
Large Language Models (LLMs) are a ubiquities technology enabling humans to use their natural language for interacting with a computer in a broad range of tasks. LLMs can answer questions about history and real-world events, they can create step-by-step tasks plans, solve mathematical questions, and can reflect on any input text to create summaries or identify text characteristics. Using most recent LLMs like GPT4 is a fascinating and surprising event.
This article is a gentle introduction to Large Language Models, covering their origin, their architecture and training. Concretely, you will learn how LLMs evolved from a machine learning model called neural networks to today’s transformer architecture, how a LLM is trained using established machine learning practices, and then fine-tuned for specific tasks or domains. Finally, a list of different LLM generations is presented that shows the continued evolution of these models.
Machine Learning Origin
Machine learning is a branch of computer science. It investigates how complex data can be processed to cluster or classify data as well as to predict values based on an input. Two main machine learning approaches can be distinguished: supervised learning and unsupervised learning.
In supervised learning, input data and expected results are defined, and an algorithm is trained on this data to make as many correct predictions as possible. Algorithms such as decision trees, support vector machines and Bayesian networks are used to identify patterns in the input data. Often, the data scientists that train these models understand the data patterns, apply manual feature engineering to structure the algorithms accordingly.
In contrast, unsupervised learning contains input data only, no expected values. Machine learning algorithms need to identify data patterns themselves. The most successful model, discovered so far, are neural networks. In essence, individual neurons, also called perceptons, are connected with each other and stacked as layers upon layers. The complexity of the network scales with the complexity of the data they need to process. With the ever-increasing computing power and availability of high-quality input data, neural networks systematically conquered all domains, from pure numerical problems to computer vision and to natural language processing.
In 2013, the research paper Efficient Estimation of Word Representations in Vector Space started the revolution of NLP with neural network. The essential idea in this paper is that word meanings can be represented as multi-dimensional numerical vectors. This data structure is a learned statistical representation which can be scaled from individual words to sentences and even whole paragraphs. In short: When neural networks are applied to texts, they learn the structure of human language themselves. Accordingly, all classical NLP tasks, such as classification, sentiment analysis, and even question-answering, became dominated by neural networks, which greatly surpass the performance of other machine learning algorithms. This evolution led to today’s Large Language Models.
Neural Network Architectures
The simplest form of a neural network is named fully-connected or dense, which means that all neurons of one layer are connected to all neurons of the next layer. Each neuron applies a linear function in the form of y= a*x + b, where b is the bias value and a the neurons weight. In very simplified terms, neural network training consists of applying random values for the weights and the biases, then processing input to output data through all the layers, and then applying backpropagation to change the bias and the weight values so that the output value gradually becomes better.
Several other architectures evolved that introduced variations to how the neurons are connected, how they calculate their output value, and how they can re-access past input values. In a convolutional network, a special kernel function is applied to reduce the dimensionality of the input values. In graph neural networks, the neurons are connected as an arbitrary graph structure such as a directed acyclic graph. And in LSTM networks, the neurons have an additional memory that determines how important recurring data is or allow to selectively ignore data.
![]()
Source: Wikipedia, Transformer (machine learning model), https://en.wikipedia.org/wiki/Transformer_(machine_learning_model)
The most sophisticated architecture developed so far is called the transformer. In this complex neural network, encoder and decoder layers work in tandem to first produce a sophisticated representation of the input data, and then to decode this learned structure into an output. Considering the above picture, the encoder itself consists of two subsequent layers: A multi-head attention layer, in which neurons process input values according to an attention matrix, followed by a feed-forward layer that normalizes the computed values. The decoder consists of three layers: A multi-head attention layer that processes the input value, an attention layer that processes the learned encodings of the input values, and a feed-forward layer. This architecture enables to learn complex patterns from its input, with the full ability to provide local attention to parts of the input data with respect to all available input data.
The predominant architecture for Large Language Model in 2021-2024 is the transformer. Although in essence transformers just predict the probability of the very next word given a context, their complexity also captures the syntactic nuances of the language, its grammar, and the morphology of words, as well as its semantics. Therefore, individual words, chunks and whole sentences are represented as high-dimensional embeddings expressing the aspects of natural language with numerical values. Three types of transformer need to be distinguished: Encoder-only, decoder-only, and encoder-decoder networks. The decoder-only type features the most prominent LLMs such as all GPT variants.
LLM Training and Fine-Tuning
A large language model is trained similar like other machine learning algorithms following these steps:
- Input data preprocessing: Input data is text, but text is specifically encoded, stems from a particular natural language, and adheres to its language grammar in various degrees. To achieve a high-quality output, the input data needs to be filtered, sanitized and deduplicated. Typical preprocessing pipelines include replacing special characters with a uniform encoding, calculating a quality score on texts and content filtering to remove unwanted text, followed by deduplicating and finally tokenizing the input.
- Model definition: In this step, the concrete model architecture is determined. For transformers, this means to determine the number of multi-attention and feed-forward layers and determining the number or neurons in each layer. In addition, the input text is converted to an embedding, a multi-dimensional vector that represents each token with a numeric values. The input shape of the transform is a matrix of number of sequences, the length of sequences, and the embedding dimensions.
