the answer, just state the answer is not in the context provided. [/INST]</s>[INST] You are a helpful AI assistant. Please answer the following question. Question: Which active space exploration missions are conducted by NASA? Answer: [/INST]
The text output is this:
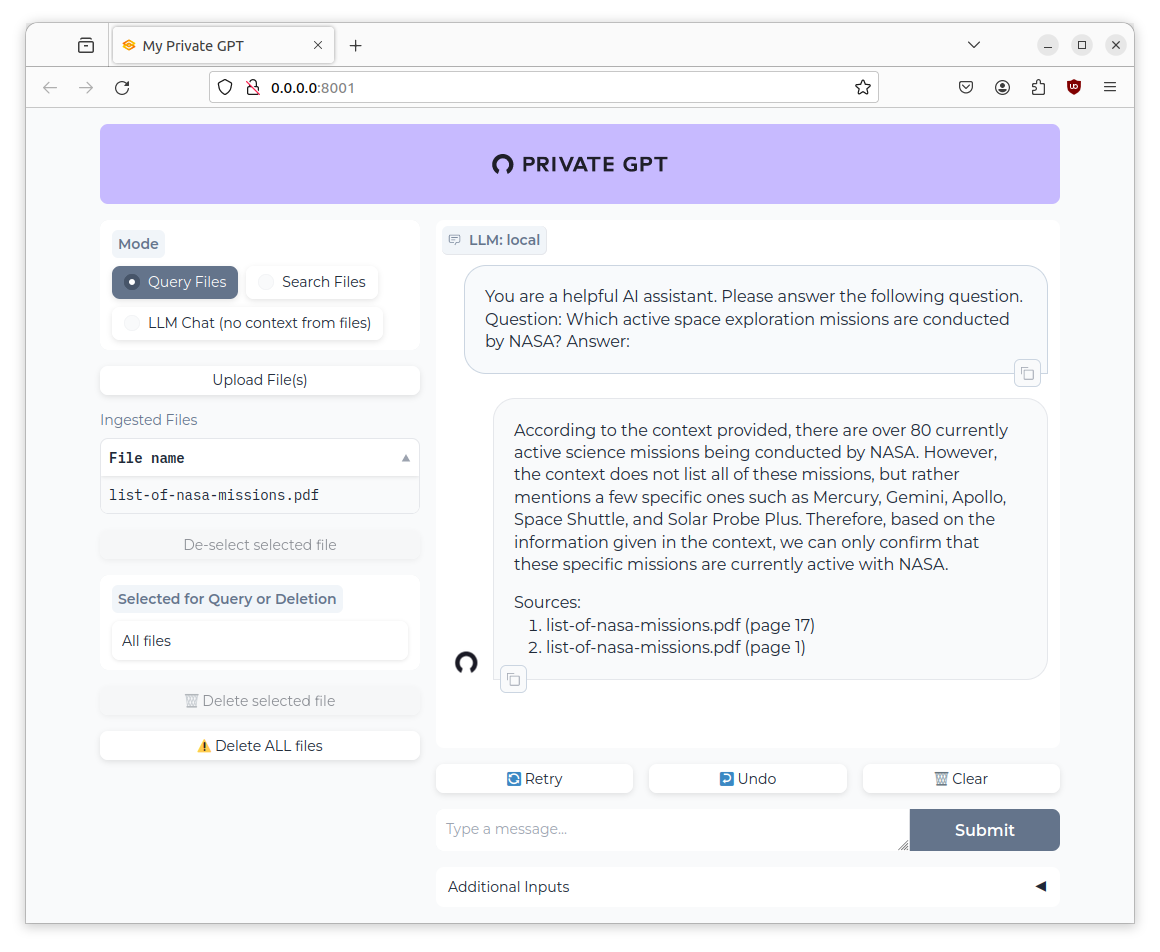
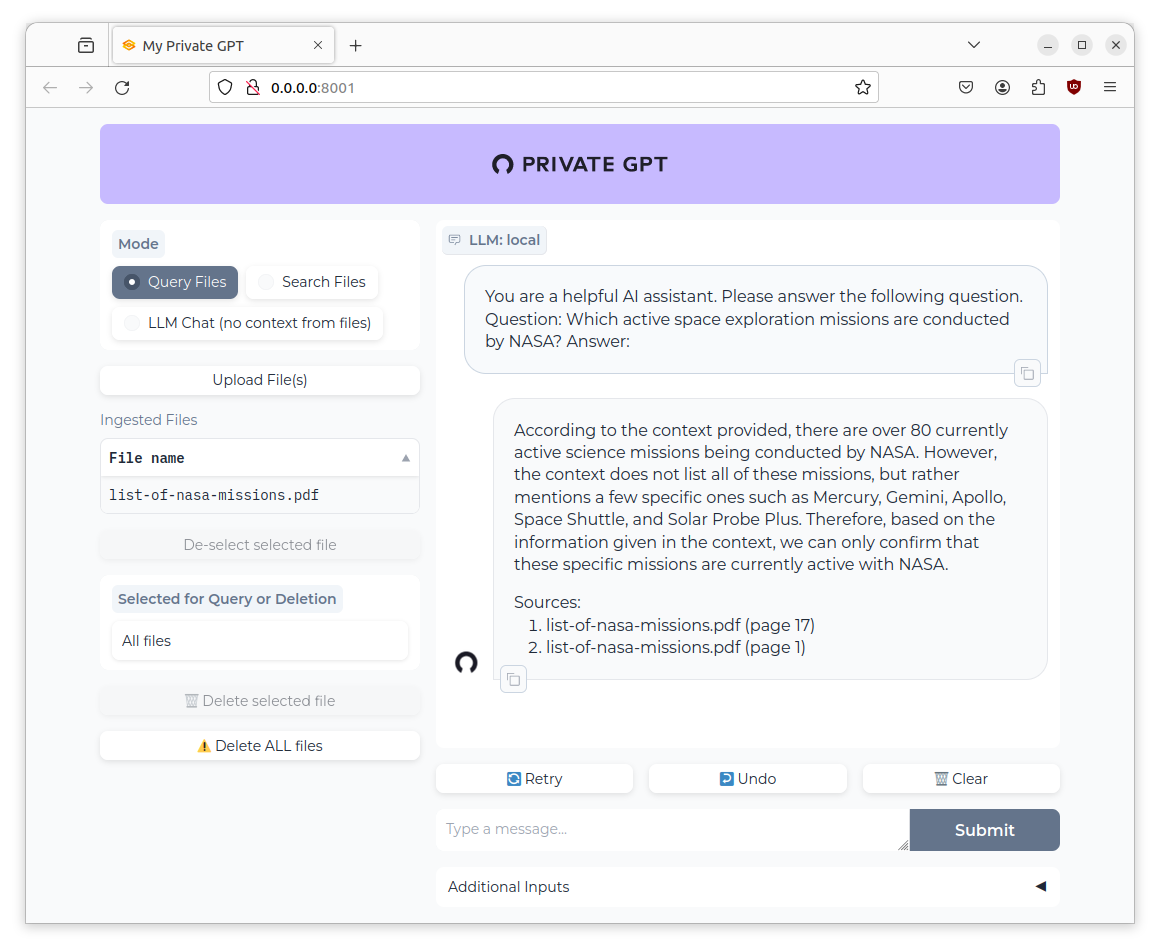
According to the context provided, there are over 80 currently active science missions being conducted by NASA. However, the context does not list all of these missions, but rather mentions a few specific ones such as Mercury, Gemini, Apollo, Space Shuttle, and Solar Probe Plus. Therefore, based on the information given in the context, we can only confirm that these specific missions are currently active with NASA.
LM Studio
| CLI | API | GUI | GPU Support | NVDIA | AMD | Included Models |
|---|---|---|---|---|---|---|
| ❌ | ❌ | ✅ | ✅ | ✅ | ✅ | 6 (and any model in GGUF format) |
This project is a GUI-first application that brings multi-model LLMs to your desktop. The GUI enables model downloads, configuration, logs, and a chat GUI with file upload/download. It supports any GGUF model file and is available for Windows, Linux and OsX with ARM processors.
Installation & Model Loading
wget --continue -O lm-studio.bin https://releases.lmstudio.ai/linux/0.2.14/beta/LM_Studio-0.2.14-beta-1.AppImage
chmod +x lm-studio.bin
./lm-studio.bin
If you receive the error message AppImages require FUSE to run, then run these commands:
./lm-studio.bin --appimage-extract
./squashfs-root/AppRun
To load a model, go to the Search area, then select the appropriate model.
