Your Kubernetes cluster provides a finite amount of resources such as CPU, memory and storage. Carefully crafting resource limitations and health checks keeps your apps running.
A Kubernetes cluster consists of different nodes with their specific hardware configuration, proving a finite amount of CPU, memory and storage. You need to ensure that your application consumes only those resources that are needed. Containers that leak memory, or containers that spin out of control and consume all CPU resources, can disrupt service availability.
In this article, you learn two best practices for ensuring that your applications are running: Defining health checks and controlling computing resources. Combining those best practices ensures stability of your applications.
The Big Picture
What does it mean that an application is healthy? Inside a Container, an application or part of an application (microservice) runs. It is considered healthy when it satisfies the following conditions:
- It provides the required functionality
- It can consume the required amount of CPU, memory and storage
- It does not overconsume CPU, memory or storage
What could go wrong internally? When you execute a docker container, one main process is started. This process has the PID of 1. All other processes inside the running container are children of this main process. When child processes are not correctly terminated, they accumulate CPU and memory. Or the application gets into a deadlock state, it might not work anymore.
Kubernetes solves one problem automatically: If the application crashes, which means that the main process dies, a new container is deployed automatically. But to recognize the other malfunctions, we need to instruct Kubernetes how to observe them, and your application needs to provide a way to asses that it is still working. Per container, you need to instruct these checks:
- Readiness and Liveness
- The requests resources
- The resource limits
These checks are discussed in the next sections.
Defining Health Checks
Health checks are a built-in concept in Kubernetes. The kubelet components, which resides on each node, performs the health check. Health checks are defined per container. There are three different kind of health checks:
- Liveness: This check is about the pod being operational, meaning it provides the functionality and endpoints that are required. It specifically also means that the pod is not in a state of deadlock. If the liveness check fails, the pod will be terminated and replaced by a new one.
- Startup: This check complements liveness checks for pods which have a considerable startup time of some seconds up to minutes. It checks that the startup process is still ongoing. If the startup check fails, the pod will be terminated and replaced by a new one. When a pod has a liveness and startup check, the liveness check will be disabled until startup is complete.
- Readiness: This check ensures that a pod can receive requests. There are cases where a pod can only work on a limited number of items at the same time, e.g. generating reports. The readiness check determines if the pod can receive another request. If this check fails, the pod will be removed from the ingress for the time being. Once its read again, it will be added to the ingress.
To execute a health check, there are also three options:
exec: Run a script on the pod. Only the exit value of0will be considered as a successful check.httpGet: Execute a HTTP request. HTTP status codes in the range of200 - 300are considered successfultcpSocket: Connect to a TCP socket on the host. If the connection can be made, the check is successful
Let’s discuss two examples.
HTTP Health Check
The CNCF standardizes how container should operate with each other. One strong sign for this is the prevalent use of HTTP and HTTP API. For these reasons, the HTTP check command in Kubernetes is also the most versatile. You can define the port, path, schema and event HTTP headers to be passed.
In my Lighthouse application, I’m using HTTP checks for liveness and for readiness. Here is the relevant part from the Deployment declaration.
apiVersion: apps/v1
kind: Deployment
metadata:
name: lighthouse
spec:
replicas: 4
selector:
matchLabels:
app: lighthouse
template:
spec:
containers:
- name: lighthouse
image: docker.admantium.com/lighthouse:0.1.9
livenessProbe:
httpGet:
path: /liveness
port: 8080
periodSeconds: 10
readinessProbe:
httpGet:
path: /readiness
port: 8080
periodSeconds: 10
failureThreshold: 6
The last two lines in this listing show additional parameters for the execution logic and schedule of health checks : periodSeconds is the frequency in which the kubelet will execute the checks, and the failureThreshold is the number of failed checks before the container is considered unhealthy. The full list of attributes is shown below.