- Model training: The training goal of LLMs is mostly masked token or next token prediction. In the masked token goal, the input sequence are tokens of sequence length with one or multiple tokens represented by a special token like
. And in next word prediction, the input is a set of tokens with a specific sequence length for which the model needs to determine the very next token. In both goals, the LLMs computes a probability matrix for all words from its vocabulary. This matrix is compared with the expected value to calculate the accuracy of the model. Then, using backpropagation, the weight and biases of all neurons are updated, and a new training run begins. A factor unique to LLM training is size: Consuming terabytes of text and billions of tokens requires large amounts of GPU memory and processing power, runs typically on cloud infrastructure sor several days or even weeks. - Model usage: Also called interference, this is the process of loading the trained models weight and biases, converting an input text into an embedding representation, feed this input into the network, and then convert the embedded output to a text representation.
LLMs can be distinguished into three types: pre-trained/foundation, task fine-tuned, instruction fine-tuned. Foundation models are trained on the original input data only. They can be used for classical NLP tasks, including text classification or sentiment analysis, up to advanced tasks like text generation, information retrieval, and knowledge interfering. But these capabilities, as well as factual knowledge, are limited by their training data. When the input concerns text included in the training material, for example Wikipedia, the model will accurately generate text from these sources. However, if the input is from a newer version of the same material, or an entirely new domain, such as law, then the model might not perform adequately.
To overcome this challenge, models are fine-tuned for the new domain. In task fine-tuning, the models are given a task definition and an expected output, such as performing logical interference or applying mathematical calculations. This data is used to additionally train the model, often using the same training environment and parameters. In Instruction-fine tuning, the input data contains a detailed context how to resolve a task. The expected output is provided, but during training, the model is tested how well it generalizes instructions to new tasks that are included in the testing dataset only.
LLM Evolution
Large Language Models have undergone a fascinating evolution. From 2018 to early 2024, hundreds of models were created. These models can be differentiated into 4 generations as of now, separating mostly the model complexity, but also aspects like model parameters (embeddings encoding, activation functions), amount and quality of input data, and additional fine tuning steps.
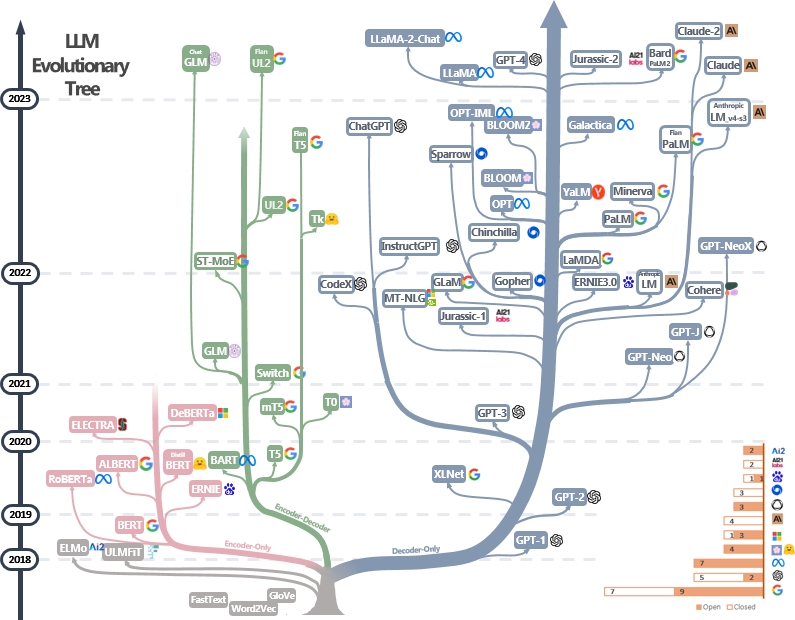
Source: Yang et. al 2023, Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond, https://arxiv.org/abs/2304.13712
Following the above picture, roughly 4 generations can be distinguished:
- gen1 (2018-2020)
- BERT
- GPT1
- RoBERTa
- DistillBERT
- GPT2
- BART
- XLNET
- T5
- gen2 (2020-2022)
- GPT3
- GPT-J
- CodeX
- GPT-Neo X
- gen3 (2022-2023)
- Bloom
- Flan T5
- MT5
- PaLM
- OPT IML
- Closed Source (ChatGPT, GPT3, GPT3.5)
- gen4 (2023 +)
- Falcon
- GLM
- LLaMA
- UL2
- Closed-Source (Bard, Claude, Jurassic-2, Pi, GPT-4)
Conclusion
This article gave a concise introduction to large language models. You learned that the scientific discipline of machine learning is the origin of data pattern recognition and output generation - in which different algorithms were discovered. A highly sophisticated algorithm are neural networks, connections of neurons performing input-output data computation that can be scaled in size and complexity to automatically learn complex data patterns. Neural network architectures evolved to the transformer model, and this architecture is the predominant form for all LLMs in 2021-2024. Following this origin, you also learned that LLMs follow the same steps as other machine learning models: preprocessing the input data, model definition and training. These models are usually fine-tuned for specific tasks or instructions, leading to state-of-the art performance in many NLP tasks. The article concluded with a short list of LLM generations and concrete models.