Model Interference
Interference is started by selecting the chat icon and choosing the model.
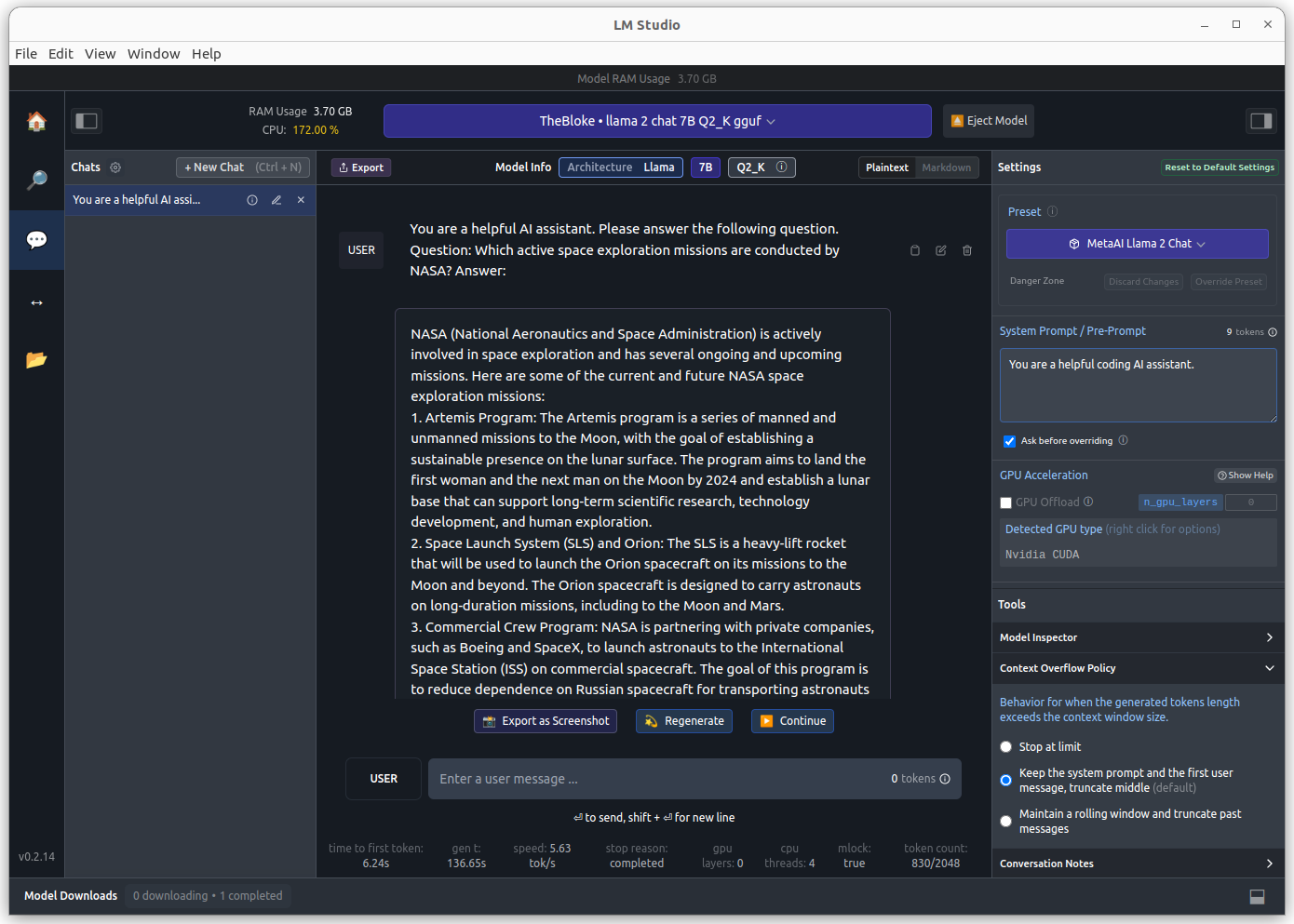
Stats
During application loading, details about the target computer and the loaded model are shown.
8:49:43.969 › GPU Preferences: {"gpuType":"unknown","modelFileFormat":"gguf"}
18:49:43.971 › GPU type cached in preferences: unknown
18:49:43.971 › Got GPU Type: unknown
18:49:43.972 › Loading default compilation.