Exec Health Check
In my lighthouse application, I’m executing the scan with a custom scand daemon process. To determine that this background process is still alive, I execute the script /etc/scanner/health_check.sh inside its container. Se the last 6 lines in the following Deployment specification to see how it is defined.
apiVersion: apps/v1
kind: Deployment
metadata:
name: lighthouse
spec:
replicas: 1
selector:
matchLabels:
app: lighthouse
template:
spec:
containers:
- name: lighthouse
image: docker.admantium.com/lighthouse:0.1.9
livenessProbe:
exec:
command:
- /etc/scanner/health_check.sh
periodSeconds: 10
failureThreshold: 2
Let’s test this health check. I execute kubectl exec pod/lighthouse-575fd6fdd9-7fpts killall scand to stop all daemon processes in one of the pods. After some time, you can see that the health check fails, the pod status turns to unhealthy and is terminated shortly afterwards.
> kb describe pod/lighthouse-575fd6fdd9-7fpts
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned default/lighthouse-6bbdb45f9d-6m8hn to k3s-node1
Normal Pulling 2m9s kubelet, k3s-node1 Pulling image "docker.admantium.com/lighthouse:0.1.9.7"
Normal Pulled 114s kubelet, k3s-node1 Successfully pulled image "docker.admantium.com/lighthouse:0.1.9.7"
Normal Created 114s kubelet, k3s-node1 Created container lighthouse
Normal Started 113s kubelet, k3s-node1 Started container lighthouse
Warning Unhealthy 2s (x2 over 42s) kubelet, k3s-node1 Liveness probe failed: Scan daemon is not running.
Health Check Configuration
The execution of a health check is configured with the following attributes:
initialDelaySecondsDelay in seconds before the first testperiodSecondsPeriod in seconds between checkstimeoutSecondsTime in seconds before the probe is considered failedsuccessThresholdAfter having failed, minimum number of times before the probe is considered successfulfailureThresholdNumber of times the check can fail before Pod is marked unhealthy
Use these values as appropriate to your application.
Controlling Compute Resources
In a Kubernetes cluster, compute resources are finite. Deployed applications consume CPU and memory. It is essential to determine how much resources applications need, and also to monitor how much they consume.
Kubernetes distinguishes resource utilization into requests and limits. Requests are the minimum resources that an application needs to run. Limits are the maximum number of resources. For memory, the default value is 512Mi, for CPU there is no maximum limit. Containers that overconsume CPU will be throttled, and containers that overconsume memory might be terminated - take care to set an appropriate limit.
The resources, and their values, are:
- CPU: The number of CPU cores, expressed in decimal with a fraction, like
0.4or1.0, or as the number of CPU milliseconds a container can use like400mand1000m - Memory: The amount of bytes, expressed as integers with the units Kilo, Mega, Giga, Tera, Peta and Exa (note that Kubernetes prefers to use Mebibyte instead of Megabytes, because the former is based on real multiples of 1024)
To determine the limits, I recommend to do a stress test with your application and measure its resource usage. Then define the average values and use them.
