
ApiBlaze is a tool to explore API specifications: Search for a keyword, filter for objects, properties, or endpoints, and immediately see descriptions and code examples. ApiBlaze helps you to answer a specific question about an API lightning fast.
ApiBlaze is an ongoing project that went from inception to prototype and two times refinement. This article presents code and visualization of these phases, and explains the reason for the changes.
Inception
The development of ApiBlaze started like so many other projects with a simple npm init in two folders called backend and frontend.
The frontend was a single index.html, a stylesheet and a script.js for simple DOM manipulation. The page layout was very simple: A search bar in which you enter a search term, and a box for displaying the search results.
Here is a picture:
The backend was a simple express app with the default route and port. Through this, the frontend can make a WebSocket connection and load data. We did not implement any search functions, but just figured out how to establish the web socket connection.
When this worked, we started with the development in earnest: Creating user stories, and adding features step-by-step.
Prototype
In the course of about 6 weeks, we implemented the following functions and features:
- Backend: Parse API spec and provide an optimized, internal datamodel for searching
- Frontend: Dispatch and process WebSocket requests for searching in the internal datamodel
- Frontend: Display search results in a popup
- Frontend: Display description and referenced request/response datastructure of the selected element
- Backend: Introduce the concept of clients, store client ID and currently selected API
- Frontend and Backend: Search and select different OpenAP specification
- Frontend: Switch search mode between properties, objects and endpoints, and render search results visually different
Here is a picture of the API elements search page:

This prototype was finished around June. The code base was quite messy. To give you just one example: The code for the search bar. In three different places, the search bar receives a focus, defines event listeners, and registers a web socket event to render the search result… Very hard to figure out where to make changes!
<section class="search-wrapper">
<h2>Search</h2>
<div class="input-wrapper">
<input type="text" id="query" value="" spellcheck="false" />
</div>
...
</section>
$query.focus()
function addCollapses($container) {
...
}
$query.addEventListener('input', event => {
let value = event.target.value
search();
})
socket.on('results', results => {
renderResults(results)
})
function copy(text) {
...
}
$query.addEventListener('keyup', resultsKeyControl)
$query.addEventListener('focus', resultsFocusCheck)
$query.addEventListener('blur', resultsFocusCheck)
The main features were implemented. And then, summer happened, and the project lay dormant for some time.
Modularization
After the long summer break, interests shifted and my friend could no longer contributed to the project. I took torch and continued the development, but was unable to add substential new features because of the code base.
The complete frontend code was contained in just one file, function definitions and function execution intermingled, and the HTML in a different file. Methods with over 100 lines of code were the norm. The DOM structure was overly complicated, and the CSS rules hard to decipher. Adding new features to theis code base was a frustrating experience, and I even considered to abandon the project alltogether.
However, new ideas sparked from an unexpected direction: The great book JavaScript: The Definitive Guide. This book not only sparked my interest in JavaScript, but also fully explained how JavaScript modules in browsers work. And modules were the solution to the main challenge: Seperation of concerns. With modules I could define a single frontend element, like the search bar, and encapsulate the HTML, CSS and JavaScript in one single element. This component-like module has a form like this:
import { handleApiSearch } from '../controller.js'
let state = {}
let _$root = undefined
function updateState (newState) {
state = { ...state, ...newState }
}
function getState () {
return state
}
function render (args) {
const html = `
<h2>Load an API</h2>
<input type="text" class="api-search-bar" id="api-search-bar" value="" spellcheck="false">
<div id="api-search-results" class="api-search-results"></div>
`
return html
}
function mount ($root, ...args) {
_$root = $root
$root.innerHTML = render(args)
document
.getElementById('api-search-bar')
.addEventListener('keyup', e => handleKeyup(e))
}
function refresh (args) {
mount(_$root, args)
}
function handleKeyup (e) {
const keyword = e.target.value
handleApiSearch(keyword, updateState)
}
export { mount, getState, refresh }
And from thereion, I refecatored the complete code base. The frontend consists of a controller module, responsoble for connecting to the backend, for sending and receiving web socket requests. The controller renders pages, which in turn consist of the components. Here is an excerpt from the controller’s source code.
With this refactoring, all components were divided and the application became manageable again.
Framework-Based Design
Following the substantial overhaul during modularization, one thing still bothered me: code duplication. Essentially, each component and page had the same methods included. I could not fathoom a simple solution to extract the duplicate methods into a seperate module, and import from there. So I started to define classes for pages and components - code duplication nicely eliminated, and now each object has a standard interface that I can use. And now, when the controller deals with standardized object, the jump to a framework is not far.
But what is a framework? According to a great Mozilla MDN Article, client-side JavaScript frameworks have four essential features: (i) Abstracting DOM manipulations, (ii) state management, (iii) compartmentalization and (iv) routing. Without actively knowing these features, the codebase I worked on evolved into this direction. So I term the underlying foundations of ApiBase a framework, and designing it gave me great insights. Eventually I came up with React-like vocabularly (methods like render and mount). State management, passing it between components easily, was a nice challenge to track. And I liked to work on the controller, implementing abstractions for easy routing between pages and persisting state in the local storage.