18:49:44.063 › GPU info: '07:00.0 VGA compatible controller: NVIDIA Corporation GM204 [GeForce GTX 970] (rev a1)'
18:49:44.063 › Got GPU Type: nvidia
18:49:44.064 › LM Studio: gpu type = NVIDIA
CPU Info: 0 547094953 0 0
AVX2 Supported: Yes
[LLM Engine bindings] LoadModelWithConfig
Model path: /home/devcon/.cache/lm-studio/models/TheBloke/Llama-2-7B-Chat-GGUF/llama-2-7b-chat.Q2_K.gguf
llama_model_loader: loaded meta data with 19 key-value pairs and 291 tensors from /home/devcon/.cache/lm-studio/models/TheBloke/Llama-2-7B-Chat-GGUF/llama-2-7b-chat.Q2_K.gguf (version GGUF V2)
...
llama_model_loader: - type f32: 65 tensors
llama_model_loader: - type q2_K: 65 tensors
llama_model_loader: - type q3_K: 160 tensors
llama_model_loader: - type q6_K: 1 tensors
llm_load_vocab: special tokens definition check successful ( 259/32000 ).
llm_load_print_meta: format = GGUF V2
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 32000
llm_load_print_meta: n_merges = 0
llm_load_print_meta: n_ctx_train = 4096
llm_load_print_meta: n_embd = 4096
llm_load_print_meta: n_head = 32
llm_load_print_meta: n_head_kv = 32
llm_load_print_meta: n_layer = 32
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: n_embd_k_gqa = 4096
llm_load_print_meta: n_embd_v_gqa = 4096
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-06
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: n_ff = 11008
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 10000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_yarn_orig_ctx = 4096
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: model type = 7B
llm_load_print_meta: model ftype = Q2_K - Medium
llm_load_print_meta: model params = 6.74 B
llm_load_print_meta: model size = 2.63 GiB (3.35 BPW)
llm_load_print_meta: general.name = LLaMA v2
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: LF token = 13 '<0x0A>'
llm_load_tensors: ggml ctx size = 0.11 MiB
llm_load_tensors: offloading 0 repeating layers to GPU
llm_load_tensors: offloaded 0/33 layers to GPU
llm_load_tensors: CPU buffer size = 2694.32 MiBlama_new_context_with_model: n_ctx = 2048
Model interference stats are also shown.
llama_print_timings: load time = 1589.54 ms
llama_print_timings: sample time = 260.82 ms / 767 runs ( 0.34 ms per token, 2940.75 tokens per second)
llama_print_timings: prompt eval time = 6233.43 ms / 64 tokens ( 97.40 ms per token, 10.27 tokens per second)
llama_print_timings: eval time = 136066.06 ms / 766 runs ( 177.63 ms per token, 5.63 tokens per second)
llama_print_timings: total time = 419273.29 ms / 830 tokens
Text Output
NASA (National Aeronautics and Space Administration) is actively involved in space exploration and has several ongoing and upcoming missions. Here are some of the current and future NASA space exploration missions:
1. Artemis Program: The Artemis program is a series of manned and unmanned missions to the Moon, with the goal of establishing a sustainable presence on the lunar surface. The program aims to land the first woman and the next man on the Moon by 2024 and establish a lunar base that can support long-term scientific research, technology development, and human exploration.
2. Space Launch System (SLS) and Orion: The SLS is a heavy-lift rocket that will be used to launch the Orion spacecraft on its missions to the Moon and beyond. The Orion spacecraft is designed to carry astronauts on long-duration missions, including to the Moon and Mars.
3. Commercial Crew Program: NASA is partnering with private companies, such as Boeing and SpaceX, to launch astronauts to the International Space Station (ISS) on commercial spacecraft. The goal of this program is to reduce dependence on Russian spacecraft for transporting astronauts to the ISS.
4. Space Technology Mission Directorate (STMD): STMD is responsible for developing new technologies that can be used in future NASA missions. Some of the current projects include the development of advanced propulsion systems, materials for spacecraft and habitats, and radiation protection for astronauts.
5. Europa Clipper: This mission will send a spacecraft to explore Jupiter's icy moon Europa, which is believed to have a liquid water ocean beneath its surface. The mission will study the moon's subsurface ocean and search for signs of life.
