With my Lighthouse-as-a-Service website scanner you can quickly check a webpage about its performance, SEO and best practices. You can use the scanner here: https://lighthouse.admantium.com/.
The original architecture of my lighthouse-as-a-service scanner consisted of three parts: A webpage, a backend services to request and execute scans, and a database to store jobs and scan results. I considered the backend a microservice. But during a redesign, when I was experimenting with serverless functions, I realized that the backend is actually a monolith with three distinct tasks: Delivering the static webpage, an API for querying about jobs, and a worker for executing scans.
Initially, I wanted the backend service to scale vertically: More instances can provide more scans at the same time. But this is the crucial aspect: Only the worker part needs to be scaled. The other responsibilities can be served by components which only require few resources. The worker, however, consumes a lot CPU and RAM when scanning a webpage.
From here on, it became clear I need to refactor my application. Read about this developer journey to learn how careful service refactoring can improve your application design.
Note: The lighthouse service is discontinued since 2024-05-18.
Service 1: Static Webpage
The first service was very easy to extract and put into a dedicated container.
The webpage code for lighthouse.admantium.com is generated from multiple templates. Also, a custom JavaScript for the frontend effects and communicating with the API is delivered. All of this can be exported to static HTML. And this HTML can be delivered from inside a NGINX container.
The container’s Dockerfile is this:
FROM nginx:1.19.0
COPY ./src/dist /usr/share/nginx/html
COPY ./conf/default.conf /etc/nginx/conf.d/default.conf
COPY ./conf/nginx.conf /etc/nginx/nginx.conf
Besides the static HTML, I also modify the Nginx configuration file to resolve requests to /api to the API container. This container now only needs 4,5MB and less than 0.1 CPU units to run!
Service 2: API
The API has two primary routes. At /jobs, the status of any job can be requested. And at /scan, new scan requests can be scheduled. The API part is written with the HAPI framework, and it is stateless because all data is stored in Redis.
Refactoring the API part consisted of these steps:
- Remove the delivery of the webpage code
- Remove all functions for executing scan requests
- Simplify health check to return just an HTTP 200 for the main process.
This container’s Dockerfile is quite clean.
FROM node:lts-alpine3.11
WORKDIR /etc/lighthouse-api
COPY package.json .
RUN npm i
COPY app.js .
COPY src/ ./src
EXPOSE 8080
ENTRYPOINT ["/usr/local/bin/node"]
CMD ["app.js"]
The API runs a node process, which consumes about 40MB and 0.3 CPU units.
Service 3: Worker
The worker has a minimal HTTP API, the endpoint /scan, to accept new scan requests. Scanning is a CPU and RAM intensive process, and to keep this service in check, I added the following features:
- Before spawning a scan process, execute a
pingto validate that the domain exists - The worker has a counter for the number of concurrent scan requests, it can only handle 3 scans at the same time and will deny each new request
- After scanning, clean up all forked child processes
Rewriting the worker also improved error introspection: Whether a scan cannot be completed because the webpage has an error, or whether the process runs into a resource trap, is now better handled and better reported.
This container’s Dockerfile looks very similar to the APIs container - only the workdir is different.
FROM node:lts-alpine3.11
WORKDIR /etc/lighthouse-scanner
COPY /package.json .
RUN npm i
COPY /app.js .
COPY /src/ ./src
EXPOSE 8080
ENTRYPOINT ["/usr/local/bin/node"]
CMD ["app.js"]
The worker container runs as a node process. Initially, it only consumes about 40MB and 0.3 CPU units, but executing 3 scans can take up to 750MB and 0.75 CPU.