So, ApiBlaze is developed using my custom framework. And with this, the search bar component has the following code structure:
import { Component } from 'spac'
import SearchApiAction from '../actions/SearchApiAction.js'
export default class SearchBarComponent extends Component {
render = () => {
return `
<input type="text" id="api-search-query" value="${this.getState()
.apiSearchQuery || 'Kubernetes'}" spellcheck="false">
`
}
mount () {
super.mount()
document
.querySelector('#api-search-query')
.addEventListener('keyup', e => this.handleKeyUp(e, this))
}
handleKeyUp (e) {
e.preventDefault()
this.updateState({ apiSearchQuery: e.target.value })
this.triggerSearch()
}
async triggerSearch (e) {
const apiList = await new SearchApiAction().run()
this.updateState({ apiList })
}
}
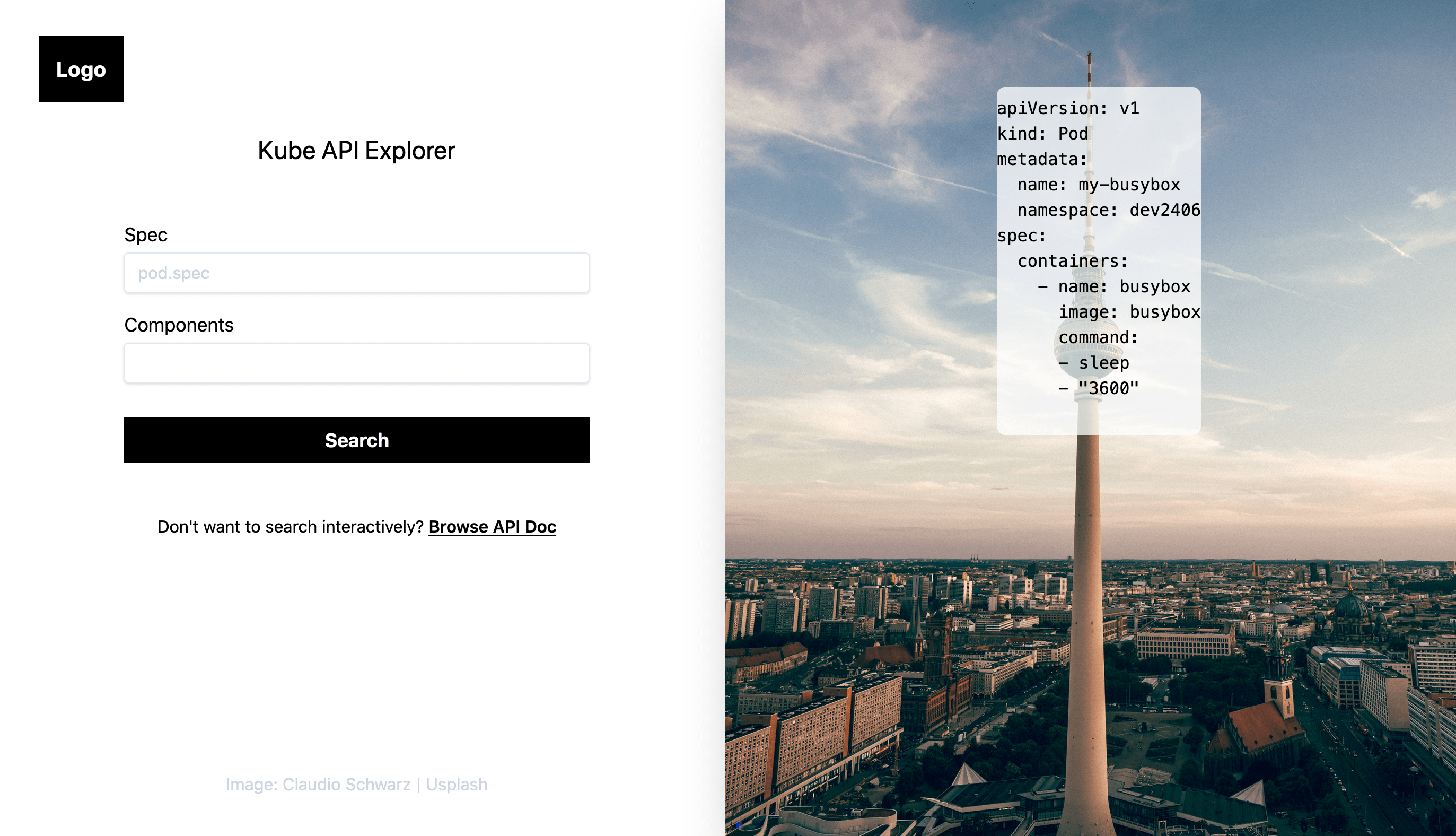
And the layout evolved too:

Conclusion
This article explained the three development phases of ApiBlaze. During inception, we explored how to connect the frontend and backend with WebSockets. In the early prototype, we added the main feature: searching for API elements with immediate update of the UI, displaying the description and foldable data models, and much more. After a long break, the code base was overhauled by me - first to a module based implementation, and then with using classes it evolved to a custom framework. The ApiBlaze blog series will be paused, and I continue with explaining the framework.