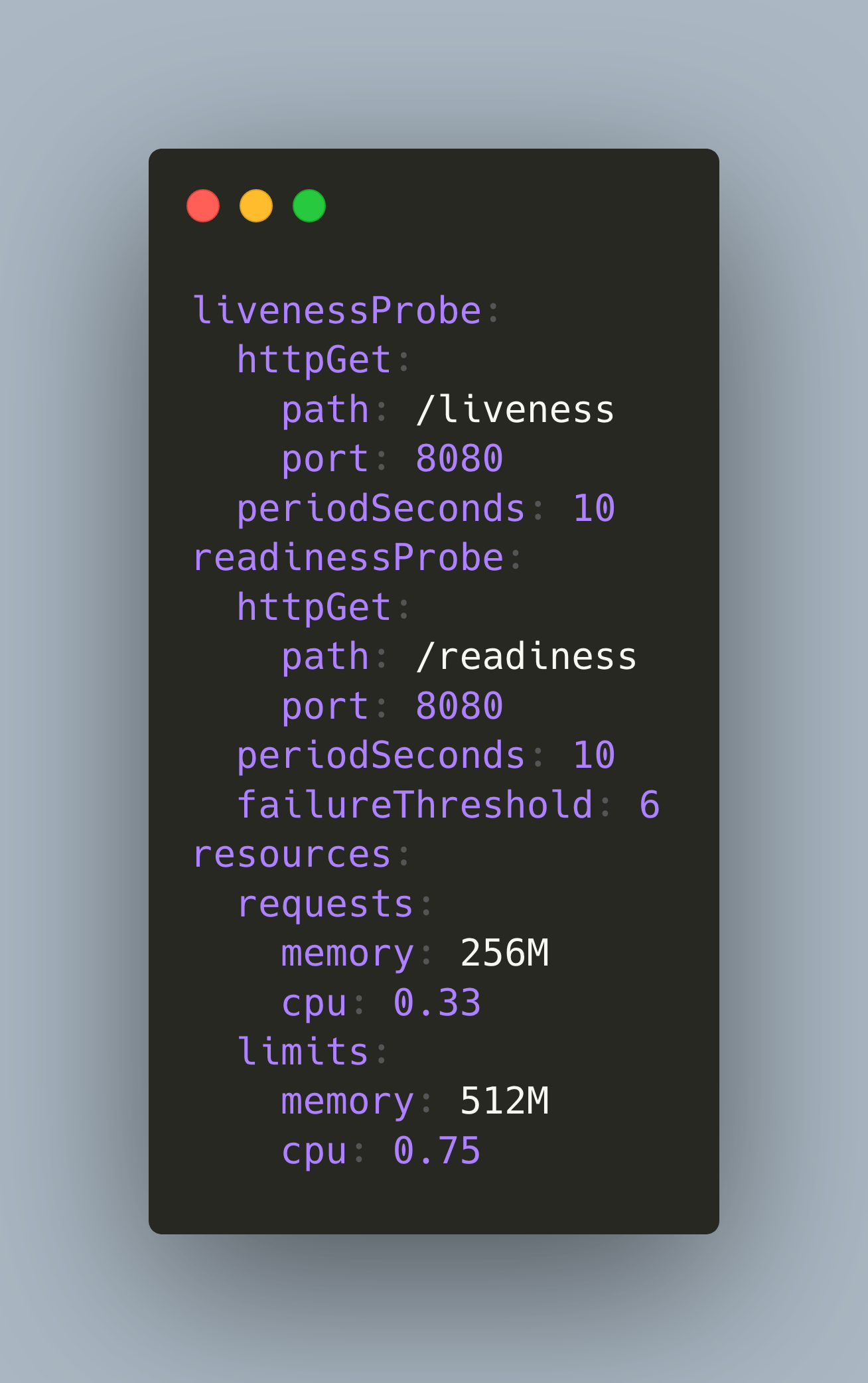
In the following Deployment, I set the request and limit values for my lighthouse containers. For CPU, that’s 0.33 and 0.75, and for memory, that’s 256Mi and 512Mi.
apiVersion: apps/v1
kind: Deployment
metadata:
name: lighthouse
spec:
replicas: 4
selector:
matchLabels:
app: lighthouse
template:
spec:
containers:
- name: lighthouse
image: docker.admantium.com/lighthouse:0.1.9
livenessProbe:
httpGet:
path: /liveness
port: 8080
periodSeconds: 10
readinessProbe:
httpGet:
path: /readiness
port: 8080
periodSeconds: 10
failureThreshold: 6
resources:
requests:
memory: 256M
cpu: 0.33
limits:
memory: 512M
cpu: 0.75
Conclusion
In Kubernetes, health checks, resource requests and resource limits are the essential concepts to ensure stability of your application. Health checks observe the behavior of containers to detect their capability for receiving traffic, and to detect of they are still operational. The most commonly used check type is a HTTP request, so providing a HTTP API for your application is recommended. Resource limits prevents container from accumulating cluster resources, and it also helps to determine leaky containers that spawn child processes that are not properly cleaned up.