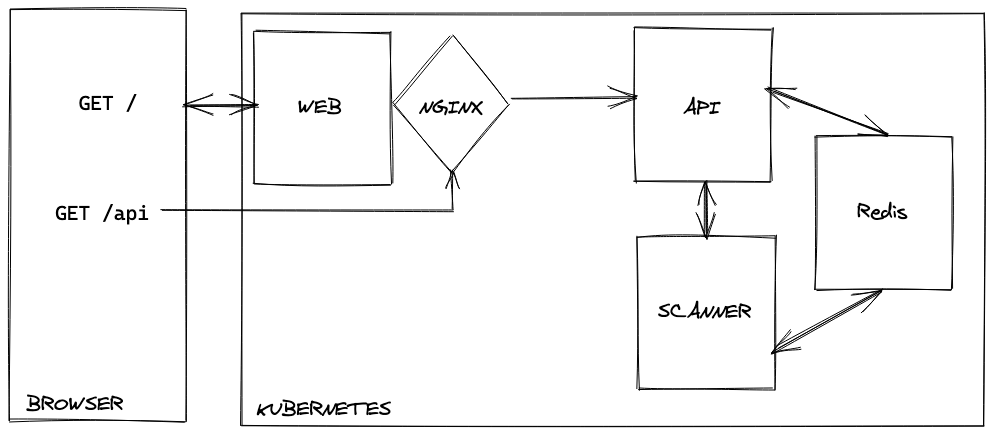
The final architecture
After rewriting, my lighthouse-as-a-service scanner has this beautiful architecture
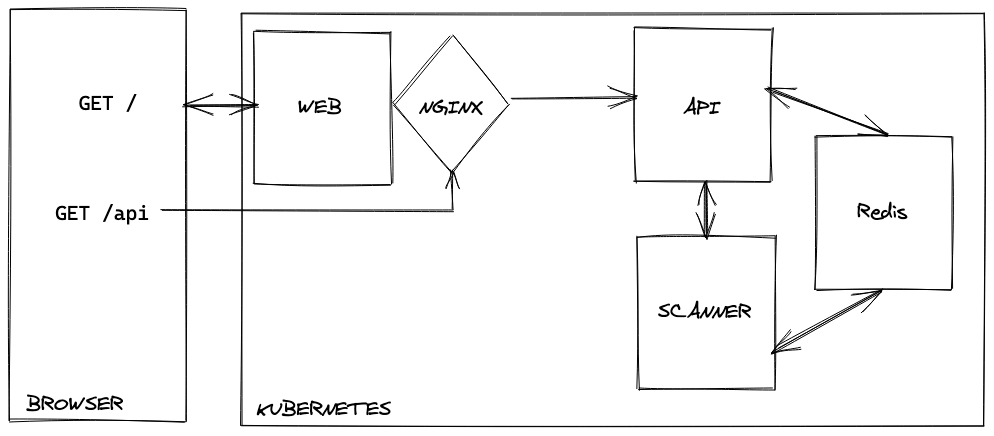
As outlined, the clear resource utilization gives great control for scalability. The Web and API containers can run as single process. The worker container is scaled with a fixed number of replicas, and now I can investigate advanced autoscaling features.
Do You Need Microservice in Small Teams?
What is the implication of small microservices, and why are they used in companies? Microservices allow scaling not only in computing resources, but also in scope, functionality, technology and development teams. When an application is decomposed into let’s say 20 microservices, different application teams can take the responsibility for them. The company might see some microservices as especially important for the users, or important for providing insight into data. These microservices can be focused and developed with more focus or speed than others.
On the downside, microservices introduce more complexity. Communication between microservices must be carefully planned and implemented: Protocol, content, content type, status code, timeouts etc. State management is difficult. Has each microservice his own database? Is all data stored in a big database? And this technical complexity also introduces procedural and communication complexity for all developers.
So, what about if you are only a small team or solo? Still, you need to tackle the technical complexity. On the beneficial side, you can try different approaches for the microservices, using different frameworks or even programming languages. This is a chance for learning, for education.
Conclusion
This article showed how to deconstruct a monolithic application into independent microservices. My primary motivation was to separate the functionality for which I need horizontal scaling. However, I also discovered the chances of using different technologies for each functional part, and also to experiment with serverless functions and cloud functions. Microservices is definitely not a new concept, but one that still fascinates me and which I think to have not properly used in my projects so far. Let’s see what the insights from this refactoring bring me for the future.