6. Mars Exploration Program: NASA has several ongoing and future missions to Mars, including the Curiosity and Perseverance rovers, which are exploring the Red Planet's surface and studying its geology and climate. Future missions include the Mars 2024 and Europa Clipper missions mentioned above.
7. Wide Field Infrared Survey Telescope (WFIRST): This mission will study the universe in infrared light, providing insights into the formation of galaxies, stars, and planets. The mission will also study the distribution of dark matter and dark energy in the universe.
8. James Webb Space Telescope: The James Webb Space Telescope is a successor to the Hubble Space Telescope and will be the most powerful telescope ever built. It will study the formation of the first stars and galaxies, the evolution of the universe, and the origins of life on Earth and in the universe.
9. Parker Solar Probe: This mission will explore the Sun's corona, the outer atmosphere of the Sun, and study the solar wind, which affects Earth's climate and space weather. The mission will provide insights into the Sun's dynamics and how it affects the solar system.
10. Roman Space Telescope: This mission will explore the universe in visible light, providing insights into the formation of galaxies, stars, and planets. The mission will also study the distribution of dark matter and dark energy in the universe.
These are just a few examples of the many active space exploration missions conducted by NASA. Each mission is an exciting step towards expanding our understanding of the universe and the mysteries it holds.
Comparison
All libraries at a glance:
| Library | CLI | API | GUI | GPU Support | NVDIA | AMD | Included Models |
|---|---|---|---|---|---|---|---|
| Lit GPT | ✅ | ❌ | ❌ | ✅ | ✅ | ❌ | 20 |
| LocalAI | ❌ | ✅ | ❌ | ✅ | ✅ | ❌ | 16 (and any model in GGUF format) |
| llamafile | ❌ | ✅ | ✅ | ✅ | ✅ | ✅ | 9 (and any model in GGUF format) |
| PrivateGPT | ❌ | ✅ | ✅ | ✅ | ✅ | ✅ | 6 (and any model in GGUF format) |
| Lm Studio | ❌ | ❌ | ✅ | ✅ | ✅ | ✅ | 6 (and any model in GGUF format) |
| — | — | — | — | ———– | —– | — | ————————- |
Additional Tools
During the research for this article, I encountered additional libraries concerned with LLM hosting. While not fitting the scope of running current LLMs on modest hardware, they are listed here for others who are curious to explore the landscape of libraries.
- AutoGPTQ: Comprehensive library for LLM quantization using the GPTQ algorithm. Its API extends HuggingFace Transformers for integrated quantization and language tasks like completions, causal generation, and more. NVDIA and AMD GPUs are supported.
- gptq: A new state of the art quantization method. The project includes scripts to quantize OPT and BLOOM models as well as running language perplexity and zero-shot benchmarks.
- Intel Extension for Transformers: A serving platform and framework for running LLMs on Intel processors. The repository contains an extensive list of tutorials and examples starting with several quantization and compression techniques, evaluating performance, and building language generators or chatbots with Python. It also integrates with the Transformers and LangChain library.
- lit-llama: Pretraining, fine-tuning and interference of the LLaMA model. This precursor project to lit-gpt also aims to make LLMs usage accessible to a wide audience.
- nanoGPT: Fine-tuning Gen1 and Gen2 LLMs like GPT2. It provides comprehensive scripts to load custom fine-tuning datasets and start the training process.
- Shell GPT: A helper tool included in your terminal shell to generate bash and other scripts. It connects to OpenAI APIs for generating the code. Alternatively, you can run local models with Ollama.
- vllm: Running LLMs at scale supporting Docker, Kubernetes, and NVIDIA Triton for hosting distributed LLMs over several nodes. Supports native quantization methods, NVIDIA and AMD GPUs, and several Transformers compatible models.
- whisper.cpp: Speech recognition based on OpenAIs whisper library. Developed by the same person as the ggml library, it shows again how to port a complex technology to several target devices, including computers, mobile phones, and even the browser.
Conclusion
Running large language models on your local computer is a fascinating experience. Through quantization and special file formats, 7B models can be run locally, giving you full command of an LLM as a standalone tool or component for an application. This article explored another 5 libraries: Lit GPT, LocalAI, llamafile, PrivateGPT, LM Studio. They support LLM interactions using CLI, REST API or GUI. An interesting trend is that the GGUF file format becomes dominant, which gives access to a continously growing amount of models.